 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion of interest detection for efficient aortic segmentation
Jan 13, 2026Thoracic aortic dissection and aneurysms are the most lethal diseases of the aorta. The major hindrance to treatment lies in the accurate analysis of the medical images. More particularly, aortic segmentation of the 3D image is often tedious and difficult. Deep-learning-based segmentation models are an ideal solution, but their inability to deliver usable outputs in difficult cases and their computational cost cause their clinical adoption to stay limited. This study presents an innovative approach for efficient aortic segmentation using targeted region of interest (ROI) detection. In contrast to classical detection models, we propose a simple and efficient detection model that can be widely applied to detect a single ROI. Our detection model is trained as a multi-task model, using an encoder-decoder architecture for segmentation and a fully connected network attached to the bottleneck for detection. We compare the performance of a one-step segmentation model applied to a complete image, nnU-Net and our cascade model composed of a detection and a segmentation step. We achieve a mean Dice similarity coefficient of 0.944 with over 0.9 for all cases using a third of the computing power. This simple solution achieves state-of-the-art performance while being compact and robust, making it an ideal solution for clinical applications.
Zero-Incentive Dynamics: a look at reward sparsity through the lens of unrewarded subgoals
Jul 02, 2025This work re-examines the commonly held assumption that the frequency of rewards is a reliable measure of task difficulty in reinforcement learning. We identify and formalize a structural challenge that undermines the effectiveness of current policy learning methods: when essential subgoals do not directly yield rewards. We characterize such settings as exhibiting zero-incentive dynamics, where transitions critical to success remain unrewarded. We show that state-of-the-art deep subgoal-based algorithms fail to leverage these dynamics and that learning performance is highly sensitive to the temporal proximity between subgoal completion and eventual reward. These findings reveal a fundamental limitation in current approaches and point to the need for mechanisms that can infer latent task structure without relying on immediate incentives.
Open and Sustainable AI: challenges, opportunities and the road ahead in the life sciences
May 22, 2025


Artificial intelligence (AI) has recently seen transformative breakthroughs in the life sciences, expanding possibilities for researchers to interpret biological information at an unprecedented capacity, with novel applications and advances being made almost daily. In order to maximise return on the growing investments in AI-based life science research and accelerate this progress, it has become urgent to address the exacerbation of long-standing research challenges arising from the rapid adoption of AI methods. We review the increased erosion of trust in AI research outputs, driven by the issues of poor reusability and reproducibility, and highlight their consequent impact on environmental sustainability. Furthermore, we discuss the fragmented components of the AI ecosystem and lack of guiding pathways to best support Open and Sustainable AI (OSAI) model development. In response, this perspective introduces a practical set of OSAI recommendations directly mapped to over 300 components of the AI ecosystem. Our work connects researchers with relevant AI resources, facilitating the implementation of sustainable, reusable and transparent AI. Built upon life science community consensus and aligned to existing efforts, the outputs of this perspective are designed to aid the future development of policy and structured pathways for guiding AI implementation.
Wisdom from Diversity: Bias Mitigation Through Hybrid Human-LLM Crowds
May 18, 2025Despite their performance, large language models (LLMs) can inadvertently perpetuate biases found in the data they are trained on. By analyzing LLM responses to bias-eliciting headlines, we find that these models often mirror human biases. To address this, we explore crowd-based strategies for mitigating bias through response aggregation. We first demonstrate that simply averaging responses from multiple LLMs, intended to leverage the "wisdom of the crowd", can exacerbate existing biases due to the limited diversity within LLM crowds. In contrast, we show that locally weighted aggregation methods more effectively leverage the wisdom of the LLM crowd, achieving both bias mitigation and improved accuracy. Finally, recognizing the complementary strengths of LLMs (accuracy) and humans (diversity), we demonstrate that hybrid crowds containing both significantly enhance performance and further reduce biases across ethnic and gender-related contexts.
FRAUD-RLA: A new reinforcement learning adversarial attack against credit card fraud detection
Feb 04, 2025



Adversarial attacks pose a significant threat to data-driven systems, and researchers have spent considerable resources studying them. Despite its economic relevance, this trend largely overlooked the issue of credit card fraud detection. To address this gap, we propose a new threat model that demonstrates the limitations of existing attacks and highlights the necessity to investigate new approaches. We then design a new adversarial attack for credit card fraud detection, employing reinforcement learning to bypass classifiers. This attack, called FRAUD-RLA, is designed to maximize the attacker's reward by optimizing the exploration-exploitation tradeoff and working with significantly less required knowledge than competitors. Our experiments, conducted on three different heterogeneous datasets and against two fraud detection systems, indicate that FRAUD-RLA is effective, even considering the severe limitations imposed by our threat model.
