 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropic Risk-Aware Monte Carlo Tree Search
Jan 25, 2026We propose a provably correct Monte Carlo tree search (MCTS) algorithm for solving \textit{risk-aware} Markov decision processes (MDPs) with \textit{entropic risk measure} (ERM) objectives. We provide a \textit{non-asymptotic} analysis of our proposed algorithm, showing that the algorithm: (i) is \textit{correct} in the sense that the empirical ERM obtained at the root node converges to the optimal ERM; and (ii) enjoys \textit{polynomial regret concentration}. Our algorithm successfully exploits the dynamic programming formulations for solving risk-aware MDPs with ERM objectives introduced by previous works in the context of an upper confidence bound-based tree search algorithm. Finally, we provide a set of illustrative experiments comparing our risk-aware MCTS method against relevant baselines.
Solving General-Utility Markov Decision Processes in the Single-Trial Regime with Online Planning
May 21, 2025In this work, we contribute the first approach to solve infinite-horizon discounted general-utility Markov decision processes (GUMDPs) in the single-trial regime, i.e., when the agent's performance is evaluated based on a single trajectory. First, we provide some fundamental results regarding policy optimization in the single-trial regime, investigating which class of policies suffices for optimality, casting our problem as a particular MDP that is equivalent to our original problem, as well as studying the computational hardness of policy optimization in the single-trial regime. Second, we show how we can leverage online planning techniques, in particular a Monte-Carlo tree search algorithm, to solve GUMDPs in the single-trial regime. Third, we provide experimental results showcasing the superior performance of our approach in comparison to relevant baselines.
Implicit Repair with Reinforcement Learning in Emergent Communication
Feb 18, 2025Conversational repair is a mechanism used to detect and resolve miscommunication and misinformation problems when two or more agents interact. One particular and underexplored form of repair in emergent communication is the implicit repair mechanism, where the interlocutor purposely conveys the desired information in such a way as to prevent misinformation from any other interlocutor. This work explores how redundancy can modify the emergent communication protocol to continue conveying the necessary information to complete the underlying task, even with additional external environmental pressures such as noise. We focus on extending the signaling game, called the Lewis Game, by adding noise in the communication channel and inputs received by the agents. Our analysis shows that agents add redundancy to the transmitted messages as an outcome to prevent the negative impact of noise on the task success. Additionally, we observe that the emerging communication protocol's generalization capabilities remain equivalent to architectures employed in simpler games that are entirely deterministic. Additionally, our method is the only one suitable for producing robust communication protocols that can handle cases with and without noise while maintaining increased generalization performance levels.
Distributed Value Decomposition Networks with Networked Agents
Feb 11, 2025



We investigate the problem of distributed training under partial observability, whereby cooperative multi-agent reinforcement learning agents (MARL) maximize the expected cumulative joint reward. We propose distributed value decomposition networks (DVDN) that generate a joint Q-function that factorizes into agent-wise Q-functions. Whereas the original value decomposition networks rely on centralized training, our approach is suitable for domains where centralized training is not possible and agents must learn by interacting with the physical environment in a decentralized manner while communicating with their peers. DVDN overcomes the need for centralized training by locally estimating the shared objective. We contribute with two innovative algorithms, DVDN and DVDN (GT), for the heterogeneous and homogeneous agents settings respectively. Empirically, both algorithms approximate the performance of value decomposition networks, in spite of the information loss during communication, as demonstrated in ten MARL tasks in three standard environments.
Networked Agents in the Dark: Team Value Learning under Partial Observability
Jan 15, 2025



We propose a novel cooperative multi-agent reinforcement learning (MARL) approach for networked agents. In contrast to previous methods that rely on complete state information or joint observations, our agents must learn how to reach shared objectives under partial observability. During training, they collect individual rewards and approximate a team value function through local communication, resulting in cooperative behavior. To describe our problem, we introduce the networked dynamic partially observable Markov game framework, where agents communicate over a switching topology communication network. Our distributed method, DNA-MARL, uses a consensus mechanism for local communication and gradient descent for local computation. DNA-MARL increases the range of the possible applications of networked agents, being well-suited for real world domains that impose privacy and where the messages may not reach their recipients. We evaluate DNA-MARL across benchmark MARL scenarios. Our results highlight the superior performance of DNA-MARL over previous methods.
Learning to Perceive in Deep Model-Free Reinforcement Learning
Jan 13, 2023



This work proposes a novel model-free Reinforcement Learning (RL) agent that is able to learn how to complete an unknown task having access to only a part of the input observation. We take inspiration from the concepts of visual attention and active perception that are characteristic of humans and tried to apply them to our agent, creating a hard attention mechanism. In this mechanism, the model decides first which region of the input image it should look at, and only after that it has access to the pixels of that region. Current RL agents do not follow this principle and we have not seen these mechanisms applied to the same purpose as this work. In our architecture, we adapt an existing model called recurrent attention model (RAM) and combine it with the proximal policy optimization (PPO) algorithm. We investigate whether a model with these characteristics is capable of achieving similar performance to state-of-the-art model-free RL agents that access the full input observation. This analysis is made in two Atari games, Pong and SpaceInvaders, which have a discrete action space, and in CarRacing, which has a continuous action space. Besides assessing its performance, we also analyze the movement of the attention of our model and compare it with what would be an example of the human behavior. Even with such visual limitation, we show that our model matches the performance of PPO+LSTM in two of the three games tested.
Centralized Training with Hybrid Execution in Multi-Agent Reinforcement Learning
Oct 12, 2022
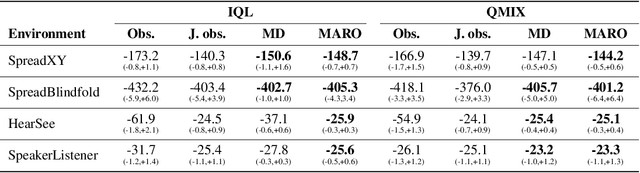

