 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Methods for Neighborhood Selection in Local Search
Jan 12, 2026Reinforcement learning has recently gained traction as a means to improve combinatorial optimization methods, yet its effectiveness within local search metaheuristics specifically remains comparatively underexamined. In this study, we evaluate a range of reinforcement learning-based neighborhood selection strategies -- multi-armed bandits (upper confidence bound, $ε$-greedy) and deep reinforcement learning methods (proximal policy optimization, double deep $Q$-network) -- and compare them against multiple baselines across three different problems: the traveling salesman problem, the pickup and delivery problem with time windows, and the car sequencing problem. We show how search-specific characteristics, particularly large variations in cost due to constraint violation penalties, necessitate carefully designed reward functions to provide stable and informative learning signals. Our extensive experiments reveal that algorithm performance varies substantially across problems, although that $ε$-greedy consistently ranks among the best performers. In contrast, the computational overhead of deep reinforcement learning approaches only makes them competitive with a substantially longer runtime. These findings highlight both the promise and the practical limitations of deep reinforcement learning in local search.
Zero-Incentive Dynamics: a look at reward sparsity through the lens of unrewarded subgoals
Jul 02, 2025This work re-examines the commonly held assumption that the frequency of rewards is a reliable measure of task difficulty in reinforcement learning. We identify and formalize a structural challenge that undermines the effectiveness of current policy learning methods: when essential subgoals do not directly yield rewards. We characterize such settings as exhibiting zero-incentive dynamics, where transitions critical to success remain unrewarded. We show that state-of-the-art deep subgoal-based algorithms fail to leverage these dynamics and that learning performance is highly sensitive to the temporal proximity between subgoal completion and eventual reward. These findings reveal a fundamental limitation in current approaches and point to the need for mechanisms that can infer latent task structure without relying on immediate incentives.
FRAUD-RLA: A new reinforcement learning adversarial attack against credit card fraud detection
Feb 04, 2025



Adversarial attacks pose a significant threat to data-driven systems, and researchers have spent considerable resources studying them. Despite its economic relevance, this trend largely overlooked the issue of credit card fraud detection. To address this gap, we propose a new threat model that demonstrates the limitations of existing attacks and highlights the necessity to investigate new approaches. We then design a new adversarial attack for credit card fraud detection, employing reinforcement learning to bypass classifiers. This attack, called FRAUD-RLA, is designed to maximize the attacker's reward by optimizing the exploration-exploitation tradeoff and working with significantly less required knowledge than competitors. Our experiments, conducted on three different heterogeneous datasets and against two fraud detection systems, indicate that FRAUD-RLA is effective, even considering the severe limitations imposed by our threat model.
Laser Learning Environment: A new environment for coordination-critical multi-agent tasks
Apr 04, 2024
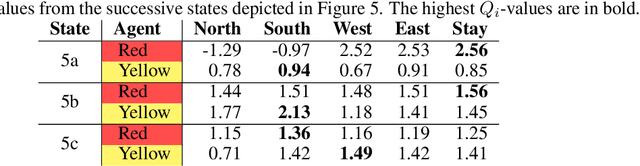

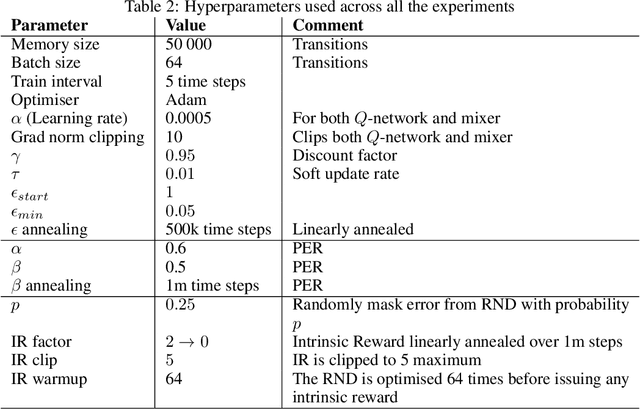
We introduce the Laser Learning Environment (LLE), a collaborative multi-agent reinforcement learning environment in which coordination is central. In LLE, agents depend on each other to make progress (interdependence), must jointly take specific sequences of actions to succeed (perfect coordination), and accomplishing those joint actions does not yield any intermediate reward (zero-incentive dynamics). The challenge of such problems lies in the difficulty of escaping state space bottlenecks caused by interdependence steps since escaping those bottlenecks is not rewarded. We test multiple state-of-the-art value-based MARL algorithms against LLE and show that they consistently fail at the collaborative task because of their inability to escape state space bottlenecks, even though they successfully achieve perfect coordination. We show that Q-learning extensions such as prioritized experience replay and n-steps return hinder exploration in environments with zero-incentive dynamics, and find that intrinsic curiosity with random network distillation is not sufficient to escape those bottlenecks. We demonstrate the need for novel methods to solve this problem and the relevance of LLE as cooperative MARL benchmark.