 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslateGemma Technical Report
Jan 15, 2026We present TranslateGemma, a suite of open machine translation models based on the Gemma 3 foundation models. To enhance the inherent multilingual capabilities of Gemma 3 for the translation task, we employ a two-stage fine-tuning process. First, supervised fine-tuning is performed using a rich mixture of high-quality large-scale synthetic parallel data generated via state-of-the-art models and human-translated parallel data. This is followed by a reinforcement learning phase, where we optimize translation quality using an ensemble of reward models, including MetricX-QE and AutoMQM, targeting translation quality. We demonstrate the effectiveness of TranslateGemma with human evaluation on the WMT25 test set across 10 language pairs and with automatic evaluation on the WMT24++ benchmark across 55 language pairs. Automatic metrics show consistent and substantial gains over the baseline Gemma 3 models across all sizes. Notably, smaller TranslateGemma models often achieve performance comparable to larger baseline models, offering improved efficiency. We also show that TranslateGemma models retain strong multimodal capabilities, with enhanced performance on the Vistra image translation benchmark. The release of the open TranslateGemma models aims to provide the research community with powerful and adaptable tools for machine translation.
Rethinking Cross-lingual Alignment: Balancing Transfer and Cultural Erasure in Multilingual LLMs
Oct 29, 2025
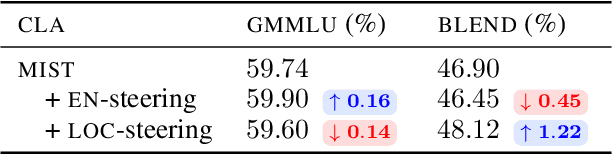
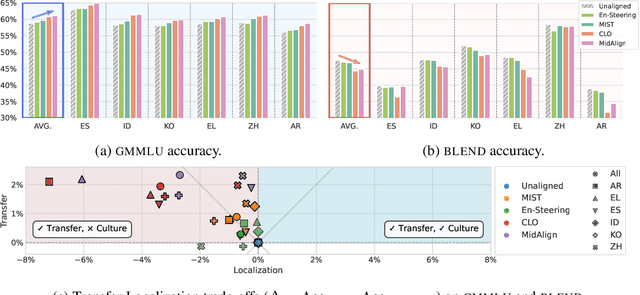
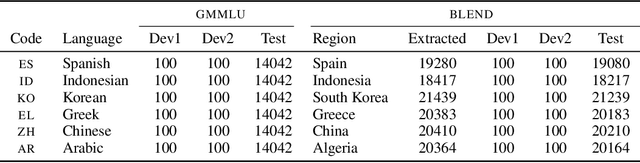
Cross-lingual alignment (CLA) aims to align multilingual representations, enabling Large Language Models (LLMs) to seamlessly transfer knowledge across languages. While intuitive, we hypothesize, this pursuit of representational convergence can inadvertently cause "cultural erasure", the functional loss of providing culturally-situated responses that should diverge based on the query language. In this work, we systematically analyze this trade-off by introducing a holistic evaluation framework, the transfer-localization plane, which quantifies both desirable knowledge transfer and undesirable cultural erasure. Using this framework, we re-evaluate recent CLA approaches and find that they consistently improve factual transfer at the direct cost of cultural localization across all six languages studied. Our investigation into the internal representations of these models reveals a key insight: universal factual transfer and culturally-specific knowledge are optimally steerable at different model layers. Based on this finding, we propose Surgical Steering, a novel inference-time method that disentangles these two objectives. By applying targeted activation steering to distinct layers, our approach achieves a better balance between the two competing dimensions, effectively overcoming the limitations of current alignment techniques.