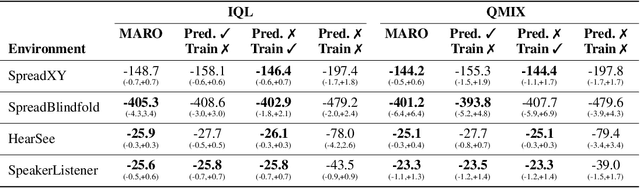
We introduce hybrid execution in multi-agent reinforcement learning (MARL), a new paradigm in which agents aim to successfully perform cooperative tasks with any communication level at execution time by taking advantage of information-sharing among the agents. Under hybrid execution, the communication level can range from a setting in which no communication is allowed between agents (fully decentralized), to a setting featuring full communication (fully centralized). To formalize our setting, we define a new class of multi-agent partially observable Markov decision processes (POMDPs) that we name hybrid-POMDPs, which explicitly models a communication process between the agents. We contribute MARO, an approach that combines an autoregressive predictive model to estimate missing agents' observations, and a dropout-based RL training scheme that simulates different communication levels during the centralized training phase. We evaluate MARO on standard scenarios and extensions of previous benchmarks tailored to emphasize the negative impact of partial observability in MARL. Experimental results show that our method consistently outperforms baselines, allowing agents to act with faulty communication while successfully exploiting shared information.
Perceive, Represent, Generate: Translating Multimodal Information to Robotic Motion Trajectories
Apr 06, 2022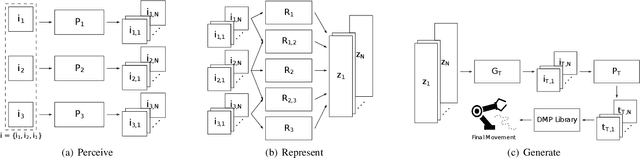



We present Perceive-Represent-Generate (PRG), a novel three-stage framework that maps perceptual information of different modalities (e.g., visual or sound), corresponding to a sequence of instructions, to an adequate sequence of movements to be executed by a robot. In the first stage, we perceive and pre-process the given inputs, isolating individual commands from the complete instruction provided by a human user. In the second stage we encode the individual commands into a multimodal latent space, employing a deep generative model. Finally, in the third stage we convert the multimodal latent values into individual trajectories and combine them into a single dynamic movement primitive, allowing its execution in a robotic platform. We evaluate our pipeline in the context of a novel robotic handwriting task, where the robot receives as input a word through different perceptual modalities (e.g., image, sound), and generates the corresponding motion trajectory to write it, creating coherent and readable handwritten words.
Onception: Active Learning with Expert Advice for Real World Machine Translation
Mar 12, 2022


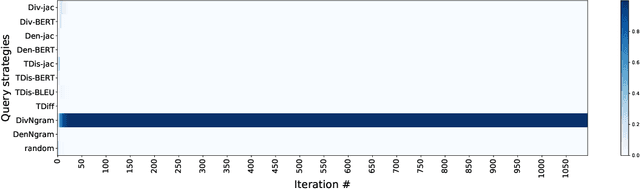
Active learning can play an important role in low-resource settings (i.e., where annotated data is scarce), by selecting which instances may be more worthy to annotate. Most active learning approaches for Machine Translation assume the existence of a pool of sentences in a source language, and rely on human annotators to provide translations or post-edits, which can still be costly. In this article, we assume a real world human-in-the-loop scenario in which: (i) the source sentences may not be readily available, but instead arrive in a stream; (ii) the automatic translations receive feedback in the form of a rating, instead of a correct/edited translation, since the human-in-the-loop might be a user looking for a translation, but not be able to provide one. To tackle the challenge of deciding whether each incoming pair source-translations is worthy to query for human feedback, we resort to a number of stream-based active learning query strategies. Moreover, since we not know in advance which query strategy will be the most adequate for a certain language pair and set of Machine Translation models, we propose to dynamically combine multiple strategies using prediction with expert advice. Our experiments show that using active learning allows to converge to the best Machine Translation systems with fewer human interactions. Furthermore, combining multiple strategies using prediction with expert advice often outperforms several individual active learning strategies with even fewer interactions.
Assisting Unknown Teammates in Unknown Tasks: Ad Hoc Teamwork under Partial Observability
Jan 10, 2022



In this paper, we present a novel Bayesian online prediction algorithm for the problem setting of ad hoc teamwork under partial observability (ATPO), which enables on-the-fly collaboration with unknown teammates performing an unknown task without needing a pre-coordination protocol. Unlike previous works that assume a fully observable state of the environment, ATPO accommodates partial observability, using the agent's observations to identify which task is being performed by the teammates. Our approach assumes neither that the teammate's actions are visible nor an environment reward signal. We evaluate ATPO in three domains -- two modified versions of the Pursuit domain with partial observability and the overcooked domain. Our results show that ATPO is effective and robust in identifying the teammate's task from a large library of possible tasks, efficient at solving it in near-optimal time, and scalable in adapting to increasingly larger problem sizes.