 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Bellman operator for convergence of $Q$-learning with linear function approximation
Sep 28, 2023We study the convergence of $Q$-learning with linear function approximation. Our key contribution is the introduction of a novel multi-Bellman operator that extends the traditional Bellman operator. By exploring the properties of this operator, we identify conditions under which the projected multi-Bellman operator becomes contractive, providing improved fixed-point guarantees compared to the Bellman operator. To leverage these insights, we propose the multi $Q$-learning algorithm with linear function approximation. We demonstrate that this algorithm converges to the fixed-point of the projected multi-Bellman operator, yielding solutions of arbitrary accuracy. Finally, we validate our approach by applying it to well-known environments, showcasing the effectiveness and applicability of our findings.
Centralized Training with Hybrid Execution in Multi-Agent Reinforcement Learning
Oct 12, 2022
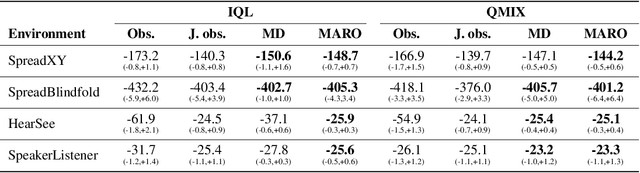

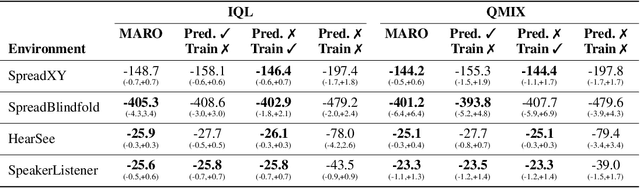
We introduce hybrid execution in multi-agent reinforcement learning (MARL), a new paradigm in which agents aim to successfully perform cooperative tasks with any communication level at execution time by taking advantage of information-sharing among the agents. Under hybrid execution, the communication level can range from a setting in which no communication is allowed between agents (fully decentralized), to a setting featuring full communication (fully centralized). To formalize our setting, we define a new class of multi-agent partially observable Markov decision processes (POMDPs) that we name hybrid-POMDPs, which explicitly models a communication process between the agents. We contribute MARO, an approach that combines an autoregressive predictive model to estimate missing agents' observations, and a dropout-based RL training scheme that simulates different communication levels during the centralized training phase. We evaluate MARO on standard scenarios and extensions of previous benchmarks tailored to emphasize the negative impact of partial observability in MARL. Experimental results show that our method consistently outperforms baselines, allowing agents to act with faulty communication while successfully exploiting shared information.
Hierarchically Structured Scheduling and Execution of Tasks in a Multi-Agent Environment
Mar 06, 2022
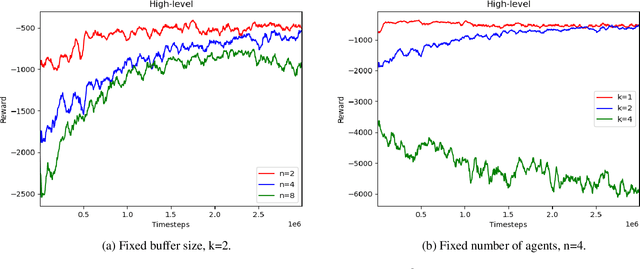
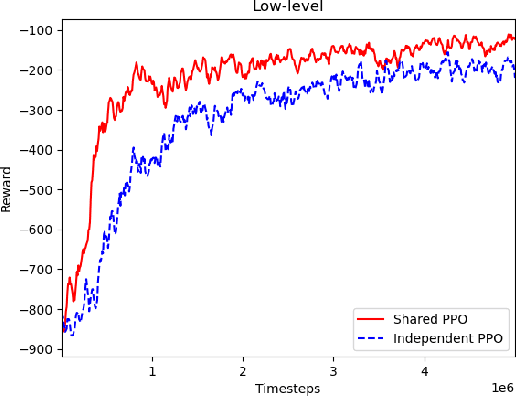
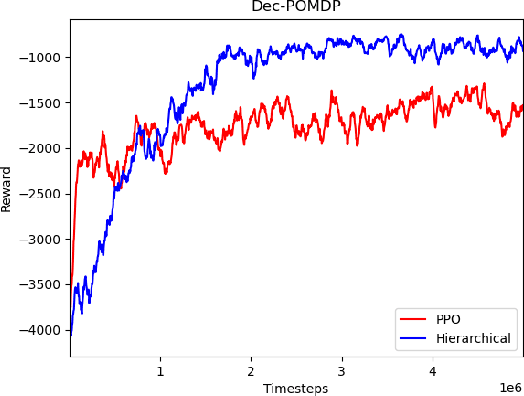
In a warehouse environment, tasks appear dynamically. Consequently, a task management system that matches them with the workforce too early (e.g., weeks in advance) is necessarily sub-optimal. Also, the rapidly increasing size of the action space of such a system consists of a significant problem for traditional schedulers. Reinforcement learning, however, is suited to deal with issues requiring making sequential decisions towards a long-term, often remote, goal. In this work, we set ourselves on a problem that presents itself with a hierarchical structure: the task-scheduling, by a centralised agent, in a dynamic warehouse multi-agent environment and the execution of one such schedule, by decentralised agents with only partial observability thereof. We propose to use deep reinforcement learning to solve both the high-level scheduling problem and the low-level multi-agent problem of schedule execution. Finally, we also conceive the case where centralisation is impossible at test time and workers must learn how to cooperate in executing the tasks in an environment with no schedule and only partial observability.
Understanding the Impact of Data Distribution on Q-learning with Function Approximation
Nov 23, 2021
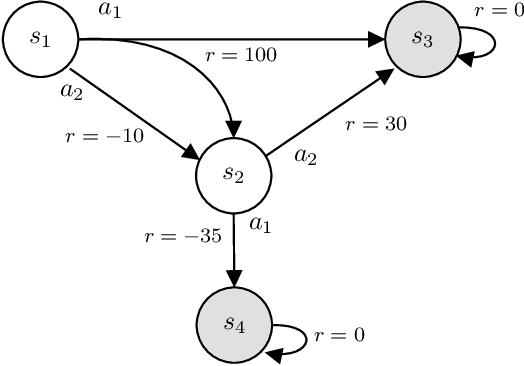
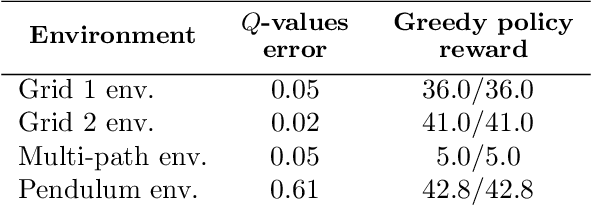