Deconstructing Self-Bias in LLM-generated Translation Benchmarks
Sep 30, 2025As large language models (LLMs) begin to saturate existing benchmarks, automated benchmark creation using LLMs (LLM as a benchmark) has emerged as a scalable alternative to slow and costly human curation. While these generated test sets have to potential to cheaply rank models, we demonstrate a critical flaw. LLM generated benchmarks systematically favor the model that created the benchmark, they exhibit self bias on low resource languages to English translation tasks. We show three key findings on automatic benchmarking of LLMs for translation: First, this bias originates from two sources: the generated test data (LLM as a testset) and the evaluation method (LLM as an evaluator), with their combination amplifying the effect. Second, self bias in LLM as a benchmark is heavily influenced by the model's generation capabilities in the source language. For instance, we observe more pronounced bias in into English translation, where the model's generation system is developed, than in out of English translation tasks. Third, we observe that low diversity in source text is one attribution to self bias. Our results suggest that improving the diversity of these generated source texts can mitigate some of the observed self bias.
Déjà Vu: Multilingual LLM Evaluation through the Lens of Machine Translation Evaluation
Apr 16, 2025Generation capabilities and language coverage of multilingual large language models (mLLMs) are advancing rapidly. However, evaluation practices for generative abilities of mLLMs are still lacking comprehensiveness, scientific rigor, and consistent adoption across research labs, which undermines their potential to meaningfully guide mLLM development. We draw parallels with machine translation (MT) evaluation, a field that faced similar challenges and has, over decades, developed transparent reporting standards and reliable evaluations for multilingual generative models. Through targeted experiments across key stages of the generative evaluation pipeline, we demonstrate how best practices from MT evaluation can deepen the understanding of quality differences between models. Additionally, we identify essential components for robust meta-evaluation of mLLMs, ensuring the evaluation methods themselves are rigorously assessed. We distill these insights into a checklist of actionable recommendations for mLLM research and development.
Multilingual Contextualization of Large Language Models for Document-Level Machine Translation
Apr 16, 2025

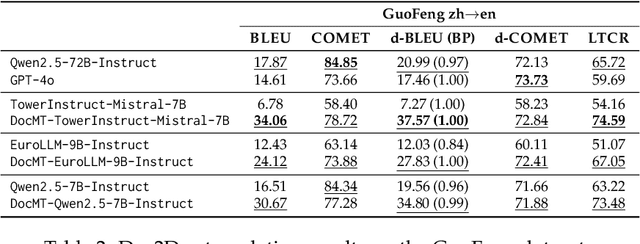
Large language models (LLMs) have demonstrated strong performance in sentence-level machine translation, but scaling to document-level translation remains challenging, particularly in modeling long-range dependencies and discourse phenomena across sentences and paragraphs. In this work, we propose a method to improve LLM-based long-document translation through targeted fine-tuning on high-quality document-level data, which we curate and introduce as DocBlocks. Our approach supports multiple translation paradigms, including direct document-to-document and chunk-level translation, by integrating instructions both with and without surrounding context. This enables models to better capture cross-sentence dependencies while maintaining strong sentence-level translation performance. Experimental results show that incorporating multiple translation paradigms improves document-level translation quality and inference speed compared to prompting and agent-based methods.
