 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropic Risk-Aware Monte Carlo Tree Search
Jan 25, 2026We propose a provably correct Monte Carlo tree search (MCTS) algorithm for solving \textit{risk-aware} Markov decision processes (MDPs) with \textit{entropic risk measure} (ERM) objectives. We provide a \textit{non-asymptotic} analysis of our proposed algorithm, showing that the algorithm: (i) is \textit{correct} in the sense that the empirical ERM obtained at the root node converges to the optimal ERM; and (ii) enjoys \textit{polynomial regret concentration}. Our algorithm successfully exploits the dynamic programming formulations for solving risk-aware MDPs with ERM objectives introduced by previous works in the context of an upper confidence bound-based tree search algorithm. Finally, we provide a set of illustrative experiments comparing our risk-aware MCTS method against relevant baselines.
Solving General-Utility Markov Decision Processes in the Single-Trial Regime with Online Planning
May 21, 2025In this work, we contribute the first approach to solve infinite-horizon discounted general-utility Markov decision processes (GUMDPs) in the single-trial regime, i.e., when the agent's performance is evaluated based on a single trajectory. First, we provide some fundamental results regarding policy optimization in the single-trial regime, investigating which class of policies suffices for optimality, casting our problem as a particular MDP that is equivalent to our original problem, as well as studying the computational hardness of policy optimization in the single-trial regime. Second, we show how we can leverage online planning techniques, in particular a Monte-Carlo tree search algorithm, to solve GUMDPs in the single-trial regime. Third, we provide experimental results showcasing the superior performance of our approach in comparison to relevant baselines.
A Computational Model of Inclusive Pedagogy: From Understanding to Application
May 02, 2025Human education transcends mere knowledge transfer, it relies on co-adaptation dynamics -- the mutual adjustment of teaching and learning strategies between agents. Despite its centrality, computational models of co-adaptive teacher-student interactions (T-SI) remain underdeveloped. We argue that this gap impedes Educational Science in testing and scaling contextual insights across diverse settings, and limits the potential of Machine Learning systems, which struggle to emulate and adaptively support human learning processes. To address this, we present a computational T-SI model that integrates contextual insights on human education into a testable framework. We use the model to evaluate diverse T-SI strategies in a realistic synthetic classroom setting, simulating student groups with unequal access to sensory information. Results show that strategies incorporating co-adaptation principles (e.g., bidirectional agency) outperform unilateral approaches (i.e., where only the teacher or the student is active), improving the learning outcomes for all learning types. Beyond the testing and scaling of context-dependent educational insights, our model enables hypothesis generation in controlled yet adaptable environments. This work bridges non-computational theories of human education with scalable, inclusive AI in Education systems, providing a foundation for equitable technologies that dynamically adapt to learner needs.
Centralized Training with Hybrid Execution in Multi-Agent Reinforcement Learning
Oct 12, 2022
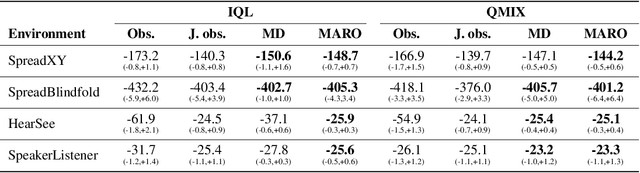

