 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInclusive Fitness as a Key Step Towards More Advanced Social Behaviors in Multi-Agent Reinforcement Learning Settings
Oct 14, 2025The competitive and cooperative forces of natural selection have driven the evolution of intelligence for millions of years, culminating in nature's vast biodiversity and the complexity of human minds. Inspired by this process, we propose a novel multi-agent reinforcement learning framework where each agent is assigned a genotype and where reward functions are modelled after the concept of inclusive fitness. An agent's genetic material may be shared with other agents, and our inclusive reward function naturally accounts for this. We study the resulting social dynamics in two types of network games with prisoner's dilemmas and find that our results align with well-established principles from biology, such as Hamilton's rule. Furthermore, we outline how this framework can extend to more open-ended environments with spatial and temporal structure, finite resources, and evolving populations. We hypothesize the emergence of an arms race of strategies, where each new strategy is a gradual improvement over earlier adaptations of other agents, effectively producing a multi-agent autocurriculum analogous to biological evolution. In contrast to the binary team-based structures prevalent in earlier research, our gene-based reward structure introduces a spectrum of cooperation ranging from full adversity to full cooperativeness based on genetic similarity, enabling unique non team-based social dynamics. For example, one agent having a mutual cooperative relationship with two other agents, while the two other agents behave adversarially towards each other. We argue that incorporating inclusive fitness in agents provides a foundation for the emergence of more strategically advanced and socially intelligent agents.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Laser Learning Environment: A new environment for coordination-critical multi-agent tasks
Apr 04, 2024
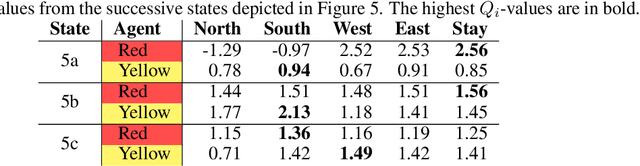

We introduce the Laser Learning Environment (LLE), a collaborative multi-agent reinforcement learning environment in which coordination is central. In LLE, agents depend on each other to make progress (interdependence), must jointly take specific sequences of actions to succeed (perfect coordination), and accomplishing those joint actions does not yield any intermediate reward (zero-incentive dynamics). The challenge of such problems lies in the difficulty of escaping state space bottlenecks caused by interdependence steps since escaping those bottlenecks is not rewarded. We test multiple state-of-the-art value-based MARL algorithms against LLE and show that they consistently fail at the collaborative task because of their inability to escape state space bottlenecks, even though they successfully achieve perfect coordination. We show that Q-learning extensions such as prioritized experience replay and n-steps return hinder exploration in environments with zero-incentive dynamics, and find that intrinsic curiosity with random network distillation is not sufficient to escape those bottlenecks. We demonstrate the need for novel methods to solve this problem and the relevance of LLE as cooperative MARL benchmark.
Dynamic Size Message Scheduling for Multi-Agent Communication under Limited Bandwidth
Jun 16, 2023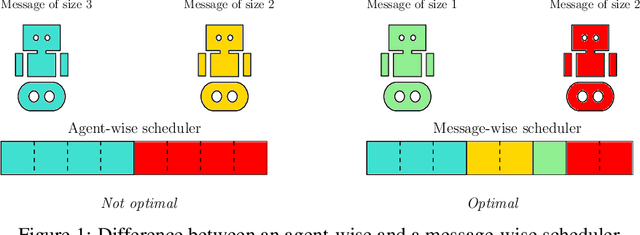
