 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEuroLLM-22B: Technical Report
Feb 05, 2026This report presents EuroLLM-22B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-22B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. Across a broad set of multilingual benchmarks, EuroLLM-22B demonstrates strong performance in reasoning, instruction following, and translation, achieving results competitive with models of comparable size. To support future research, we release our base and instruction-tuned models, our multilingual web pretraining data and updated EuroBlocks instruction datasets, as well as our pre-training and evaluation codebases.
Teaching Language Models to Faithfully Express their Uncertainty
Oct 14, 2025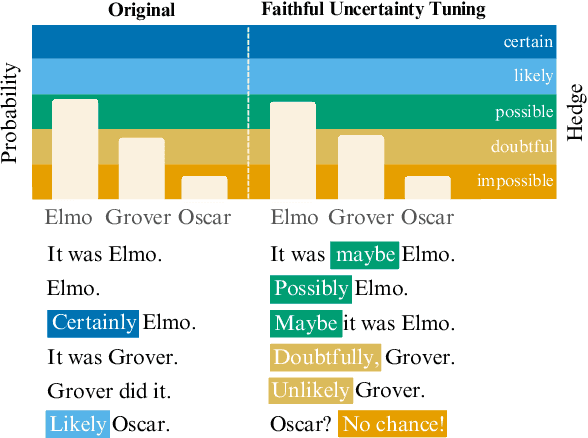
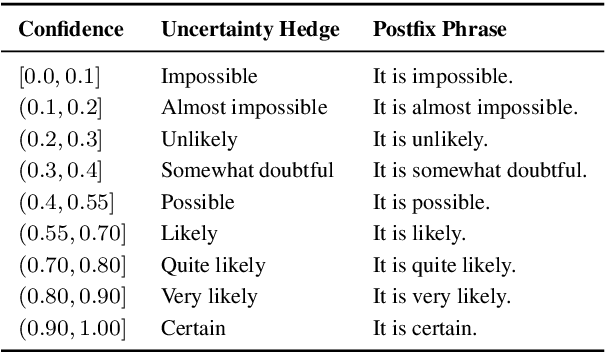
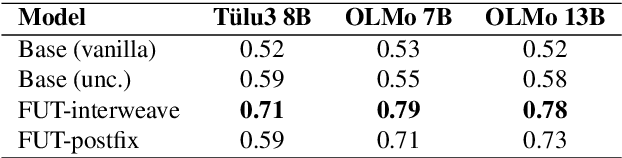
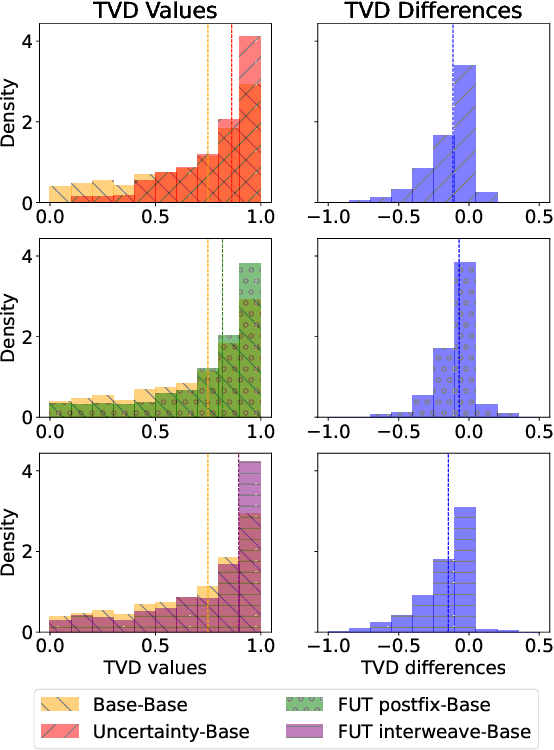
Large language models (LLMs) often miscommunicate their uncertainty: repeated queries can produce divergent answers, yet generated responses are typically unhedged or hedged in ways that do not reflect this variability. This conveys unfaithful information about the uncertain state of the LLMs' knowledge, creating a faithfulness gap that affects even strong LLMs. We introduce Faithful Uncertainty Tuning (FUT): a fine-tuning approach that teaches instruction-tuned LLMs to express uncertainty faithfully without altering their underlying answer distribution. We construct training data by augmenting model samples with uncertainty hedges (i.e. verbal cues such as 'possibly' or 'likely') aligned with sample consistency, requiring no supervision beyond the model and a set of prompts. We evaluate FUT on open-domain question answering (QA) across multiple models and datasets. Our results show that FUT substantially reduces the faithfulness gap, while preserving QA accuracy and introducing minimal semantic distribution shift. Further analyses demonstrate robustness across decoding strategies, choice of hedgers, and other forms of uncertainty expression (i.e. numerical). These findings establish FUT as a simple and effective way to teach LLMs to communicate uncertainty faithfully.
