 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Computational Model of Inclusive Pedagogy: From Understanding to Application
May 02, 2025Human education transcends mere knowledge transfer, it relies on co-adaptation dynamics -- the mutual adjustment of teaching and learning strategies between agents. Despite its centrality, computational models of co-adaptive teacher-student interactions (T-SI) remain underdeveloped. We argue that this gap impedes Educational Science in testing and scaling contextual insights across diverse settings, and limits the potential of Machine Learning systems, which struggle to emulate and adaptively support human learning processes. To address this, we present a computational T-SI model that integrates contextual insights on human education into a testable framework. We use the model to evaluate diverse T-SI strategies in a realistic synthetic classroom setting, simulating student groups with unequal access to sensory information. Results show that strategies incorporating co-adaptation principles (e.g., bidirectional agency) outperform unilateral approaches (i.e., where only the teacher or the student is active), improving the learning outcomes for all learning types. Beyond the testing and scaling of context-dependent educational insights, our model enables hypothesis generation in controlled yet adaptable environments. This work bridges non-computational theories of human education with scalable, inclusive AI in Education systems, providing a foundation for equitable technologies that dynamically adapt to learner needs.
Body Schema Acquisition through Active Learning
Feb 08, 2024We present an active learning algorithm for the problem of body schema learning, i.e. estimating a kinematic model of a serial robot. The learning process is done online using Recursive Least Squares (RLS) estimation, which outperforms gradient methods usually applied in the literature. In addiction, the method provides the required information to apply an active learning algorithm to find the optimal set of robot configurations and observations to improve the learning process. By selecting the most informative observations, the proposed method minimizes the required amount of data. We have developed an efficient version of the active learning algorithm to select the points in real-time. The algorithms have been tested and compared using both simulated environments and a real humanoid robot.
* International Conference on Robotics and Automation (ICRA) 2010
Revisiting proximity effect using broadband signals
Jan 11, 2024Experiments studying mainly proximity effect are presented. Pink noise and music were used as stimuli and a combo guitar amplifier as source to test several microphones: omnidirectional and directional. We plot in-axis levels and spectral balances as functions of x, the distance to the source. Proximity effect was found for omnidirectional microphones. In-axis level curves show that 1/x law seems poorly valid. Spectral balance evolutions depend on microphones and moreover on stimuli: bigger decreases of low frequencies with pink noise; larger increases of other frequencies with music. For a naked loudspeaker, we found similar in-axis level curves under and above the cut-off frequency and propose an explanation. Listening equalized music recordings will help to demonstrate proximity effect for tested microphones.Paper 7106 presented at the 122th Convention of the Audio Engineering Society, Wien, 2007
Listening broadband physical model for microphones: a first step
Jan 04, 2024We will present a first step in design of a broadband physical model for microphones. Within the proposed model, classical directivity patterns (omnidirectional, bidirectional and cardioids family) are refound as limit cases: monochromatic excitation, low frequency and far-field approximation. Monophonic pieces of music are used as sources for the model so we can listen the simulation of the associated recorded sound field in realtime thanks to a Max/MSP application. Listening and subbands analysis show that the directivity is a function of frequential subband and source location. This model also exhibits an interesting proximity effect. Audio demonstrations will be given.Paper 6638 presented at the 120th Convention of the Audio Engineering Society, Paris, 2006
Interactively Teaching an Inverse Reinforcement Learner with Limited Feedback
Sep 16, 2023



We study the problem of teaching via demonstrations in sequential decision-making tasks. In particular, we focus on the situation when the teacher has no access to the learner's model and policy, and the feedback from the learner is limited to trajectories that start from states selected by the teacher. The necessity to select the starting states and infer the learner's policy creates an opportunity for using the methods of inverse reinforcement learning and active learning by the teacher. In this work, we formalize the teaching process with limited feedback and propose an algorithm that solves this teaching problem. The algorithm uses a modified version of the active value-at-risk method to select the starting states, a modified maximum causal entropy algorithm to infer the policy, and the difficulty score ratio method to choose the teaching demonstrations. We test the algorithm in a synthetic car driving environment and conclude that the proposed algorithm is an effective solution when the learner's feedback is limited.
