 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Collective Action under Risk Diversity
Jan 30, 2022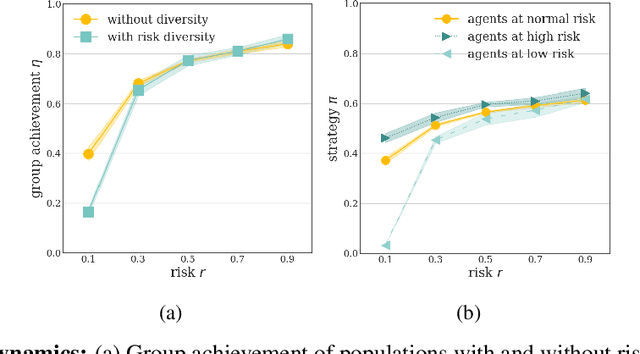
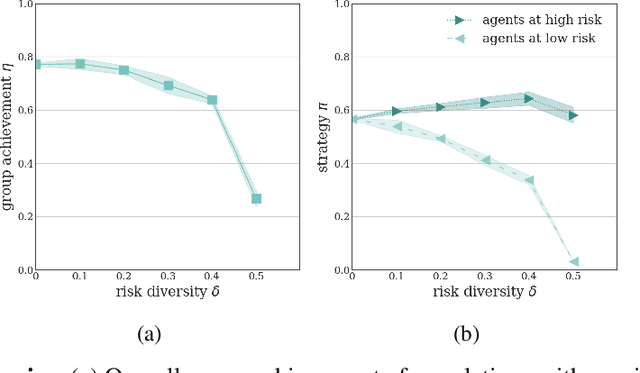
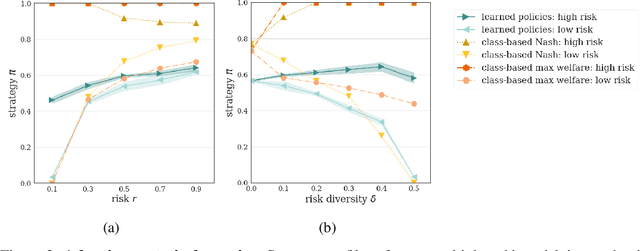
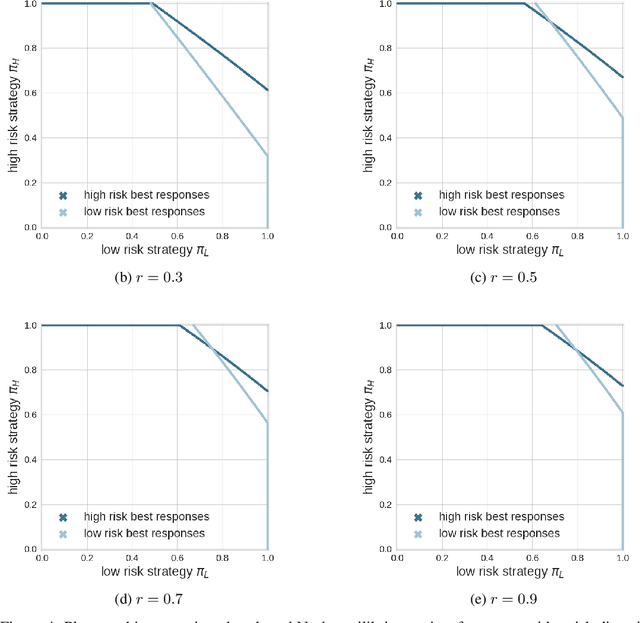
Collective risk dilemmas (CRDs) are a class of n-player games that represent societal challenges where groups need to coordinate to avoid the risk of a disastrous outcome. Multi-agent systems incurring such dilemmas face difficulties achieving cooperation and often converge to sub-optimal, risk-dominant solutions where everyone defects. In this paper we investigate the consequences of risk diversity in groups of agents learning to play CRDs. We find that risk diversity places new challenges to cooperation that are not observed in homogeneous groups. We show that increasing risk diversity significantly reduces overall cooperation and hinders collective target achievement. It leads to asymmetrical changes in agents' policies -- i.e. the increase in contributions from individuals at high risk is unable to compensate for the decrease in contributions from individuals at low risk -- which overall reduces the total contributions in a population. When comparing RL behaviors to rational individualistic and social behaviors, we find that RL populations converge to fairer contributions among agents. Our results highlight the need for aligning risk perceptions among agents or develop new learning techniques that explicitly account for risk diversity.