In this work, we focus our attention on the study of the interplay between the data distribution and Q-learning-based algorithms with function approximation. We provide a theoretical and empirical analysis as to why different properties of the data distribution can contribute to regulating sources of algorithmic instability. First, we revisit theoretical bounds on the performance of approximate dynamic programming algorithms. Second, we provide a novel four-state MDP that highlights the impact of the data distribution in the performance of a Q-learning algorithm with function approximation, both in online and offline settings. Finally, we experimentally assess the impact of the data distribution properties in the performance of an offline deep Q-network algorithm. Our results show that: (i) the data distribution needs to possess certain properties in order to robustly learn in an offline setting, namely low distance to the distributions induced by optimal policies of the MDP and high coverage over the state-action space; and (ii) high entropy data distributions can contribute to mitigating sources of algorithmic instability.
CHARET: Character-centered Approach to Emotion Tracking in Stories
Feb 15, 2021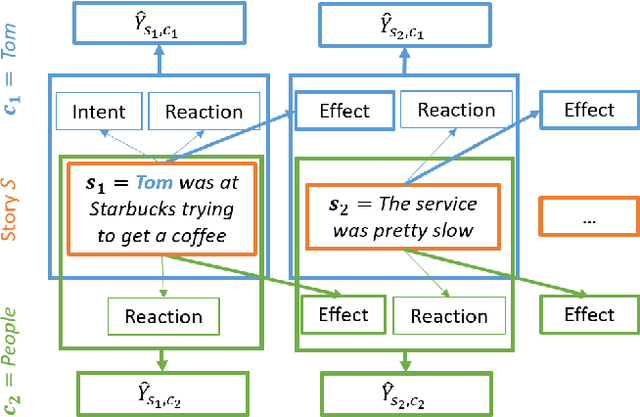
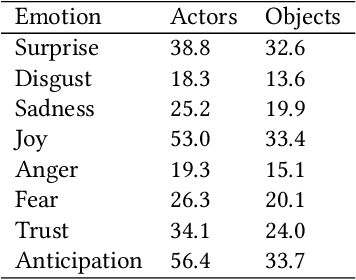

Autonomous agents that can engage in social interactions witha human is the ultimate goal of a myriad of applications. A keychallenge in the design of these applications is to define the socialbehavior of the agent, which requires extensive content creation.In this research, we explore how we can leverage current state-of-the-art tools to make inferences about the emotional state ofa character in a story as events unfold, in a coherent way. Wepropose a character role-labelling approach to emotion tracking thataccounts for the semantics of emotions. We show that by identifyingactors and objects of events and considering the emotional stateof the characters, we can achieve better performance in this task,when compared to end-to-end approaches.