 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMAI Gym for Science: Training Liquid Foundation Models for Drug Discovery
Mar 03, 2026General-purpose large language models (LLMs) that rely on in-context learning do not reliably deliver the scientific understanding and performance required for drug discovery tasks. Simply increasing model size or introducing reasoning tokens does not yield significant performance gains. To address this gap, we introduce the MMAI Gym for Science, a one-stop shop molecular data formats and modalities as well as task-specific reasoning, training, and benchmarking recipes designed to teach foundation models the 'language of molecules' in order to solve practical drug discovery problems. We use MMAI Gym to train an efficient Liquid Foundation Model (LFM) for these applications, demonstrating that smaller, purpose-trained foundation models can outperform substantially larger general-purpose or specialist models on molecular benchmarks. Across essential drug discovery tasks - including molecular optimization, ADMET property prediction, retrosynthesis, drug-target activity prediction, and functional group reasoning - the resulting model achieves near specialist-level performance and, in the majority of settings, surpasses larger models, while remaining more efficient and broadly applicable in the domain.
CoPeP: Benchmarking Continual Pretraining for Protein Language Models
Mar 03, 2026Protein language models (pLMs) have recently gained significant attention for their ability to uncover relationships between sequence, structure, and function from evolutionary statistics, thereby accelerating therapeutic drug discovery. These models learn from large protein databases that are continuously updated by the biology community and whose dynamic nature motivates the application of continual learning, not only to keep up with the ever-growing data, but also as an opportunity to take advantage of the temporal meta-information that is created during this process. As a result, we introduce the Continual Pretraining of Protein Language Models (CoPeP) benchmark, a novel benchmark for evaluating continual learning approaches on pLMs. Specifically, we curate a sequence of protein datasets derived from the UniProt Knowledgebase spanning a decade and define metrics to assess pLM performance across 31 protein understanding tasks. We evaluate several methods from the continual learning literature, including replay, unlearning, and plasticity-based methods, some of which have never been applied to models and data of this scale. Our findings reveal that incorporating temporal meta-information improves perplexity by up to 7% even when compared to training on data from all tasks jointly. Moreover, even at scale, several continual learning methods outperform naive continual pretraining. The CoPeP benchmark offers an exciting opportunity to study these methods at scale in an impactful real-world application.
Squeezing More from the Stream : Learning Representation Online for Streaming Reinforcement Learning
Feb 10, 2026In streaming Reinforcement Learning (RL), transitions are observed and discarded immediately after a single update. While this minimizes resource usage for on-device applications, it makes agents notoriously sample-inefficient, since value-based losses alone struggle to extract meaningful representations from transient data. We propose extending Self-Predictive Representations (SPR) to the streaming pipeline to maximize the utility of every observed frame. However, due to the highly correlated samples induced by the streaming regime, naively applying this auxiliary loss results in training instabilities. Thus, we introduce orthogonal gradient updates relative to the momentum target and resolve gradient conflicts arising from streaming-specific optimizers. Validated across the Atari, MinAtar, and Octax suites, our approach systematically outperforms existing streaming baselines. Latent-space analysis, including t-SNE visualizations and effective-rank measurements, confirms that our method learns significantly richer representations, bridging the performance gap caused by the absence of a replay buffer, while remaining efficient enough to train on just a few CPU cores.