Laser Learning Environment: A new environment for coordination-critical multi-agent tasks
Apr 04, 2024
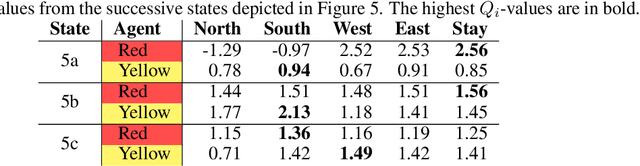

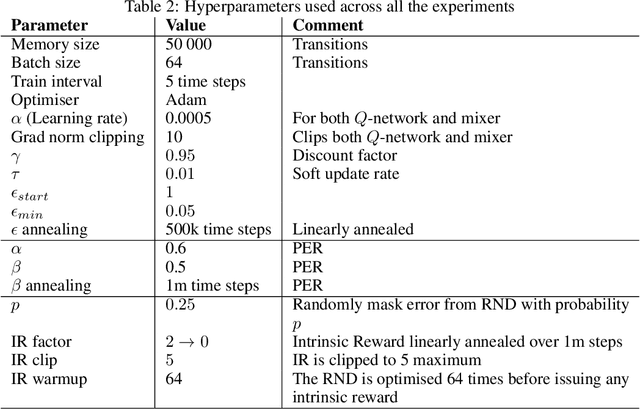
We introduce the Laser Learning Environment (LLE), a collaborative multi-agent reinforcement learning environment in which coordination is central. In LLE, agents depend on each other to make progress (interdependence), must jointly take specific sequences of actions to succeed (perfect coordination), and accomplishing those joint actions does not yield any intermediate reward (zero-incentive dynamics). The challenge of such problems lies in the difficulty of escaping state space bottlenecks caused by interdependence steps since escaping those bottlenecks is not rewarded. We test multiple state-of-the-art value-based MARL algorithms against LLE and show that they consistently fail at the collaborative task because of their inability to escape state space bottlenecks, even though they successfully achieve perfect coordination. We show that Q-learning extensions such as prioritized experience replay and n-steps return hinder exploration in environments with zero-incentive dynamics, and find that intrinsic curiosity with random network distillation is not sufficient to escape those bottlenecks. We demonstrate the need for novel methods to solve this problem and the relevance of LLE as cooperative MARL benchmark.
Mitigating Biases in Collective Decision-Making: Enhancing Performance in the Face of Fake News
Mar 11, 2024



Individual and social biases undermine the effectiveness of human advisers by inducing judgment errors which can disadvantage protected groups. In this paper, we study the influence these biases can have in the pervasive problem of fake news by evaluating human participants' capacity to identify false headlines. By focusing on headlines involving sensitive characteristics, we gather a comprehensive dataset to explore how human responses are shaped by their biases. Our analysis reveals recurring individual biases and their permeation into collective decisions. We show that demographic factors, headline categories, and the manner in which information is presented significantly influence errors in human judgment. We then use our collected data as a benchmark problem on which we evaluate the efficacy of adaptive aggregation algorithms. In addition to their improved accuracy, our results highlight the interactions between the emergence of collective intelligence and the mitigation of participant biases.
Expertise Trees Resolve Knowledge Limitations in Collective Decision-Making
May 04, 2023



Experts advising decision-makers are likely to display expertise which varies as a function of the problem instance. In practice, this may lead to sub-optimal or discriminatory decisions against minority cases. In this work we model such changes in depth and breadth of knowledge as a partitioning of the problem space into regions of differing expertise. We provide here new algorithms that explicitly consider and adapt to the relationship between problem instances and experts' knowledge. We first propose and highlight the drawbacks of a naive approach based on nearest neighbor queries. To address these drawbacks we then introduce a novel algorithm - expertise trees - that constructs decision trees enabling the learner to select appropriate models. We provide theoretical insights and empirically validate the improved performance of our novel approach on a range of problems for which existing methods proved to be inadequate.