Agents for Automated User Experience Testing
Apr 13, 2021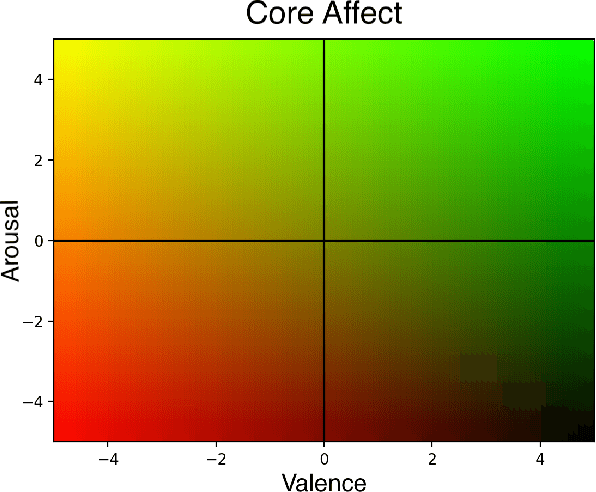
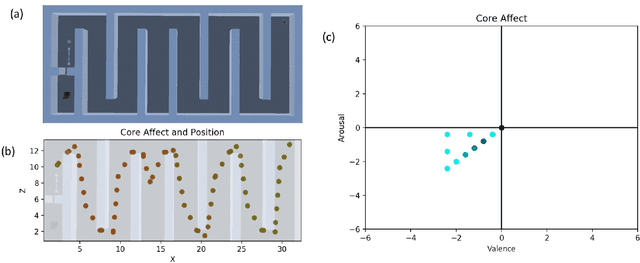
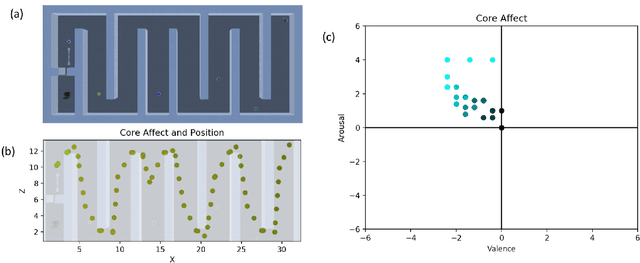
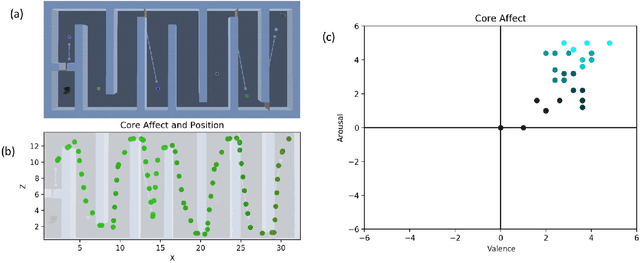
The automation of functional testing in software has allowed developers to continuously check for negative impacts on functionality throughout the iterative phases of development. This is not the case for User eXperience (UX), which has hitherto relied almost exclusively on testing with real users. User testing is a slow endeavour that can become a bottleneck for development of interactive systems. To address this problem, we here propose an agent based approach for automatic UX testing. We develop agents with basic problem solving skills and a core affect model, allowing us to model an artificial affective state as they traverse different levels of a game. Although this research is still at a primordial state, we believe the results here presented make a strong case for the use of intelligent agents endowed with affective computing models for automating UX testing.