Just-in-time Episodic Feedback Hinter: Leveraging Offline Knowledge to Improve LLM Agents Adaptation
Oct 05, 2025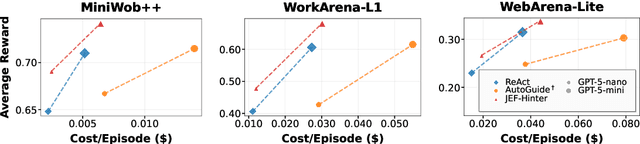
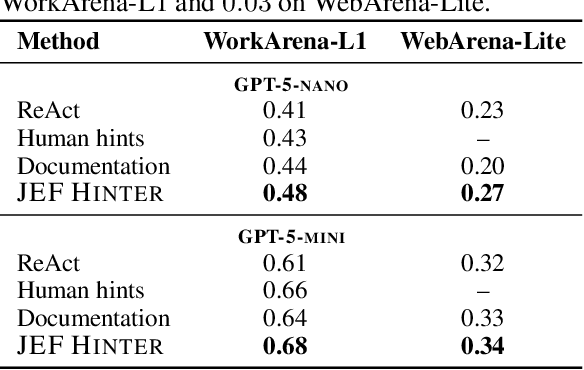
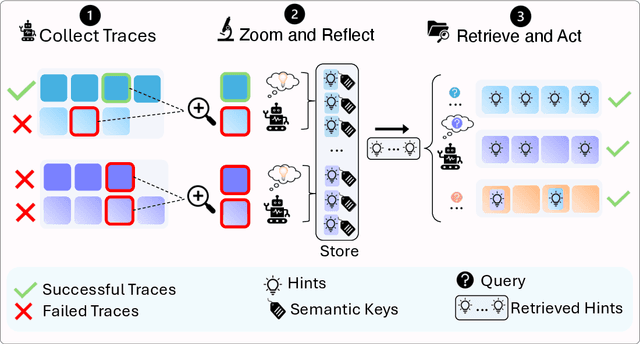
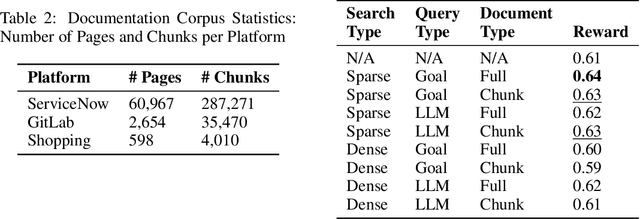
Large language model (LLM) agents perform well in sequential decision-making tasks, but improving them on unfamiliar domains often requires costly online interactions or fine-tuning on large expert datasets. These strategies are impractical for closed-source models and expensive for open-source ones, with risks of catastrophic forgetting. Offline trajectories offer reusable knowledge, yet demonstration-based methods struggle because raw traces are long, noisy, and tied to specific tasks. We present Just-in-time Episodic Feedback Hinter (JEF Hinter), an agentic system that distills offline traces into compact, context-aware hints. A zooming mechanism highlights decisive steps in long trajectories, capturing both strategies and pitfalls. Unlike prior methods, JEF Hinter leverages both successful and failed trajectories, extracting guidance even when only failure data is available, while supporting parallelized hint generation and benchmark-independent prompting. At inference, a retriever selects relevant hints for the current state, providing targeted guidance with transparency and traceability. Experiments on MiniWoB++, WorkArena-L1, and WebArena-Lite show that JEF Hinter consistently outperforms strong baselines, including human- and document-based hints.
A Generalist Hanabi Agent
Mar 17, 2025Traditional multi-agent reinforcement learning (MARL) systems can develop cooperative strategies through repeated interactions. However, these systems are unable to perform well on any other setting than the one they have been trained on, and struggle to successfully cooperate with unfamiliar collaborators. This is particularly visible in the Hanabi benchmark, a popular 2-to-5 player cooperative card-game which requires complex reasoning and precise assistance to other agents. Current MARL agents for Hanabi can only learn one specific game-setting (e.g., 2-player games), and play with the same algorithmic agents. This is in stark contrast to humans, who can quickly adjust their strategies to work with unfamiliar partners or situations. In this paper, we introduce Recurrent Replay Relevance Distributed DQN (R3D2), a generalist agent for Hanabi, designed to overcome these limitations. We reformulate the task using text, as language has been shown to improve transfer. We then propose a distributed MARL algorithm that copes with the resulting dynamic observation- and action-space. In doing so, our agent is the first that can play all game settings concurrently, and extend strategies learned from one setting to other ones. As a consequence, our agent also demonstrates the ability to collaborate with different algorithmic agents -- agents that are themselves unable to do so. The implementation code is available at: $\href{https://github.com/chandar-lab/R3D2-A-Generalist-Hanabi-Agent}{R3D2-A-Generalist-Hanabi-Agent}$
Divide and Conquer: Provably Unveiling the Pareto Front with Multi-Objective Reinforcement Learning
Feb 11, 2024A significant challenge in multi-objective reinforcement learning is obtaining a Pareto front of policies that attain optimal performance under different preferences. We introduce Iterated Pareto Referent Optimisation (IPRO), a principled algorithm that decomposes the task of finding the Pareto front into a sequence of single-objective problems for which various solution methods exist. This enables us to establish convergence guarantees while providing an upper bound on the distance to undiscovered Pareto optimal solutions at each step. Empirical evaluations demonstrate that IPRO matches or outperforms methods that require additional domain knowledge. By leveraging problem-specific single-objective solvers, our approach also holds promise for applications beyond multi-objective reinforcement learning, such as in pathfinding and optimisation.