EuroLLM-9B: Technical Report
Jun 04, 2025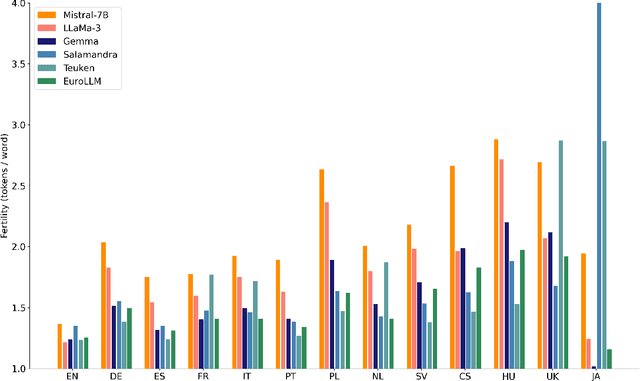
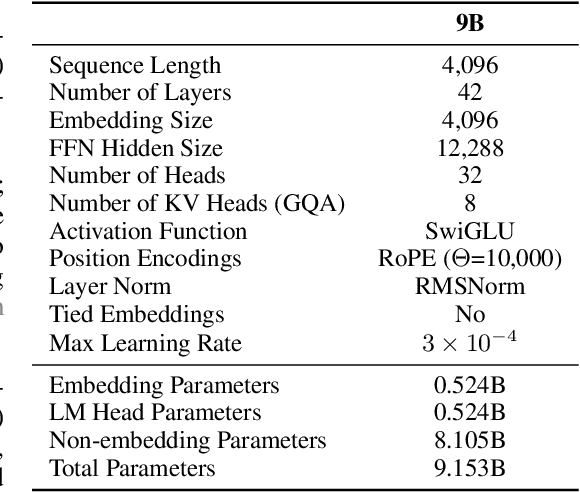
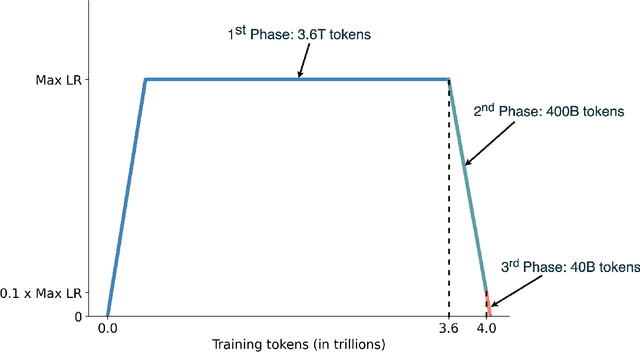
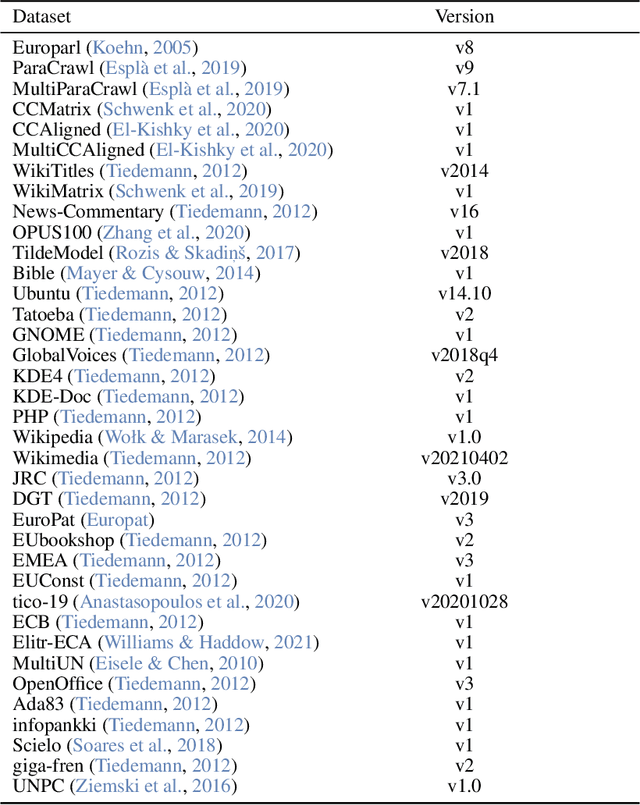
This report presents EuroLLM-9B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-9B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. We describe the pre-training data collection and filtering pipeline, including the creation of EuroFilter, an AI-based multilingual filter, as well as the design of EuroBlocks-Synthetic, a novel synthetic dataset for post-training that enhances language coverage for European languages. Evaluation results demonstrate EuroLLM-9B's competitive performance on multilingual benchmarks and machine translation tasks, establishing it as the leading open European-made LLM of its size. To support open research and adoption, we release all major components of this work, including the base and instruction-tuned models, the EuroFilter classifier, and the synthetic post-training dataset.
