 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexCOMET: Transparent Machine Translation Evaluation through Fine-grained Error Detection
Oct 16, 2023Widely used learned metrics for machine translation evaluation, such as COMET and BLEURT, estimate the quality of a translation hypothesis by providing a single sentence-level score. As such, they offer little insight into translation errors (e.g., what are the errors and what is their severity). On the other hand, generative large language models (LLMs) are amplifying the adoption of more granular strategies to evaluation, attempting to detail and categorize translation errors. In this work, we introduce xCOMET, an open-source learned metric designed to bridge the gap between these approaches. xCOMET integrates both sentence-level evaluation and error span detection capabilities, exhibiting state-of-the-art performance across all types of evaluation (sentence-level, system-level, and error span detection). Moreover, it does so while highlighting and categorizing error spans, thus enriching the quality assessment. We also provide a robustness analysis with stress tests, and show that xCOMET is largely capable of identifying localized critical errors and hallucinations.
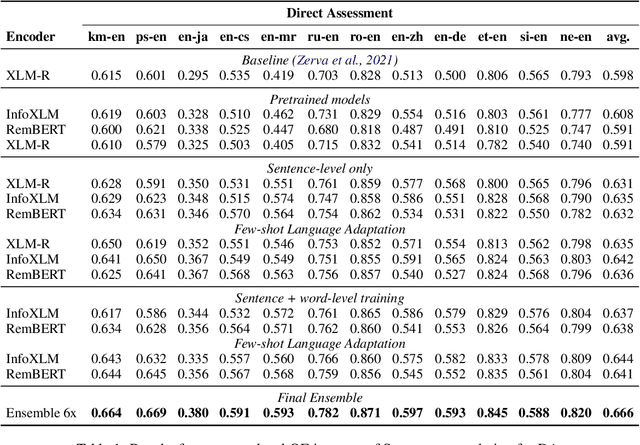
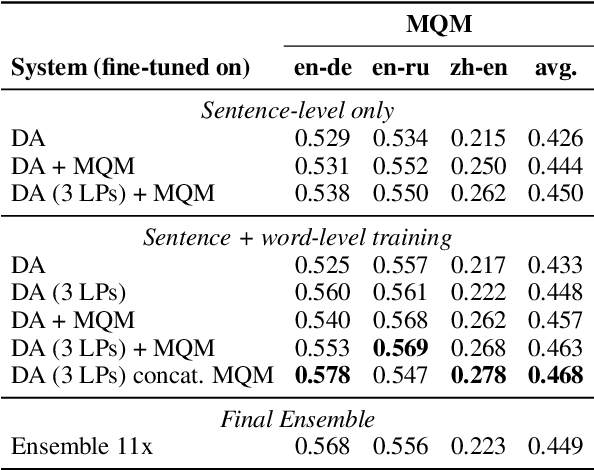
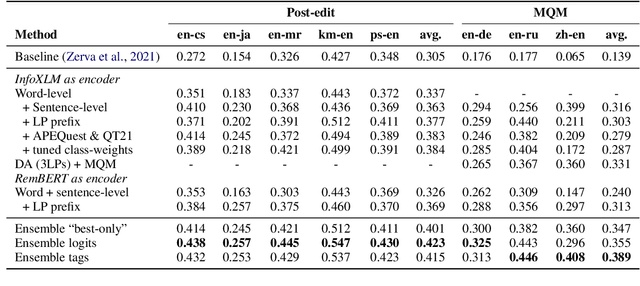
Scaling up COMETKIWI: Unbabel-IST 2023 Submission for the Quality Estimation Shared Task
Sep 21, 2023



We present the joint contribution of Unbabel and Instituto Superior T\'ecnico to the WMT 2023 Shared Task on Quality Estimation (QE). Our team participated on all tasks: sentence- and word-level quality prediction (task 1) and fine-grained error span detection (task 2). For all tasks, we build on the COMETKIWI-22 model (Rei et al., 2022b). Our multilingual approaches are ranked first for all tasks, reaching state-of-the-art performance for quality estimation at word-, span- and sentence-level granularity. Compared to the previous state-of-the-art COMETKIWI-22, we show large improvements in correlation with human judgements (up to 10 Spearman points). Moreover, we surpass the second-best multilingual submission to the shared-task with up to 3.8 absolute points.