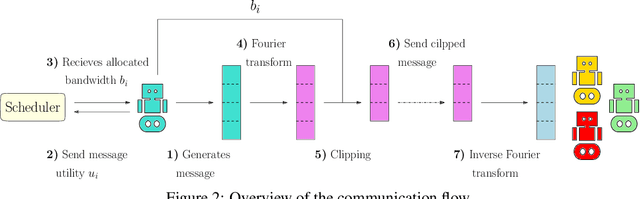
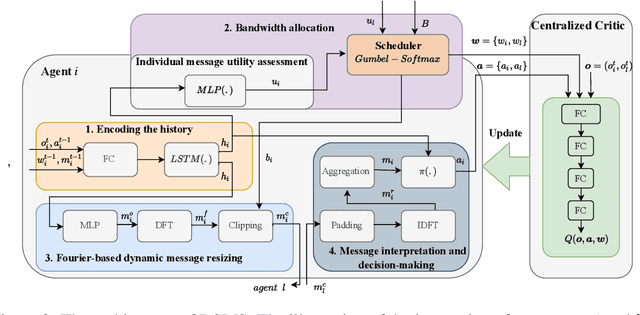
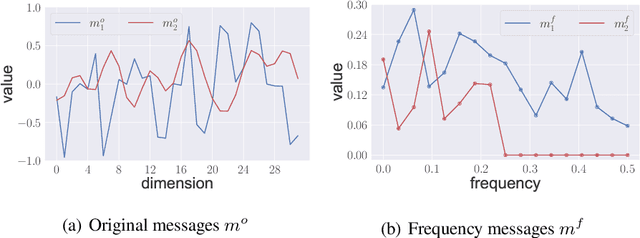
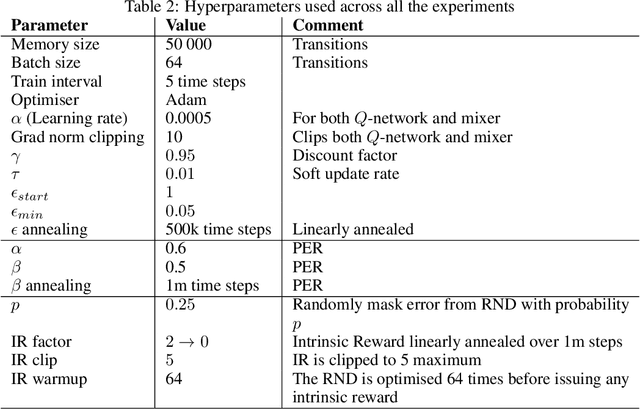
Communication plays a vital role in multi-agent systems, fostering collaboration and coordination. However, in real-world scenarios where communication is bandwidth-limited, existing multi-agent reinforcement learning (MARL) algorithms often provide agents with a binary choice: either transmitting a fixed number of bytes or no information at all. This limitation hinders the ability to effectively utilize the available bandwidth. To overcome this challenge, we present the Dynamic Size Message Scheduling (DSMS) method, which introduces a finer-grained approach to scheduling by considering the actual size of the information to be exchanged. Our contribution lies in adaptively adjusting message sizes using Fourier transform-based compression techniques, enabling agents to tailor their messages to match the allocated bandwidth while striking a balance between information loss and transmission efficiency. Receiving agents can reliably decompress the messages using the inverse Fourier transform. Experimental results demonstrate that DSMS significantly improves performance in multi-agent cooperative tasks by optimizing the utilization of bandwidth and effectively balancing information value.
Local Advantage Networks for Cooperative Multi-Agent Reinforcement Learning
Dec 23, 2021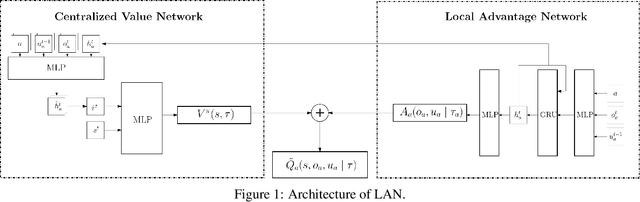
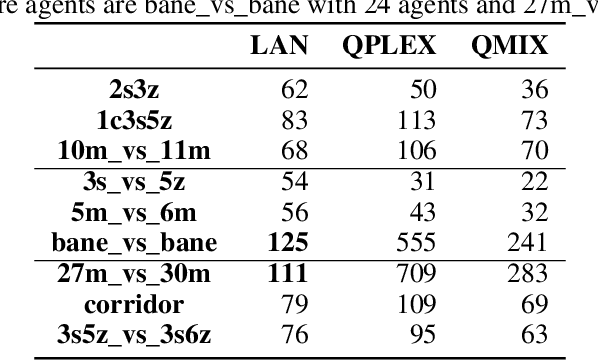
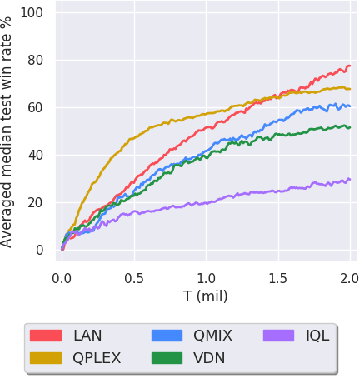

Multi-agent reinforcement learning (MARL) enables us to create adaptive agents in challenging environments, even when the agents have limited observation. Modern MARL methods have hitherto focused on finding factorized value functions. While this approach has proven successful, the resulting methods have convoluted network structures. We take a radically different approach, and build on the structure of independent Q-learners. Inspired by influence-based abstraction, we start from the observation that compact representations of the observation-action histories can be sufficient to learn close to optimal decentralized policies. Combining this observation with a dueling architecture, our algorithm, LAN, represents these policies as separate individual advantage functions w.r.t. a centralized critic. These local advantage networks condition only on a single agent's local observation-action history. The centralized value function conditions on the agents' representations as well as the full state of the environment. The value function, which is cast aside before execution, serves as a stabilizer that coordinates the learning and to formulate DQN targets during learning. In contrast with other methods, this enables LAN to keep the number of network parameters of its centralized network independent in the number of agents, without imposing additional constraints like monotonic value functions. When evaluated on the StarCraft multi-agent challenge benchmark, LAN shows state-of-the-art performance and scores more than 80% wins in two previously unsolved maps `corridor' and `3s5z_vs_3s6z', leading to an improvement of 10% over QPLEX on average performance on the 14 maps. Moreover when the number of agents becomes large, LAN uses significantly fewer parameters than QPLEX or even QMIX. We thus show that LAN's structure forms a key improvement that helps MARL methods remain scalable.