Voluntary safety commitments provide an escape from over-regulation in AI development
Apr 08, 2021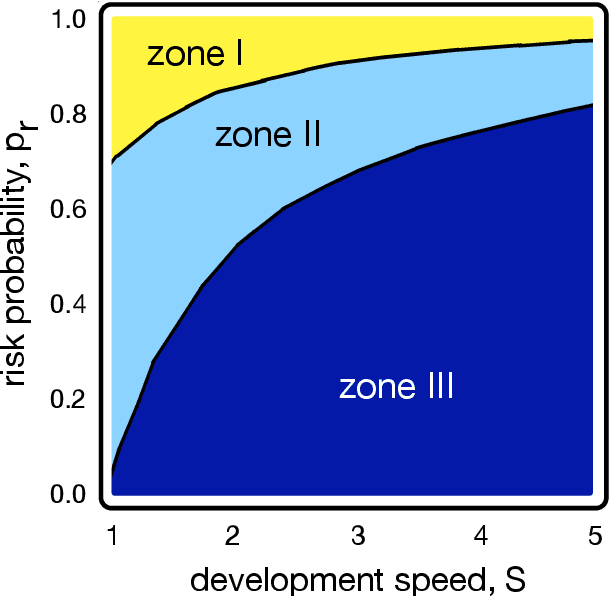
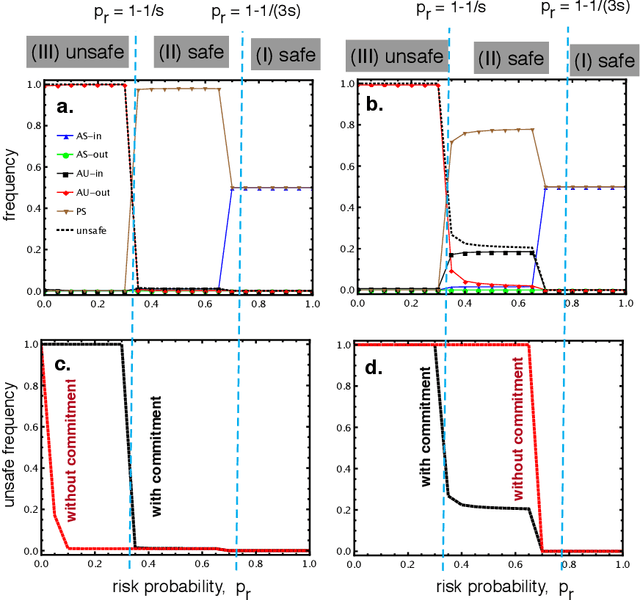
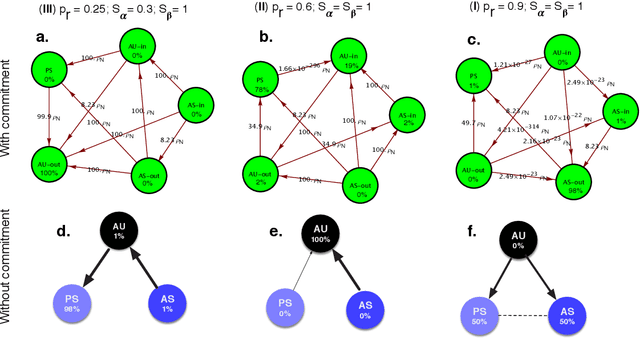
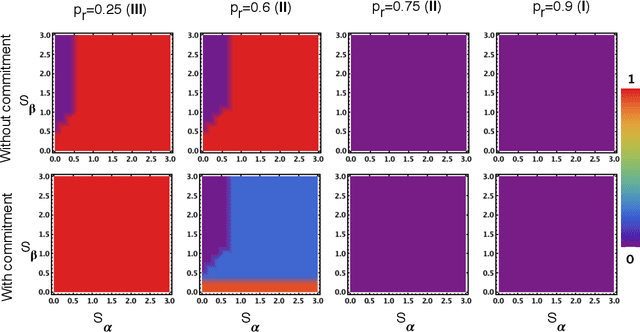
With the introduction of Artificial Intelligence (AI) and related technologies in our daily lives, fear and anxiety about their misuse as well as the hidden biases in their creation have led to a demand for regulation to address such issues. Yet blindly regulating an innovation process that is not well understood, may stifle this process and reduce benefits that society may gain from the generated technology, even under the best intentions. In this paper, starting from a baseline model that captures the fundamental dynamics of a race for domain supremacy using AI technology, we demonstrate how socially unwanted outcomes may be produced when sanctioning is applied unconditionally to risk-taking, i.e. potentially unsafe, behaviours. As an alternative to resolve the detrimental effect of over-regulation, we propose a voluntary commitment approach wherein technologists have the freedom of choice between independently pursuing their course of actions or establishing binding agreements to act safely, with sanctioning of those that do not abide to what they pledged. Overall, this work reveals for the first time how voluntary commitments, with sanctions either by peers or an institution, leads to socially beneficial outcomes in all scenarios envisageable in a short-term race towards domain supremacy through AI technology. These results are directly relevant for the design of governance and regulatory policies that aim to ensure an ethical and responsible AI technology development process.