Fuzzy Fingerprinting Transformer Language-Models for Emotion Recognition in Conversations
Sep 08, 2023Fuzzy Fingerprints have been successfully used as an interpretable text classification technique, but, like most other techniques, have been largely surpassed in performance by Large Pre-trained Language Models, such as BERT or RoBERTa. These models deliver state-of-the-art results in several Natural Language Processing tasks, namely Emotion Recognition in Conversations (ERC), but suffer from the lack of interpretability and explainability. In this paper, we propose to combine the two approaches to perform ERC, as a means to obtain simpler and more interpretable Large Language Models-based classifiers. We propose to feed the utterances and their previous conversational turns to a pre-trained RoBERTa, obtaining contextual embedding utterance representations, that are then supplied to an adapted Fuzzy Fingerprint classification module. We validate our approach on the widely used DailyDialog ERC benchmark dataset, in which we obtain state-of-the-art level results using a much lighter model.
Towards a Fully Unsupervised Framework for Intent Induction in Customer Support Dialogues
Jul 28, 2023State of the art models in intent induction require annotated datasets. However, annotating dialogues is time-consuming, laborious and expensive. In this work, we propose a completely unsupervised framework for intent induction within a dialogue. In addition, we show how pre-processing the dialogue corpora can improve results. Finally, we show how to extract the dialogue flows of intentions by investigating the most common sequences. Although we test our work in the MultiWOZ dataset, the fact that this framework requires no prior knowledge make it applicable to any possible use case, making it very relevant to real world customer support applications across industry.
Enhancing Portuguese Sign Language Animation with Dynamic Timing and Mouthing
Jul 12, 2023Current signing avatars are often described as unnatural as they cannot accurately reproduce all the subtleties of synchronized body behaviors of a human signer. In this paper, we propose a new dynamic approach for transitions between signs, focusing on mouthing animations for Portuguese Sign Language. Although native signers preferred animations with dynamic transitions, we did not find significant differences in comprehension and perceived naturalness scores. On the other hand, we show that including mouthing behaviors improved comprehension and perceived naturalness for novice sign language learners. Results have implications in computational linguistics, human-computer interaction, and synthetic animation of signing avatars.
The Inside Story: Towards Better Understanding of Machine Translation Neural Evaluation Metrics
May 19, 2023Neural metrics for machine translation evaluation, such as COMET, exhibit significant improvements in their correlation with human judgments, as compared to traditional metrics based on lexical overlap, such as BLEU. Yet, neural metrics are, to a great extent, "black boxes" returning a single sentence-level score without transparency about the decision-making process. In this work, we develop and compare several neural explainability methods and demonstrate their effectiveness for interpreting state-of-the-art fine-tuned neural metrics. Our study reveals that these metrics leverage token-level information that can be directly attributed to translation errors, as assessed through comparison of token-level neural saliency maps with Multidimensional Quality Metrics (MQM) annotations and with synthetically-generated critical translation errors. To ease future research, we release our code at: https://github.com/Unbabel/COMET/tree/explainable-metrics.
Using Implicit Feedback to Improve Question Generation
Apr 26, 2023



Question Generation (QG) is a task of Natural Language Processing (NLP) that aims at automatically generating questions from text. Many applications can benefit from automatically generated questions, but often it is necessary to curate those questions, either by selecting or editing them. This task is informative on its own, but it is typically done post-generation, and, thus, the effort is wasted. In addition, most existing systems cannot incorporate this feedback back into them easily. In this work, we present a system, GEN, that learns from such (implicit) feedback. Following a pattern-based approach, it takes as input a small set of sentence/question pairs and creates patterns which are then applied to new unseen sentences. Each generated question, after being corrected by the user, is used as a new seed in the next iteration, so more patterns are created each time. We also take advantage of the corrections made by the user to score the patterns and therefore rank the generated questions. Results show that GEN is able to improve by learning from both levels of implicit feedback when compared to the version with no learning, considering the top 5, 10, and 20 questions. Improvements go up from 10%, depending on the metric and strategy used.
CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task
Sep 13, 2022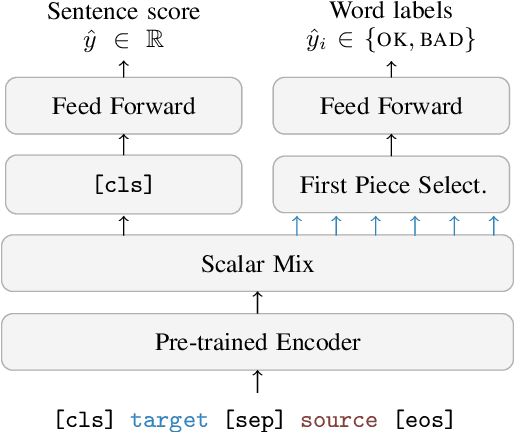
We present the joint contribution of IST and Unbabel to the WMT 2022 Shared Task on Quality Estimation (QE). Our team participated on all three subtasks: (i) Sentence and Word-level Quality Prediction; (ii) Explainable QE; and (iii) Critical Error Detection. For all tasks we build on top of the COMET framework, connecting it with the predictor-estimator architecture of OpenKiwi, and equipping it with a word-level sequence tagger and an explanation extractor. Our results suggest that incorporating references during pretraining improves performance across several language pairs on downstream tasks, and that jointly training with sentence and word-level objectives yields a further boost. Furthermore, combining attention and gradient information proved to be the top strategy for extracting good explanations of sentence-level QE models. Overall, our submissions achieved the best results for all three tasks for almost all language pairs by a considerable margin.