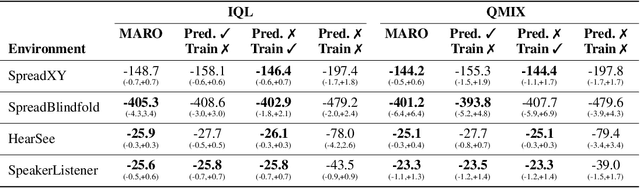
We introduce hybrid execution in multi-agent reinforcement learning (MARL), a new paradigm in which agents aim to successfully perform cooperative tasks with any communication level at execution time by taking advantage of information-sharing among the agents. Under hybrid execution, the communication level can range from a setting in which no communication is allowed between agents (fully decentralized), to a setting featuring full communication (fully centralized). To formalize our setting, we define a new class of multi-agent partially observable Markov decision processes (POMDPs) that we name hybrid-POMDPs, which explicitly models a communication process between the agents. We contribute MARO, an approach that combines an autoregressive predictive model to estimate missing agents' observations, and a dropout-based RL training scheme that simulates different communication levels during the centralized training phase. We evaluate MARO on standard scenarios and extensions of previous benchmarks tailored to emphasize the negative impact of partial observability in MARL. Experimental results show that our method consistently outperforms baselines, allowing agents to act with faulty communication while successfully exploiting shared information.
Understanding the Impact of Data Distribution on Q-learning with Function Approximation
Nov 23, 2021
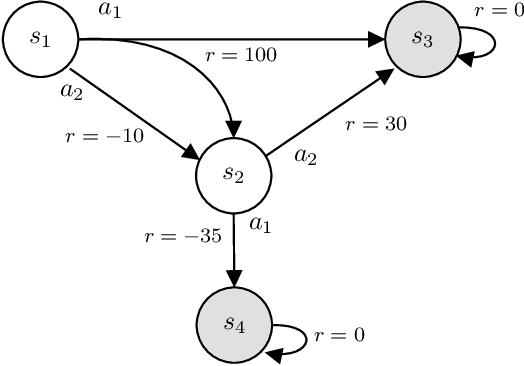
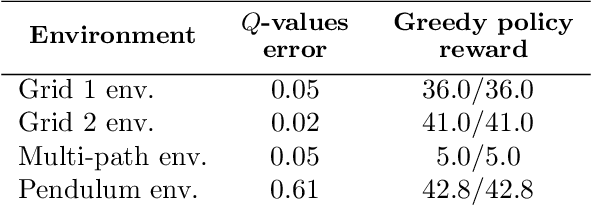

In this work, we focus our attention on the study of the interplay between the data distribution and Q-learning-based algorithms with function approximation. We provide a theoretical and empirical analysis as to why different properties of the data distribution can contribute to regulating sources of algorithmic instability. First, we revisit theoretical bounds on the performance of approximate dynamic programming algorithms. Second, we provide a novel four-state MDP that highlights the impact of the data distribution in the performance of a Q-learning algorithm with function approximation, both in online and offline settings. Finally, we experimentally assess the impact of the data distribution properties in the performance of an offline deep Q-network algorithm. Our results show that: (i) the data distribution needs to possess certain properties in order to robustly learn in an offline setting, namely low distance to the distributions induced by optimal policies of the MDP and high coverage over the state-action space; and (ii) high entropy data distributions can contribute to mitigating sources of algorithmic instability.
A Methodology for the Development of RL-Based Adaptive Traffic Signal Controllers
Jan 24, 2021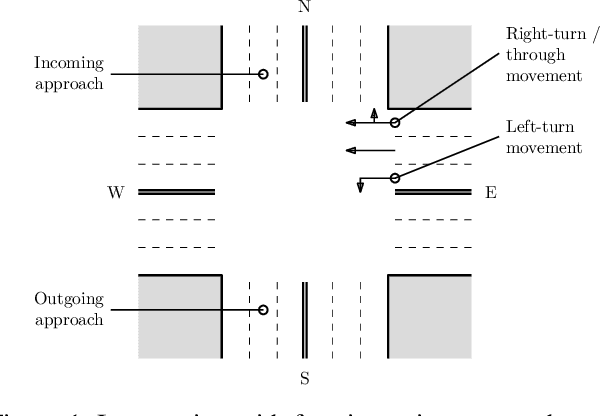


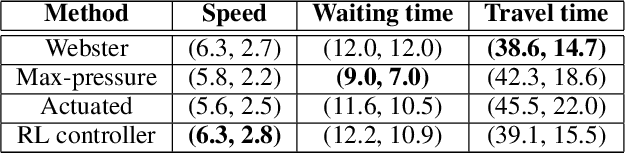
This article proposes a methodology for the development of adaptive traffic signal controllers using reinforcement learning. Our methodology addresses the lack of standardization in the literature that renders the comparison of approaches in different works meaningless, due to differences in metrics, environments, and even experimental design and methodology. The proposed methodology thus comprises all the steps necessary to develop, deploy and evaluate an adaptive traffic signal controller -- from simulation setup to problem formulation and experimental design. We illustrate the proposed methodology in two simple scenarios, highlighting how its different steps address limitations found in the current literature.