AI Development Race Can Be Mediated on Heterogeneous Networks
Dec 30, 2020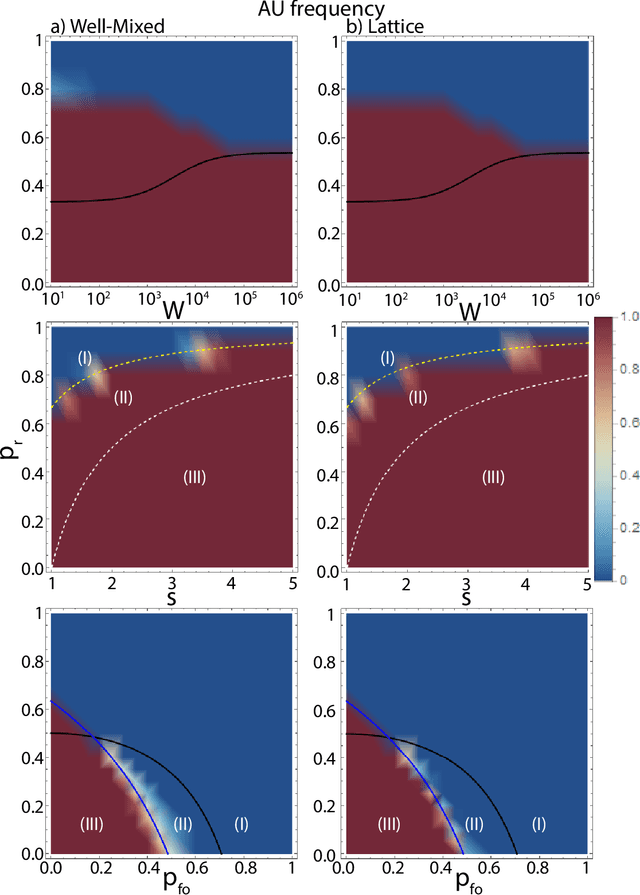
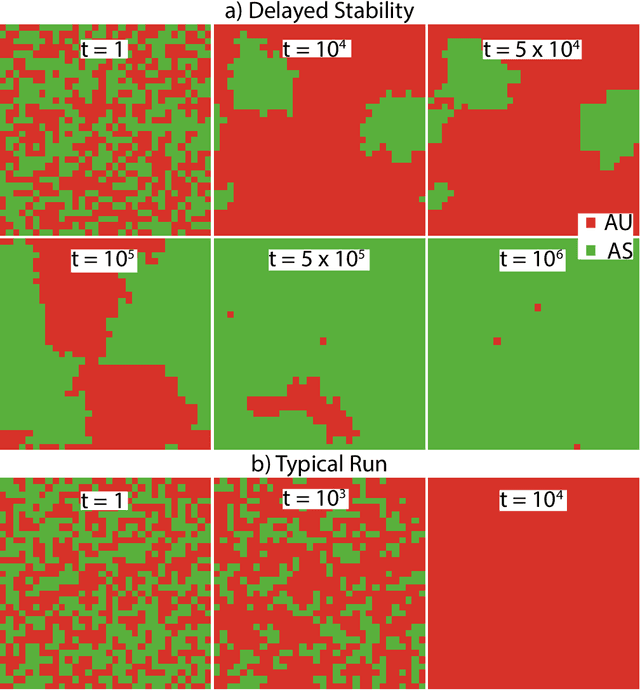
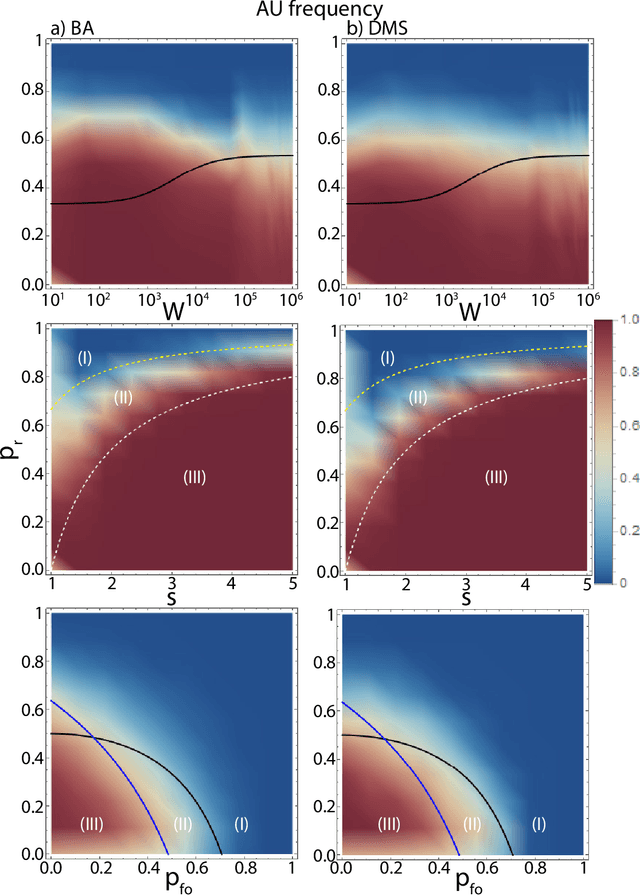
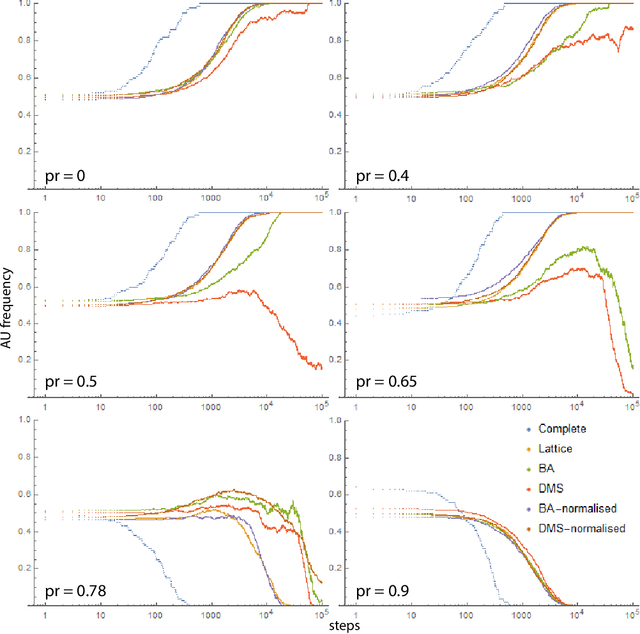
The field of Artificial Intelligence (AI) has been introducing a certain level of anxiety in research, business and also policy. Tensions are further heightened by an AI race narrative which makes many stakeholders fear that they might be missing out. Whether real or not, a belief in this narrative may be detrimental as some stakeholders will feel obliged to cut corners on safety precautions or ignore societal consequences. Starting from a game-theoretical model describing an idealised technology race in a well-mixed world, here we investigate how different interaction structures among race participants can alter collective choices and requirements for regulatory actions. Our findings indicate that, when participants portray a strong diversity in terms of connections and peer-influence (e.g., when scale-free networks shape interactions among parties), the conflicts that exist in homogeneous settings are significantly reduced, thereby lessening the need for regulatory actions. Furthermore, our results suggest that technology governance and regulation may profit from the world's patent heterogeneity and inequality among firms and nations to design and implement meticulous interventions on a minority of participants capable of influencing an entire population towards an ethical and sustainable use of AI.