Monte Carlo Tree Search Algorithms for Risk-Aware and Multi-Objective Reinforcement Learning
Dec 06, 2022In many risk-aware and multi-objective reinforcement learning settings, the utility of the user is derived from a single execution of a policy. In these settings, making decisions based on the average future returns is not suitable. For example, in a medical setting a patient may only have one opportunity to treat their illness. Making decisions using just the expected future returns -- known in reinforcement learning as the value -- cannot account for the potential range of adverse or positive outcomes a decision may have. Therefore, we should use the distribution over expected future returns differently to represent the critical information that the agent requires at decision time by taking both the future and accrued returns into consideration. In this paper, we propose two novel Monte Carlo tree search algorithms. Firstly, we present a Monte Carlo tree search algorithm that can compute policies for nonlinear utility functions (NLU-MCTS) by optimising the utility of the different possible returns attainable from individual policy executions, resulting in good policies for both risk-aware and multi-objective settings. Secondly, we propose a distributional Monte Carlo tree search algorithm (DMCTS) which extends NLU-MCTS. DMCTS computes an approximate posterior distribution over the utility of the returns, and utilises Thompson sampling during planning to compute policies in risk-aware and multi-objective settings. Both algorithms outperform the state-of-the-art in multi-objective reinforcement learning for the expected utility of the returns.
Pareto Conditioned Networks
Apr 11, 2022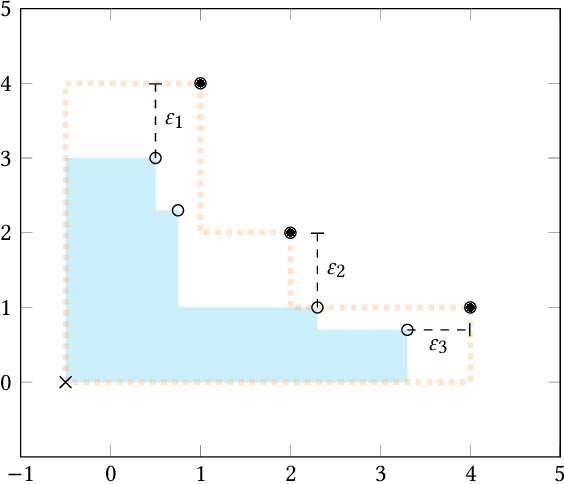

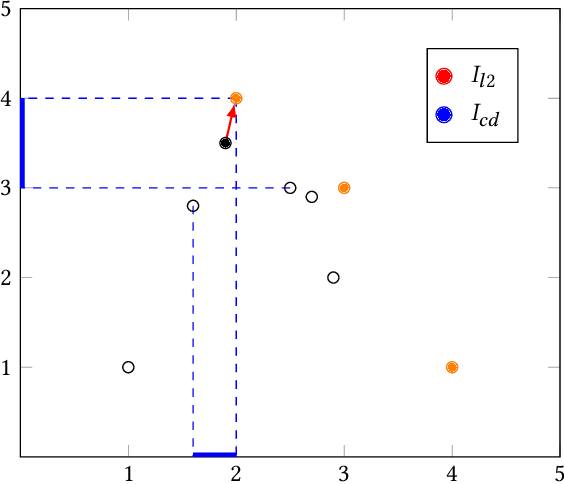
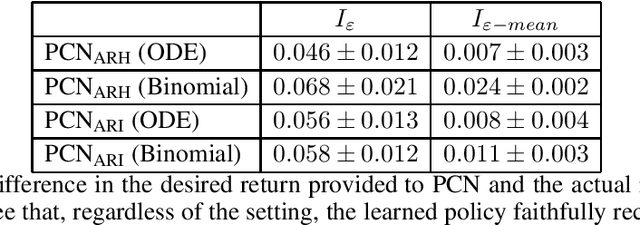
In multi-objective optimization, learning all the policies that reach Pareto-efficient solutions is an expensive process. The set of optimal policies can grow exponentially with the number of objectives, and recovering all solutions requires an exhaustive exploration of the entire state space. We propose Pareto Conditioned Networks (PCN), a method that uses a single neural network to encompass all non-dominated policies. PCN associates every past transition with its episode's return. It trains the network such that, when conditioned on this same return, it should reenact said transition. In doing so we transform the optimization problem into a classification problem. We recover a concrete policy by conditioning the network on the desired Pareto-efficient solution. Our method is stable as it learns in a supervised fashion, thus avoiding moving target issues. Moreover, by using a single network, PCN scales efficiently with the number of objectives. Finally, it makes minimal assumptions on the shape of the Pareto front, which makes it suitable to a wider range of problems than previous state-of-the-art multi-objective reinforcement learning algorithms.