Do LLMs Understand Your Translations? Evaluating Paragraph-level MT with Question Answering
Apr 10, 2025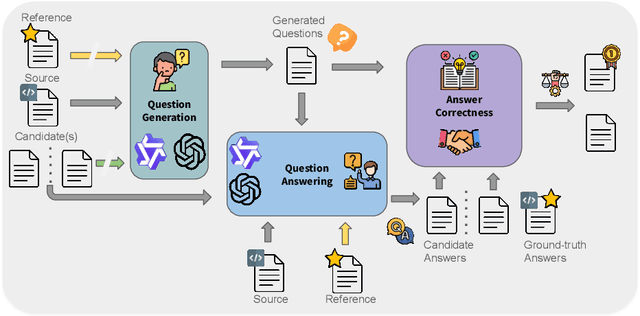
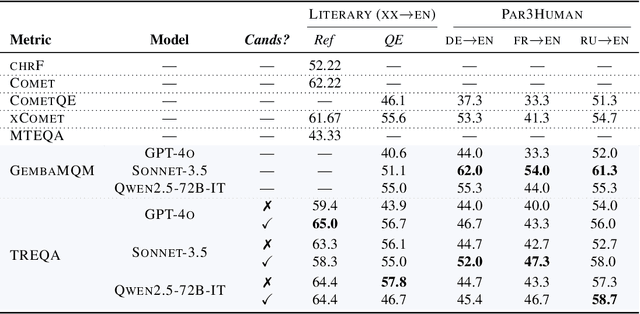

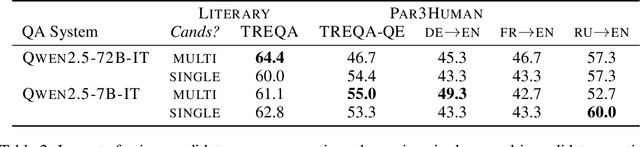
Despite the steady progress in machine translation evaluation, existing automatic metrics struggle to capture how well meaning is preserved beyond sentence boundaries. We posit that reliance on a single intrinsic quality score, trained to mimic human judgments, might be insufficient for evaluating translations of long, complex passages, and a more ``pragmatic'' approach that assesses how accurately key information is conveyed by a translation in context is needed. We introduce TREQA (Translation Evaluation via Question-Answering), a framework that extrinsically evaluates translation quality by assessing how accurately candidate translations answer reading comprehension questions that target key information in the original source or reference texts. In challenging domains that require long-range understanding, such as literary texts, we show that TREQA is competitive with and, in some cases, outperforms state-of-the-art neural and LLM-based metrics in ranking alternative paragraph-level translations, despite never being explicitly optimized to correlate with human judgments. Furthermore, the generated questions and answers offer interpretability: empirical analysis shows that they effectively target translation errors identified by experts in evaluated datasets. Our code is available at https://github.com/deep-spin/treqa
Translate Smart, not Hard: Cascaded Translation Systems with Quality-Aware Deferral
Feb 18, 2025Larger models often outperform smaller ones but come with high computational costs. Cascading offers a potential solution. By default, it uses smaller models and defers only some instances to larger, more powerful models. However, designing effective deferral rules remains a challenge. In this paper, we propose a simple yet effective approach for machine translation, using existing quality estimation (QE) metrics as deferral rules. We show that QE-based deferral allows a cascaded system to match the performance of a larger model while invoking it for a small fraction (30% to 50%) of the examples, significantly reducing computational costs. We validate this approach through both automatic and human evaluation.
Optimization Landscapes Learned: Proxy Networks Boost Convergence in Physics-based Inverse Problems
Jan 27, 2025Solving inverse problems in physics is central to understanding complex systems and advancing technologies in various fields. Iterative optimization algorithms, commonly used to solve these problems, often encounter local minima, chaos, or regions with zero gradients. This is due to their overreliance on local information and highly chaotic inverse loss landscapes governed by underlying partial differential equations (PDEs). In this work, we show that deep neural networks successfully replicate such complex loss landscapes through spatio-temporal trajectory inputs. They also offer the potential to control the underlying complexity of these chaotic loss landscapes during training through various regularization methods. We show that optimizing on network-smoothened loss landscapes leads to improved convergence in predicting optimum inverse parameters over conventional momentum-based optimizers such as BFGS on multiple challenging problems.
A Context-aware Framework for Translation-mediated Conversations
Dec 05, 2024Effective communication is fundamental to any interaction, yet challenges arise when participants do not share a common language. Automatic translation systems offer a powerful solution to bridge language barriers in such scenarios, but they introduce errors that can lead to misunderstandings and conversation breakdown. A key issue is that current systems fail to incorporate the rich contextual information necessary to resolve ambiguities and omitted details, resulting in literal, inappropriate, or misaligned translations. In this work, we present a framework to improve large language model-based translation systems by incorporating contextual information in bilingual conversational settings. During training, we leverage context-augmented parallel data, which allows the model to generate translations sensitive to conversational history. During inference, we perform quality-aware decoding with context-aware metrics to select the optimal translation from a pool of candidates. We validate both components of our framework on two task-oriented domains: customer chat and user-assistant interaction. Across both settings, our framework consistently results in better translations than state-of-the-art systems like GPT-4o and TowerInstruct, as measured by multiple automatic translation quality metrics on several language pairs. We also show that the resulting model leverages context in an intended and interpretable way, improving consistency between the conveyed message and the generated translations.