Mediating Artificial Intelligence Developments through Negative and Positive Incentives
Oct 01, 2020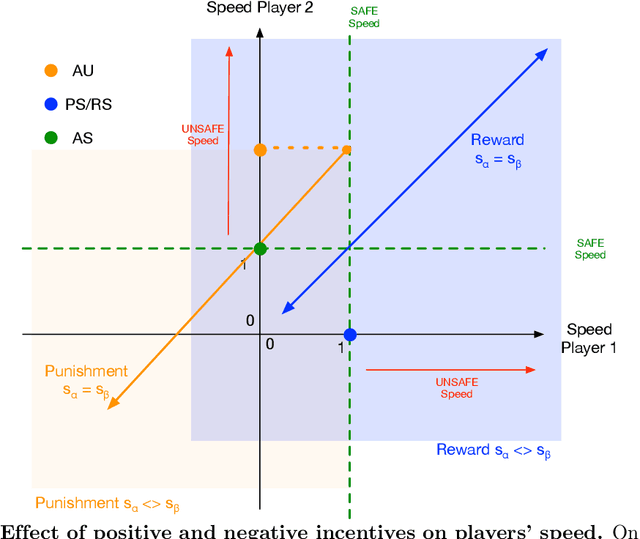
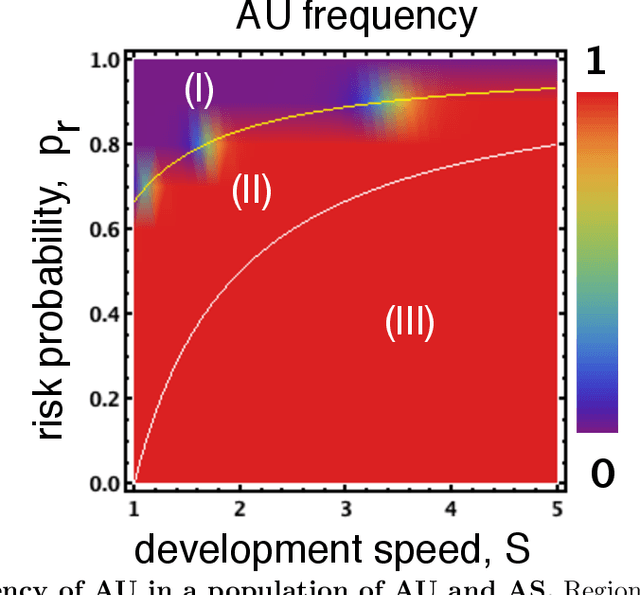
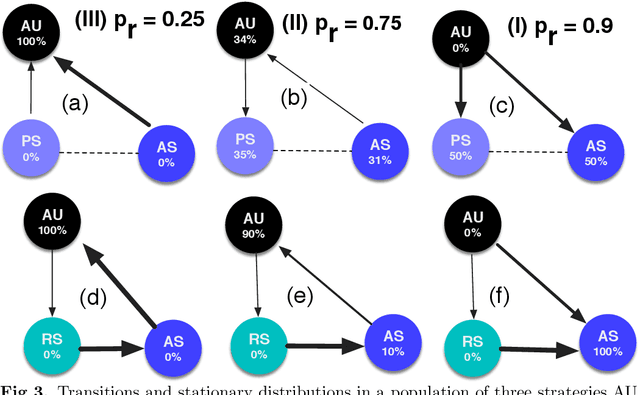
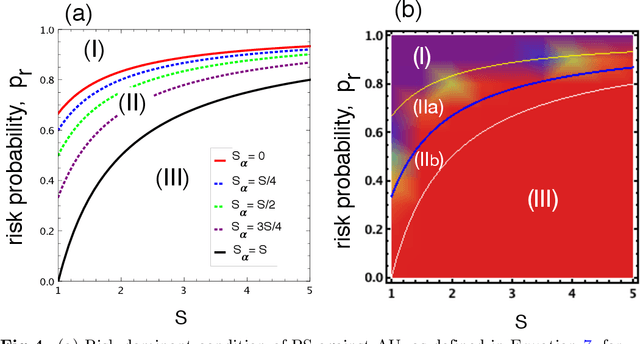
The field of Artificial Intelligence (AI) is going through a period of great expectations, introducing a certain level of anxiety in research, business and also policy. This anxiety is further energised by an AI race narrative that makes people believe they might be missing out. Whether real or not, a belief in this narrative may be detrimental as some stake-holders will feel obliged to cut corners on safety precautions, or ignore societal consequences just to "win". Starting from a baseline model that describes a broad class of technology races where winners draw a significant benefit compared to others (such as AI advances, patent race, pharmaceutical technologies), we investigate here how positive (rewards) and negative (punishments) incentives may beneficially influence the outcomes. We uncover conditions in which punishment is either capable of reducing the development speed of unsafe participants or has the capacity to reduce innovation through over-regulation. Alternatively, we show that, in several scenarios, rewarding those that follow safety measures may increase the development speed while ensuring safe choices. Moreover, in {the latter} regimes, rewards do not suffer from the issue of over-regulation as is the case for punishment. Overall, our findings provide valuable insights into the nature and kinds of regulatory actions most suitable to improve safety compliance in the contexts of both smooth and sudden technological shifts.