Findings of the WMT 2024 Shared Task on Chat Translation
Oct 15, 2024



This paper presents the findings from the third edition of the Chat Translation Shared Task. As with previous editions, the task involved translating bilingual customer support conversations, specifically focusing on the impact of conversation context in translation quality and evaluation. We also include two new language pairs: English-Korean and English-Dutch, in addition to the set of language pairs from previous editions: English-German, English-French, and English-Brazilian Portuguese. We received 22 primary submissions and 32 contrastive submissions from eight teams, with each language pair having participation from at least three teams. We evaluated the systems comprehensively using both automatic metrics and human judgments via a direct assessment framework. The official rankings for each language pair were determined based on human evaluation scores, considering performance in both translation directions--agent and customer. Our analysis shows that while the systems excelled at translating individual turns, there is room for improvement in overall conversation-level translation quality.
Modeling User Preferences with Automatic Metrics: Creating a High-Quality Preference Dataset for Machine Translation
Oct 10, 2024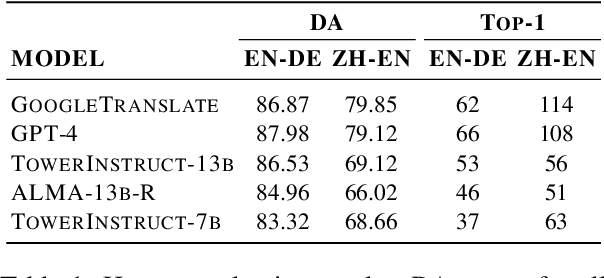

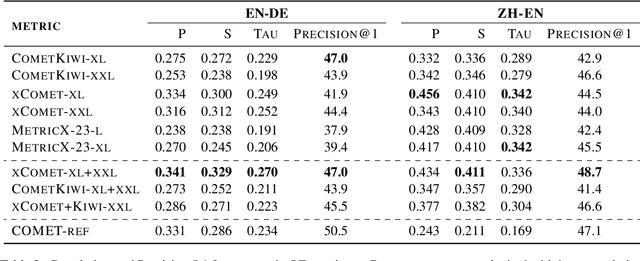
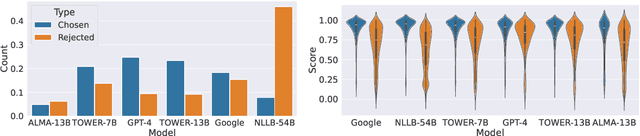
Alignment with human preferences is an important step in developing accurate and safe large language models. This is no exception in machine translation (MT), where better handling of language nuances and context-specific variations leads to improved quality. However, preference data based on human feedback can be very expensive to obtain and curate at a large scale. Automatic metrics, on the other hand, can induce preferences, but they might not match human expectations perfectly. In this paper, we propose an approach that leverages the best of both worlds. We first collect sentence-level quality assessments from professional linguists on translations generated by multiple high-quality MT systems and evaluate the ability of current automatic metrics to recover these preferences. We then use this analysis to curate a new dataset, MT-Pref (metric induced translation preference) dataset, which comprises 18k instances covering 18 language directions, using texts sourced from multiple domains post-2022. We show that aligning TOWER models on MT-Pref significantly improves translation quality on WMT23 and FLORES benchmarks.