Fine-Grained Reward Optimization for Machine Translation using Error Severity Mappings
Nov 08, 2024
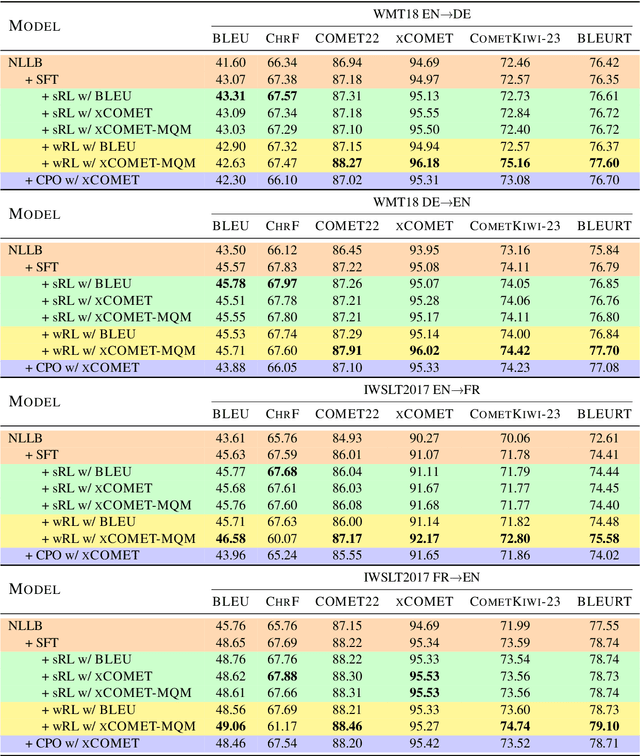
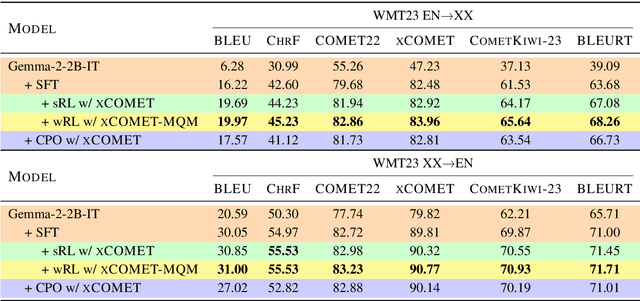
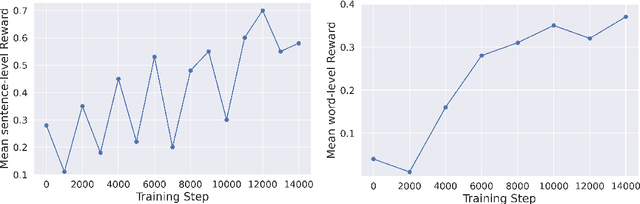
Reinforcement learning (RL) has been proven to be an effective and robust method for training neural machine translation systems, especially when paired with powerful reward models that accurately assess translation quality. However, most research has focused on RL methods that use sentence-level feedback, which leads to inefficient learning signals due to the reward sparsity problem -- the model receives a single score for the entire sentence. To address this, we introduce a novel approach that leverages fine-grained token-level reward mechanisms with RL methods. We use xCOMET, a state-of-the-art quality estimation system as our token-level reward model. xCOMET provides detailed feedback by predicting fine-grained error spans and their severity given source-translation pairs. We conduct experiments on small and large translation datasets to compare the impact of sentence-level versus fine-grained reward signals on translation quality. Our results show that training with token-level rewards improves translation quality across language pairs over baselines according to automatic and human evaluation. Furthermore, token-level reward optimization also improves training stability, evidenced by a steady increase in mean rewards over training epochs.