Navigating the Landscape of Games
May 04, 2020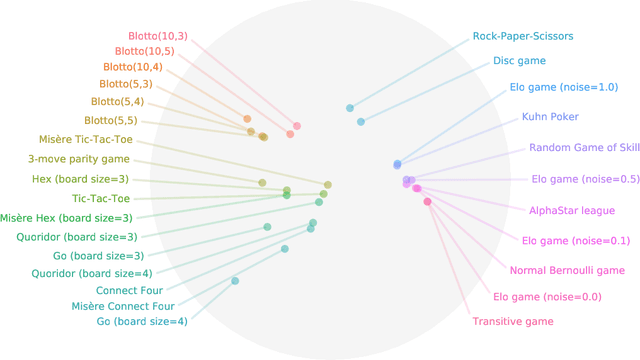
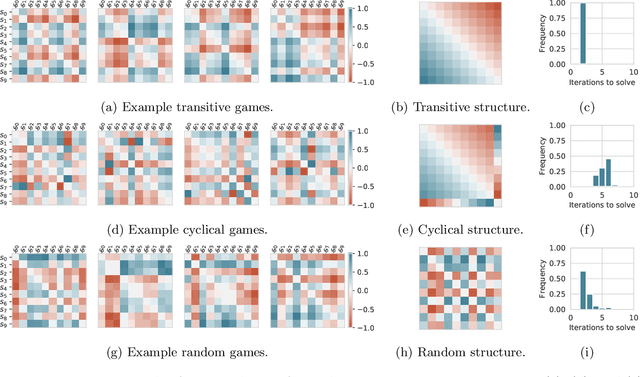
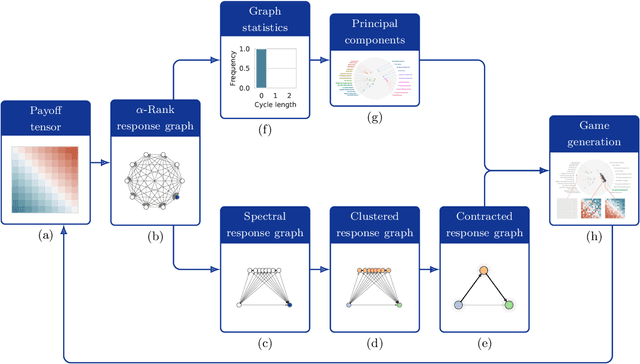

Games are traditionally recognized as one of the key testbeds underlying progress in artificial intelligence (AI), aptly referred to as the "Drosophila of AI". Traditionally, researchers have focused on using games to build strong AI agents that, e.g., achieve human-level performance. This progress, however, also requires a classification of how 'interesting' a game is for an artificial agent. Tackling this latter question not only facilitates an understanding of the characteristics of learnt AI agents in games, but also helps to determine what game an AI should address next as part of its training. Here, we show how network measures applied to so-called response graphs of large-scale games enable the creation of a useful landscape of games, quantifying the relationships between games of widely varying sizes, characteristics, and complexities. We illustrate our findings in various domains, ranging from well-studied canonical games to significantly more complex empirical games capturing the performance of trained AI agents pitted against one another. Our results culminate in a demonstration of how one can leverage this information to automatically generate new and interesting games, including mixtures of empirical games synthesized from real world games.