Towards a Sentiment-Aware Conversational Agent
Jul 24, 2022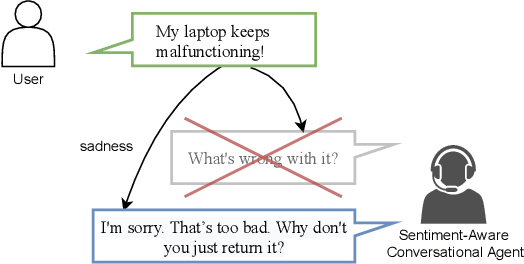

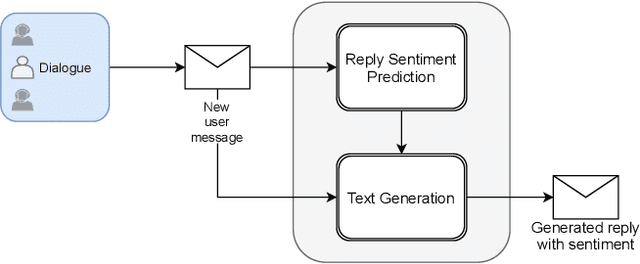
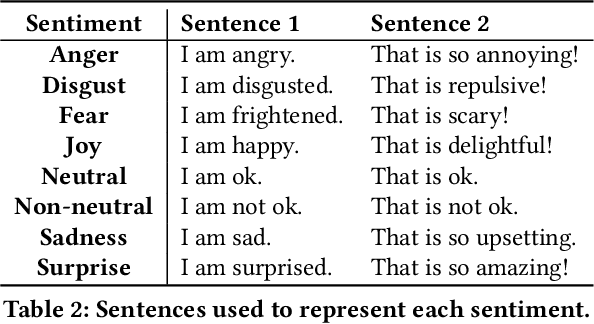
In this paper, we propose an end-to-end sentiment-aware conversational agent based on two models: a reply sentiment prediction model, which leverages the context of the dialogue to predict an appropriate sentiment for the agent to express in its reply; and a text generation model, which is conditioned on the predicted sentiment and the context of the dialogue, to produce a reply that is both context and sentiment appropriate. Additionally, we propose to use a sentiment classification model to evaluate the sentiment expressed by the agent during the development of the model. This allows us to evaluate the agent in an automatic way. Both automatic and human evaluation results show that explicitly guiding the text generation model with a pre-defined set of sentences leads to clear improvements, both regarding the expressed sentiment and the quality of the generated text.
Onception: Active Learning with Expert Advice for Real World Machine Translation
Mar 12, 2022


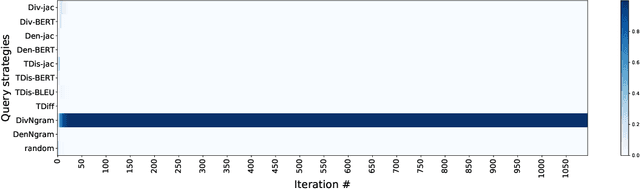
Active learning can play an important role in low-resource settings (i.e., where annotated data is scarce), by selecting which instances may be more worthy to annotate. Most active learning approaches for Machine Translation assume the existence of a pool of sentences in a source language, and rely on human annotators to provide translations or post-edits, which can still be costly. In this article, we assume a real world human-in-the-loop scenario in which: (i) the source sentences may not be readily available, but instead arrive in a stream; (ii) the automatic translations receive feedback in the form of a rating, instead of a correct/edited translation, since the human-in-the-loop might be a user looking for a translation, but not be able to provide one. To tackle the challenge of deciding whether each incoming pair source-translations is worthy to query for human feedback, we resort to a number of stream-based active learning query strategies. Moreover, since we not know in advance which query strategy will be the most adequate for a certain language pair and set of Machine Translation models, we propose to dynamically combine multiple strategies using prediction with expert advice. Our experiments show that using active learning allows to converge to the best Machine Translation systems with fewer human interactions. Furthermore, combining multiple strategies using prediction with expert advice often outperforms several individual active learning strategies with even fewer interactions.