ACROCPoLis: A Descriptive Framework for Making Sense of Fairness
Apr 19, 2023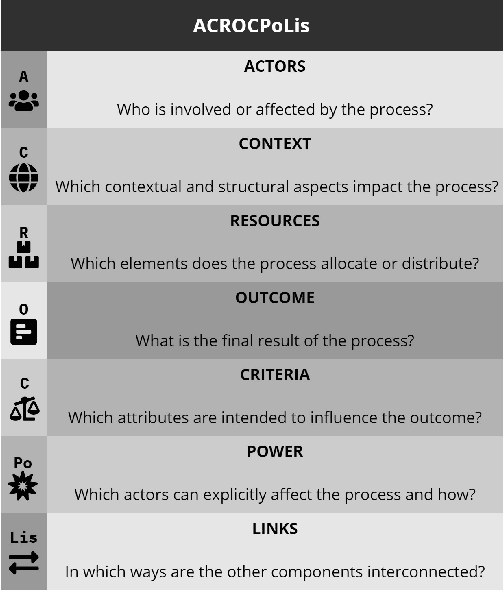
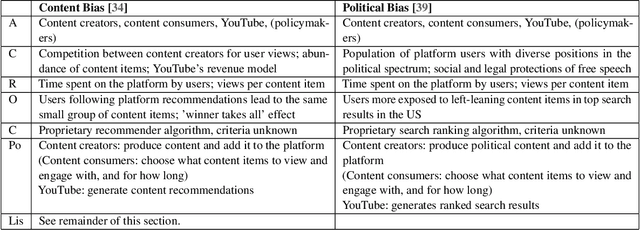
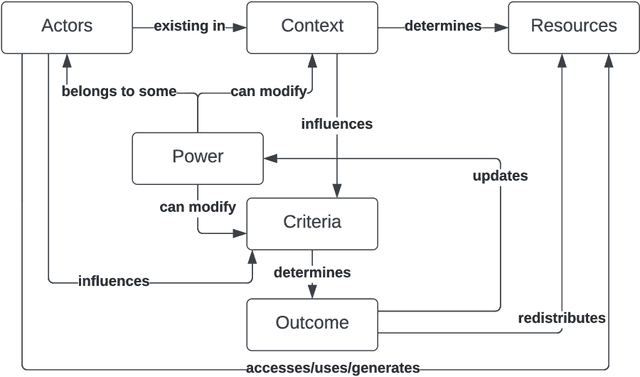
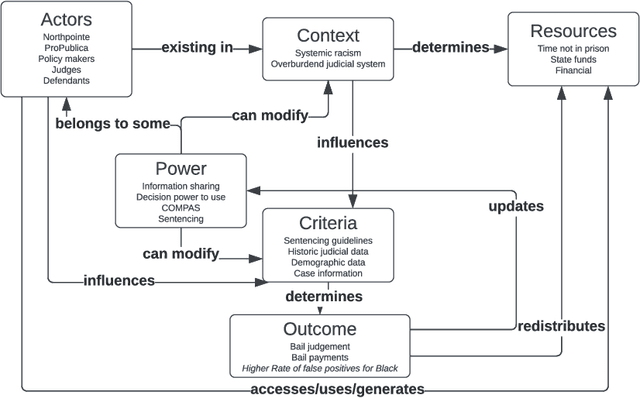
Fairness is central to the ethical and responsible development and use of AI systems, with a large number of frameworks and formal notions of algorithmic fairness being available. However, many of the fairness solutions proposed revolve around technical considerations and not the needs of and consequences for the most impacted communities. We therefore want to take the focus away from definitions and allow for the inclusion of societal and relational aspects to represent how the effects of AI systems impact and are experienced by individuals and social groups. In this paper, we do this by means of proposing the ACROCPoLis framework to represent allocation processes with a modeling emphasis on fairness aspects. The framework provides a shared vocabulary in which the factors relevant to fairness assessments for different situations and procedures are made explicit, as well as their interrelationships. This enables us to compare analogous situations, to highlight the differences in dissimilar situations, and to capture differing interpretations of the same situation by different stakeholders.