Counterfactual thinking in cooperation dynamics
Dec 18, 2019
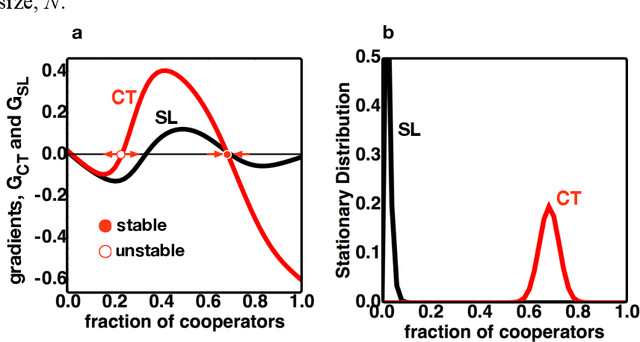
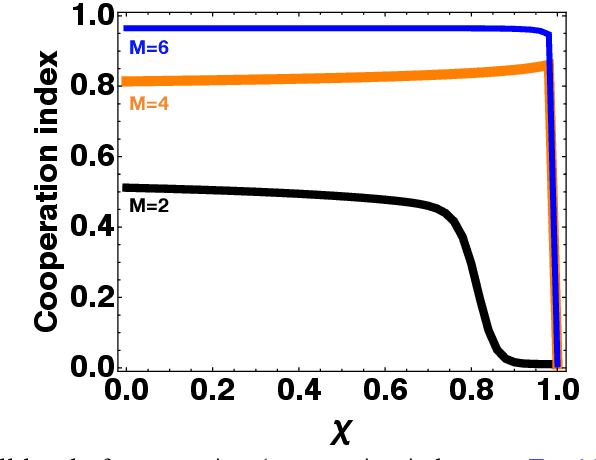
Counterfactual Thinking is a human cognitive ability studied in a wide variety of domains. It captures the process of reasoning about a past event that did not occur, namely what would have happened had this event occurred, or, otherwise, to reason about an event that did occur but what would ensue had it not. Given the wide cognitive empowerment of counterfactual reasoning in the human individual, the question arises of how the presence of individuals with this capability may improve cooperation in populations of self-regarding individuals. Here we propose a mathematical model, grounded on Evolutionary Game Theory, to examine the population dynamics emerging from the interplay between counterfactual thinking and social learning (i.e., individuals that learn from the actions and success of others) whenever the individuals in the population face a collective dilemma. Our results suggest that counterfactual reasoning fosters coordination in collective action problems occurring in large populations, and has a limited impact on cooperation dilemmas in which coordination is not required. Moreover, we show that a small prevalence of individuals resorting to counterfactual thinking is enough to nudge an entire population towards highly cooperative standards.
