 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatching the Watchers: Exposing Gender Disparities in Machine Translation Quality Estimation
Paper and Code
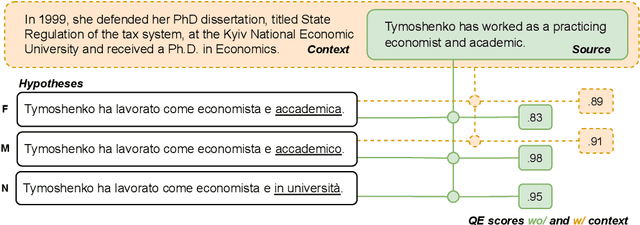

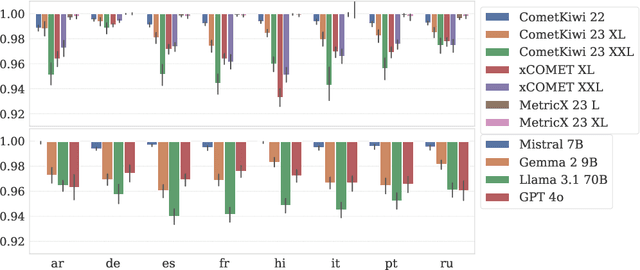

The automatic assessment of translation quality has recently become crucial for many stages of the translation pipeline, from data curation to training and decoding. However, while quality estimation metrics have been optimized to align with human judgments, no attention has been given to these metrics' potential biases, particularly in reinforcing visibility and usability for some demographic groups over others. This paper is the first to investigate gender bias in quality estimation (QE) metrics and its downstream impact on machine translation (MT). We focus on out-of-English translations where the target language uses grammatical gender. We ask: (RQ1) Do contemporary QE metrics exhibit gender bias? (RQ2) Can the use of contextual information mitigate this bias? (RQ3) How does QE influence gender bias in MT outputs? Experiments with state-of-the-art QE metrics across multiple domains, datasets, and languages reveal significant bias. Masculine-inflected translations score higher than feminine-inflected ones, and gender-neutral translations are penalized. Moreover, context-aware QE metrics reduce errors for masculine-inflected references but fail to address feminine referents, exacerbating gender disparities. Additionally, we show that QE metrics can perpetuate gender bias in MT systems when used in quality-aware decoding. Our findings highlight the need to address gender bias in QE metrics to ensure equitable and unbiased MT systems.