Dealing with Expert Bias in Collective Decision-Making
Jun 25, 2021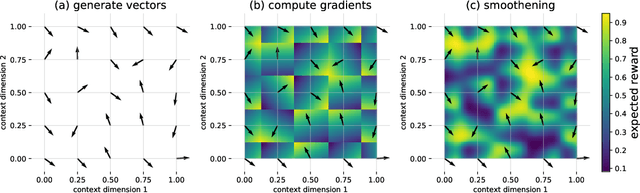
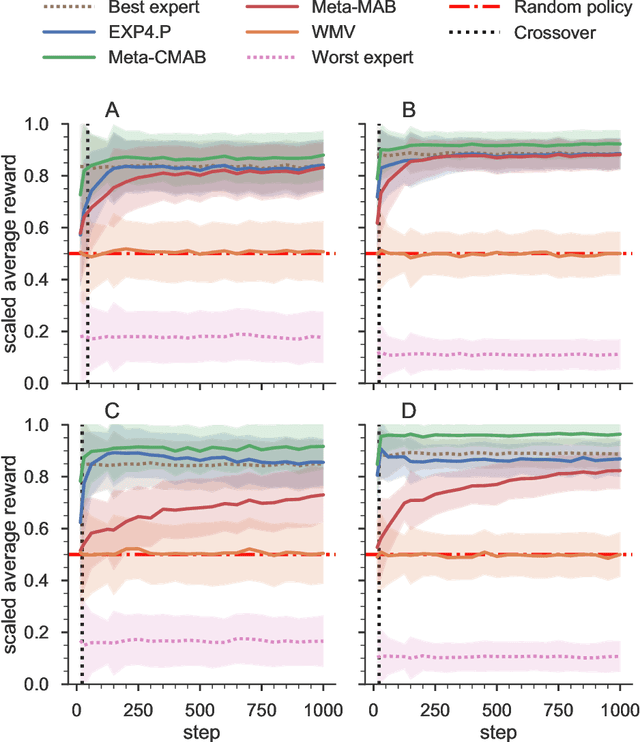
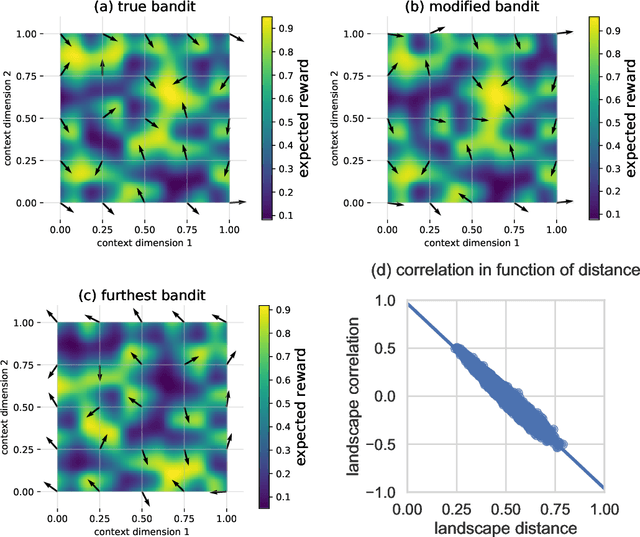
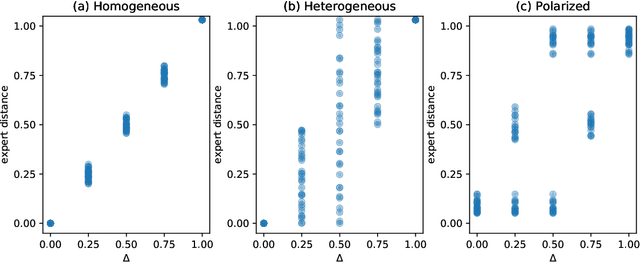
Quite some real-world problems can be formulated as decision-making problems wherein one must repeatedly make an appropriate choice from a set of alternatives. Expert judgements, whether human or artificial, can help in taking correct decisions, especially when exploration of alternative solutions is costly. As expert opinions might deviate, the problem of finding the right alternative can be approached as a collective decision making problem (CDM). Current state-of-the-art approaches to solve CDM are limited by the quality of the best expert in the group, and perform poorly if experts are not qualified or if they are overly biased, thus potentially derailing the decision-making process. In this paper, we propose a new algorithmic approach based on contextual multi-armed bandit problems (CMAB) to identify and counteract such biased expertises. We explore homogeneous, heterogeneous and polarised expert groups and show that this approach is able to effectively exploit the collective expertise, irrespective of whether the provided advice is directly conducive to good performance, outperforming state-of-the-art methods, especially when the quality of the provided expertise degrades. Our novel CMAB-inspired approach achieves a higher final performance and does so while converging more rapidly than previous adaptive algorithms, especially when heterogeneous expertise is readily available.