* 18 pages
Modelling the Safety and Surveillance of the AI Race
Jul 26, 2019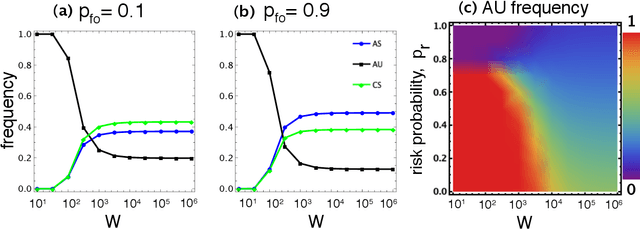

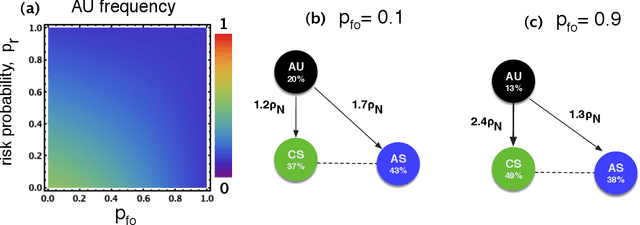
Innovation, creativity, and competition are some of the fundamental underlying forces driving the advances in Artificial Intelligence (AI). This race for technological supremacy creates a complex ecology of choices that may lead to negative consequences, in particular, when ethical and safety procedures are underestimated or even ignored. Here we resort to a novel game theoretical framework to describe the ongoing AI bidding war, also allowing for the identification of procedures on how to influence this race to achieve desirable outcomes. By exploring the similarities between the ongoing competition in AI and evolutionary systems, we show that the timelines in which AI supremacy can be achieved play a crucial role for the evolution of safety prone behaviour and whether influencing procedures are required. When this supremacy can be achieved in a short term (near AI), the significant advantage gained from winning a race leads to the dominance of those who completely ignore the safety precautions to gain extra speed, rendering of the presence of reciprocal behavior irrelevant. On the other hand, when such a supremacy is a distant future, reciprocating on others' safety behaviour provides in itself an efficient solution, even when monitoring of unsafe development is hard. Our results suggest under what conditions AI safety behaviour requires additional supporting procedures and provide a basic framework to model them.
Norms for Beneficial A.I.: A Computational Analysis of the Societal Value Alignment Problem
Jun 26, 2019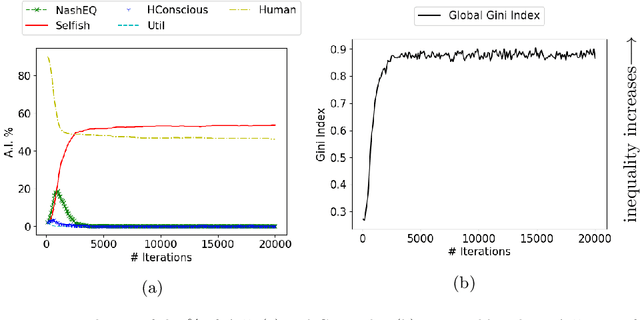
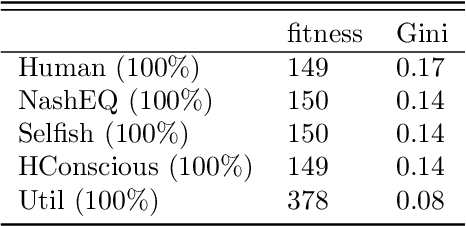
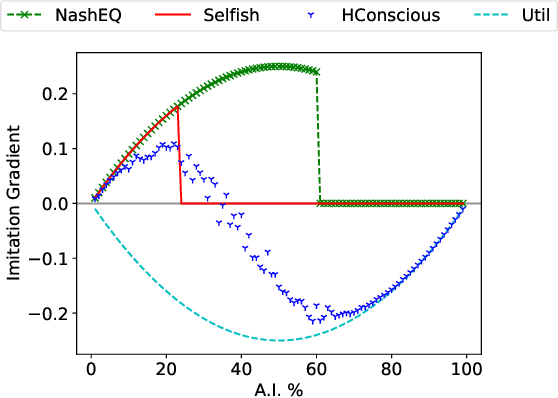

The rise of artificial intelligence (A.I.) based systems has the potential to benefit adopters and society as a whole. However, these systems may also enclose potential conflicts and unintended consequences. Notably, people will only adopt an A.I. system if it confers them an advantage, at which point non-adopters might push for a strong regulation if that advantage for adopters is at a cost for them. Here we propose a stochastic game theoretical model for these conflicts. We frame our results under the current discussion on ethical A.I. and the conflict between individual and societal gains, the societal value alignment problem. We test the arising equilibria in the adoption of A.I. technology under different norms followed by artificial agents, their ensuing benefits, and the emergent levels of wealth inequality. We show that without any regulation, purely selfish A.I. systems will have the strongest advantage, even when a utilitarian A.I. provides a more significant benefit for the individual and the society. Nevertheless, we show that it is possible to develop human conscious A.I. systems that reach an equilibrium where the gains for the adopters are not at a cost for non-adopters while increasing the overall fitness and lowering inequality. However, as shown, a self-organized adoption of such policies would require external regulation.