 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Generation of Question Hints for Mathematics Problems using Large Language Models in Educational Technology
Nov 05, 2024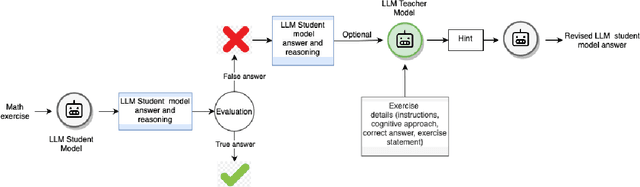
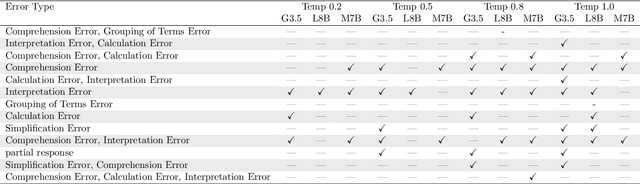
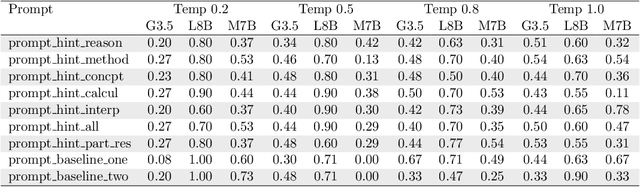
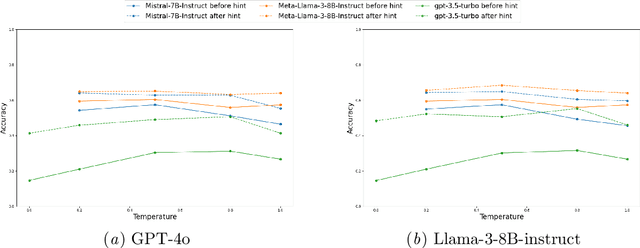
The automatic generation of hints by Large Language Models (LLMs) within Intelligent Tutoring Systems (ITSs) has shown potential to enhance student learning. However, generating pedagogically sound hints that address student misconceptions and adhere to specific educational objectives remains challenging. This work explores using LLMs (GPT-4o and Llama-3-8B-instruct) as teachers to generate effective hints for students simulated through LLMs (GPT-3.5-turbo, Llama-3-8B-Instruct, or Mistral-7B-instruct-v0.3) tackling math exercises designed for human high-school students, and designed using cognitive science principles. We present here the study of several dimensions: 1) identifying error patterns made by simulated students on secondary-level math exercises; 2) developing various prompts for GPT-4o as a teacher and evaluating their effectiveness in generating hints that enable simulated students to self-correct; and 3) testing the best-performing prompts, based on their ability to produce relevant hints and facilitate error correction, with Llama-3-8B-Instruct as the teacher, allowing for a performance comparison with GPT-4o. The results show that model errors increase with higher temperature settings. Notably, when hints are generated by GPT-4o, the most effective prompts include prompts tailored to specific errors as well as prompts providing general hints based on common mathematical errors. Interestingly, Llama-3-8B-Instruct as a teacher showed better overall performance than GPT-4o. Also the problem-solving and response revision capabilities of the LLMs as students, particularly GPT-3.5-turbo, improved significantly after receiving hints, especially at lower temperature settings. However, models like Mistral-7B-Instruct demonstrated a decline in performance as the temperature increased.
Multi-Armed Bandits for Intelligent Tutoring Systems
Jun 19, 2015
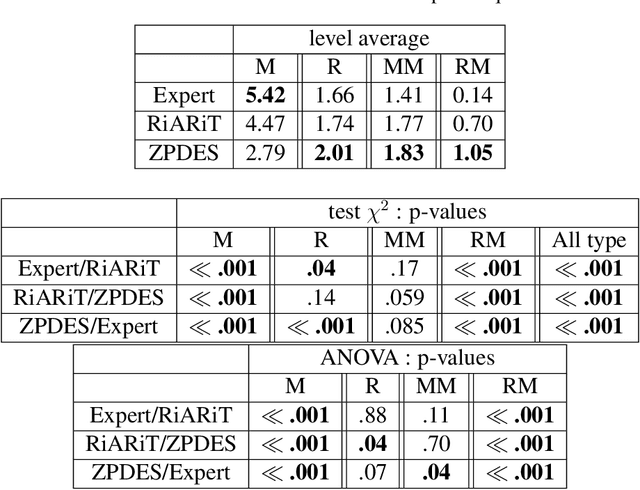
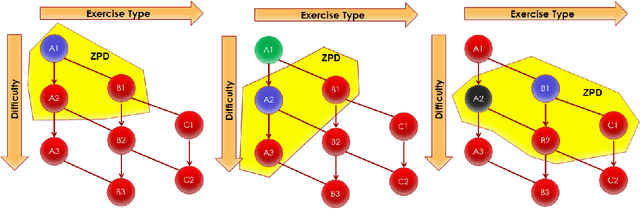
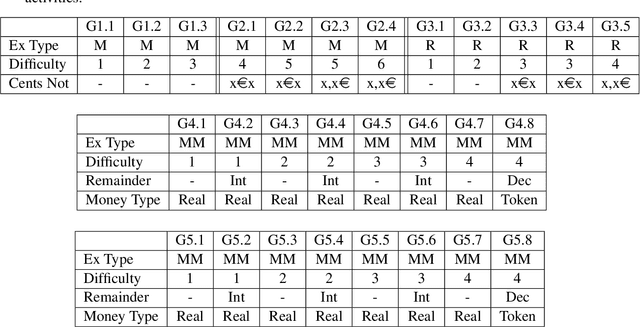
We present an approach to Intelligent Tutoring Systems which adaptively personalizes sequences of learning activities to maximize skills acquired by students, taking into account the limited time and motivational resources. At a given point in time, the system proposes to the students the activity which makes them progress faster. We introduce two algorithms that rely on the empirical estimation of the learning progress, RiARiT that uses information about the difficulty of each exercise and ZPDES that uses much less knowledge about the problem. The system is based on the combination of three approaches. First, it leverages recent models of intrinsically motivated learning by transposing them to active teaching, relying on empirical estimation of learning progress provided by specific activities to particular students. Second, it uses state-of-the-art Multi-Arm Bandit (MAB) techniques to efficiently manage the exploration/exploitation challenge of this optimization process. Third, it leverages expert knowledge to constrain and bootstrap initial exploration of the MAB, while requiring only coarse guidance information of the expert and allowing the system to deal with didactic gaps in its knowledge. The system is evaluated in a scenario where 7-8 year old schoolchildren learn how to decompose numbers while manipulating money. Systematic experiments are presented with simulated students, followed by results of a user study across a population of 400 school children.