Class Teaching for Inverse Reinforcement Learners
Nov 29, 2019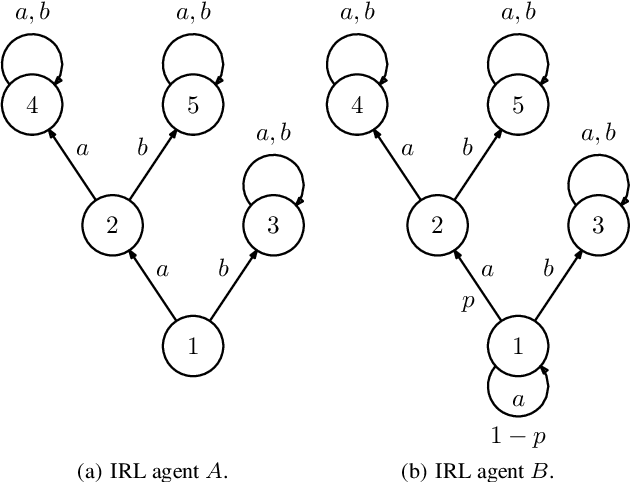
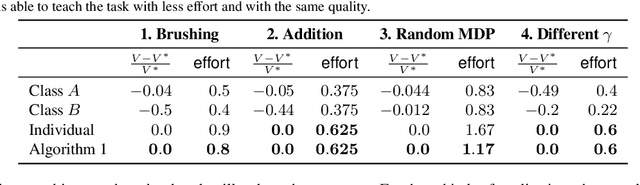
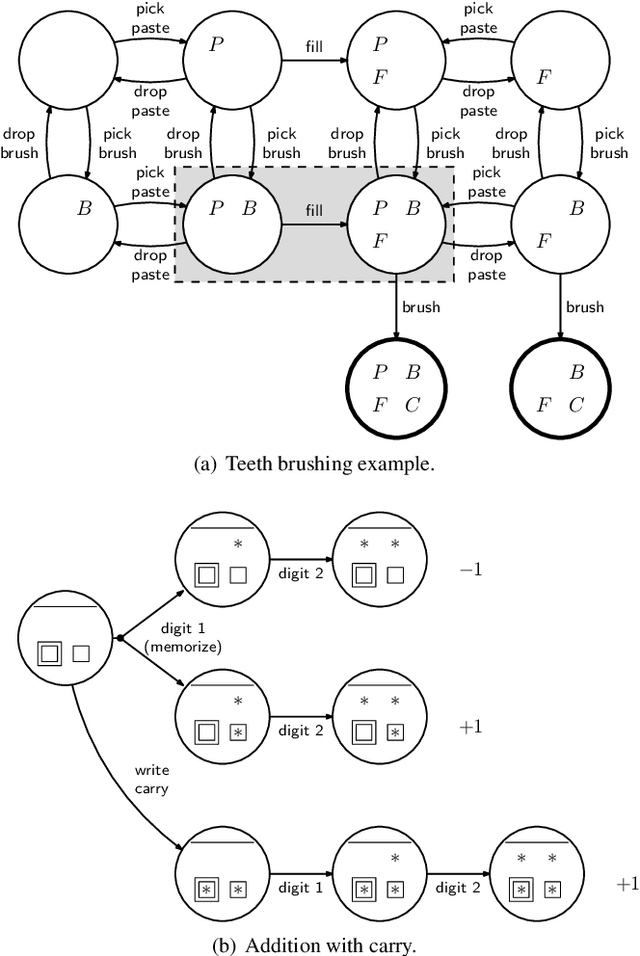
In this paper we propose the first machine teaching algorithm for multiple inverse reinforcement learners. Specifically, our contributions are: (i) we formally introduce the problem of teaching a sequential task to a heterogeneous group of learners; (ii) we identify conditions under which it is possible to conduct such teaching using the same demonstration for all learners; and (iii) we propose and evaluate a simple algorithm that computes a demonstration(s) ensuring that all agents in a heterogeneous class learn a task description that is compatible with the target task. Our analysis shows that, contrary to other teaching problems, teaching a heterogeneous class with a single demonstration may not be possible as the differences between agents increase. We also showcase the advantages of our proposed machine teaching approach against several possible alternatives.