EuroLLM: Multilingual Language Models for Europe
Sep 24, 2024The quality of open-weight LLMs has seen significant improvement, yet they remain predominantly focused on English. In this paper, we introduce the EuroLLM project, aimed at developing a suite of open-weight multilingual LLMs capable of understanding and generating text in all official European Union languages, as well as several additional relevant languages. We outline the progress made to date, detailing our data collection and filtering process, the development of scaling laws, the creation of our multilingual tokenizer, and the data mix and modeling configurations. Additionally, we release our initial models: EuroLLM-1.7B and EuroLLM-1.7B-Instruct and report their performance on multilingual general benchmarks and machine translation.
QUEST: Quality-Aware Metropolis-Hastings Sampling for Machine Translation
May 28, 2024An important challenge in machine translation (MT) is to generate high-quality and diverse translations. Prior work has shown that the estimated likelihood from the MT model correlates poorly with translation quality. In contrast, quality evaluation metrics (such as COMET or BLEURT) exhibit high correlations with human judgments, which has motivated their use as rerankers (such as quality-aware and minimum Bayes risk decoding). However, relying on a single translation with high estimated quality increases the chances of "gaming the metric''. In this paper, we address the problem of sampling a set of high-quality and diverse translations. We provide a simple and effective way to avoid over-reliance on noisy quality estimates by using them as the energy function of a Gibbs distribution. Instead of looking for a mode in the distribution, we generate multiple samples from high-density areas through the Metropolis-Hastings algorithm, a simple Markov chain Monte Carlo approach. The results show that our proposed method leads to high-quality and diverse outputs across multiple language pairs (English$\leftrightarrow${German, Russian}) with two strong decoder-only LLMs (Alma-7b, Tower-7b).
Tower: An Open Multilingual Large Language Model for Translation-Related Tasks
Feb 27, 2024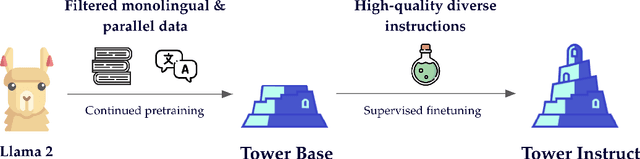



While general-purpose large language models (LLMs) demonstrate proficiency on multiple tasks within the domain of translation, approaches based on open LLMs are competitive only when specializing on a single task. In this paper, we propose a recipe for tailoring LLMs to multiple tasks present in translation workflows. We perform continued pretraining on a multilingual mixture of monolingual and parallel data, creating TowerBase, followed by finetuning on instructions relevant for translation processes, creating TowerInstruct. Our final model surpasses open alternatives on several tasks relevant to translation workflows and is competitive with general-purpose closed LLMs. To facilitate future research, we release the Tower models, our specialization dataset, an evaluation framework for LLMs focusing on the translation ecosystem, and a collection of model generations, including ours, on our benchmark.
Steering Large Language Models for Machine Translation with Finetuning and In-Context Learning
Oct 20, 2023Large language models (LLMs) are a promising avenue for machine translation (MT). However, current LLM-based MT systems are brittle: their effectiveness highly depends on the choice of few-shot examples and they often require extra post-processing due to overgeneration. Alternatives such as finetuning on translation instructions are computationally expensive and may weaken in-context learning capabilities, due to overspecialization. In this paper, we provide a closer look at this problem. We start by showing that adapter-based finetuning with LoRA matches the performance of traditional finetuning while reducing the number of training parameters by a factor of 50. This method also outperforms few-shot prompting and eliminates the need for post-processing or in-context examples. However, we show that finetuning generally degrades few-shot performance, hindering adaptation capabilities. Finally, to obtain the best of both worlds, we propose a simple approach that incorporates few-shot examples during finetuning. Experiments on 10 language pairs show that our proposed approach recovers the original few-shot capabilities while keeping the added benefits of finetuning.
An Empirical Study of Translation Hypothesis Ensembling with Large Language Models
Oct 17, 2023



Large language models (LLMs) are becoming a one-fits-many solution, but they sometimes hallucinate or produce unreliable output. In this paper, we investigate how hypothesis ensembling can improve the quality of the generated text for the specific problem of LLM-based machine translation. We experiment with several techniques for ensembling hypotheses produced by LLMs such as ChatGPT, LLaMA, and Alpaca. We provide a comprehensive study along multiple dimensions, including the method to generate hypotheses (multiple prompts, temperature-based sampling, and beam search) and the strategy to produce the final translation (instruction-based, quality-based reranking, and minimum Bayes risk (MBR) decoding). Our results show that MBR decoding is a very effective method, that translation quality can be improved using a small number of samples, and that instruction tuning has a strong impact on the relation between the diversity of the hypotheses and the sampling temperature.