Norms for Beneficial A.I.: A Computational Analysis of the Societal Value Alignment Problem
Jun 26, 2019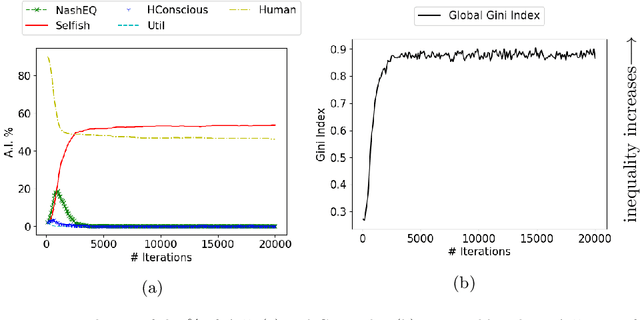
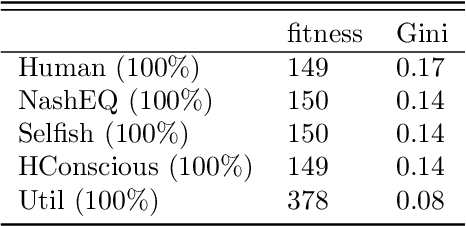
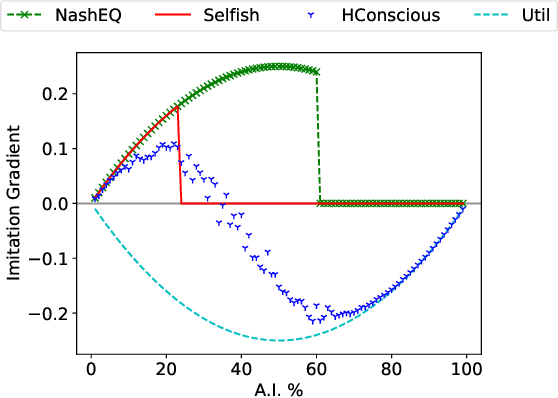

The rise of artificial intelligence (A.I.) based systems has the potential to benefit adopters and society as a whole. However, these systems may also enclose potential conflicts and unintended consequences. Notably, people will only adopt an A.I. system if it confers them an advantage, at which point non-adopters might push for a strong regulation if that advantage for adopters is at a cost for them. Here we propose a stochastic game theoretical model for these conflicts. We frame our results under the current discussion on ethical A.I. and the conflict between individual and societal gains, the societal value alignment problem. We test the arising equilibria in the adoption of A.I. technology under different norms followed by artificial agents, their ensuing benefits, and the emergent levels of wealth inequality. We show that without any regulation, purely selfish A.I. systems will have the strongest advantage, even when a utilitarian A.I. provides a more significant benefit for the individual and the society. Nevertheless, we show that it is possible to develop human conscious A.I. systems that reach an equilibrium where the gains for the adopters are not at a cost for non-adopters while increasing the overall fitness and lowering inequality. However, as shown, a self-organized adoption of such policies would require external regulation.
Multi-Armed Bandits for Intelligent Tutoring Systems
Jun 19, 2015
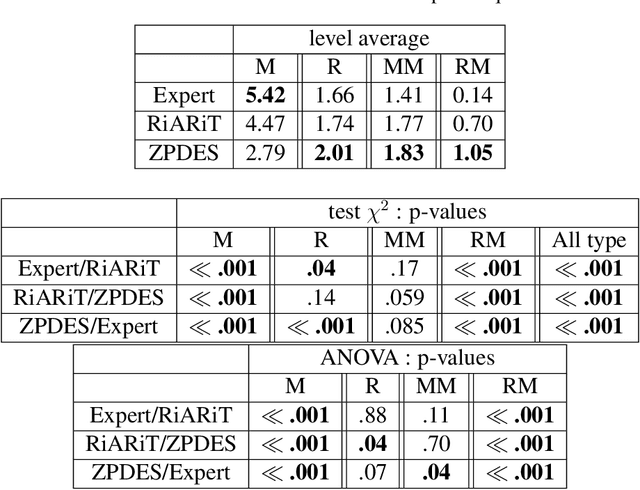
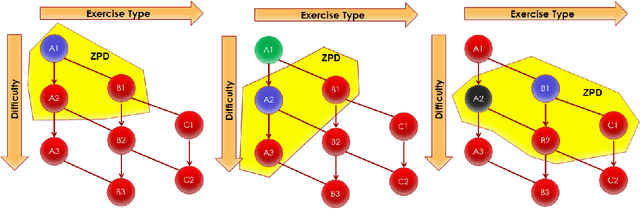
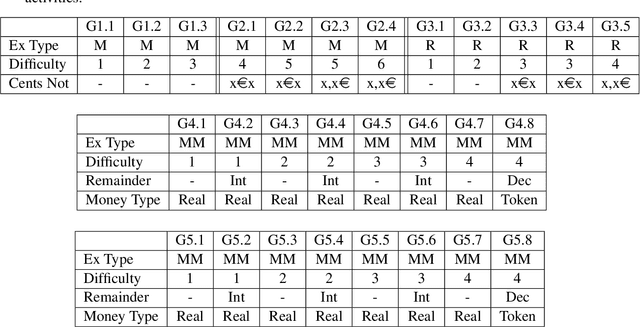
We present an approach to Intelligent Tutoring Systems which adaptively personalizes sequences of learning activities to maximize skills acquired by students, taking into account the limited time and motivational resources. At a given point in time, the system proposes to the students the activity which makes them progress faster. We introduce two algorithms that rely on the empirical estimation of the learning progress, RiARiT that uses information about the difficulty of each exercise and ZPDES that uses much less knowledge about the problem. The system is based on the combination of three approaches. First, it leverages recent models of intrinsically motivated learning by transposing them to active teaching, relying on empirical estimation of learning progress provided by specific activities to particular students. Second, it uses state-of-the-art Multi-Arm Bandit (MAB) techniques to efficiently manage the exploration/exploitation challenge of this optimization process. Third, it leverages expert knowledge to constrain and bootstrap initial exploration of the MAB, while requiring only coarse guidance information of the expert and allowing the system to deal with didactic gaps in its knowledge. The system is evaluated in a scenario where 7-8 year old schoolchildren learn how to decompose numbers while manipulating money. Systematic experiments are presented with simulated students, followed by results of a user study across a population of 400 school children.
Active Learning for Autonomous Intelligent Agents: Exploration, Curiosity, and Interaction
Mar 06, 2014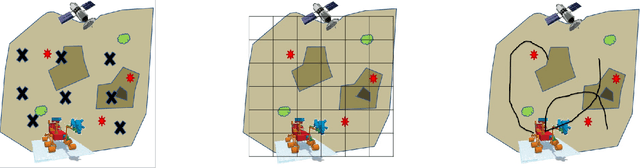
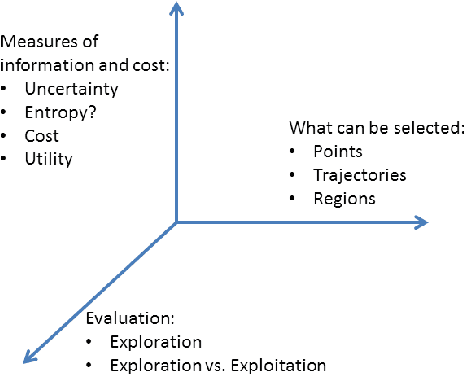

In this survey we present different approaches that allow an intelligent agent to explore autonomous its environment to gather information and learn multiple tasks. Different communities proposed different solutions, that are in many cases, similar and/or complementary. These solutions include active learning, exploration/exploitation, online-learning and social learning. The common aspect of all these approaches is that it is the agent to selects and decides what information to gather next. Applications for these approaches already include tutoring systems, autonomous grasping learning, navigation and mapping and human-robot interaction. We discuss how these approaches are related, explaining their similarities and their differences in terms of problem assumptions and metrics of success. We consider that such an integrated discussion will improve inter-disciplinary research and applications.