Exploring the Pareto front of multi-objective COVID-19 mitigation policies using reinforcement learning
Apr 11, 2022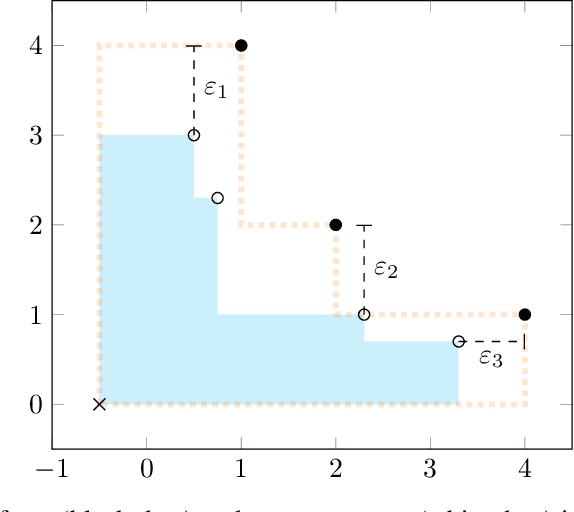

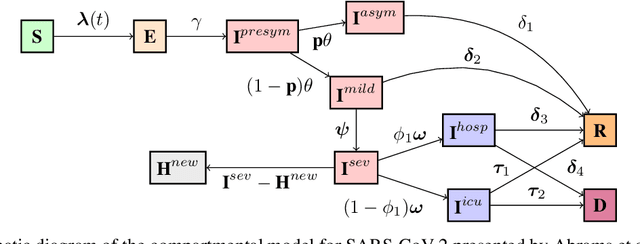
Infectious disease outbreaks can have a disruptive impact on public health and societal processes. As decision making in the context of epidemic mitigation is hard, reinforcement learning provides a methodology to automatically learn prevention strategies in combination with complex epidemic models. Current research focuses on optimizing policies w.r.t. a single objective, such as the pathogen's attack rate. However, as the mitigation of epidemics involves distinct, and possibly conflicting criteria (i.a., prevalence, mortality, morbidity, cost), a multi-objective approach is warranted to learn balanced policies. To lift this decision-making process to real-world epidemic models, we apply deep multi-objective reinforcement learning and build upon a state-of-the-art algorithm, Pareto Conditioned Networks (PCN), to learn a set of solutions that approximates the Pareto front of the decision problem. We consider the first wave of the Belgian COVID-19 epidemic, which was mitigated by a lockdown, and study different deconfinement strategies, aiming to minimize both COVID-19 cases (i.e., infections and hospitalizations) and the societal burden that is induced by the applied mitigation measures. We contribute a multi-objective Markov decision process that encapsulates the stochastic compartment model that was used to inform policy makers during the COVID-19 epidemic. As these social mitigation measures are implemented in a continuous action space that modulates the contact matrix of the age-structured epidemic model, we extend PCN to this setting. We evaluate the solution returned by PCN, and observe that it correctly learns to reduce the social burden whenever the hospitalization rates are sufficiently low. In this work, we thus show that multi-objective reinforcement learning is attainable in complex epidemiological models and provides essential insights to balance complex mitigation policies.
Local Advantage Networks for Cooperative Multi-Agent Reinforcement Learning
Dec 23, 2021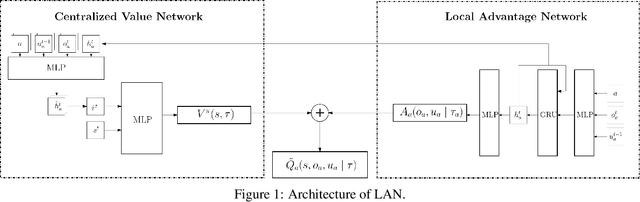
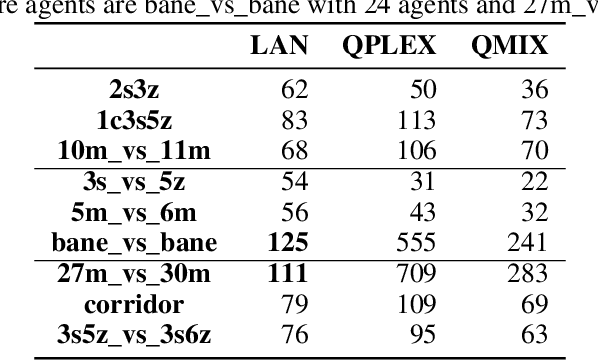
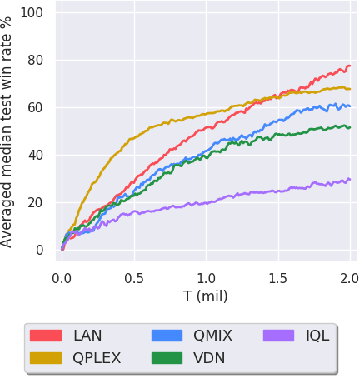

Multi-agent reinforcement learning (MARL) enables us to create adaptive agents in challenging environments, even when the agents have limited observation. Modern MARL methods have hitherto focused on finding factorized value functions. While this approach has proven successful, the resulting methods have convoluted network structures. We take a radically different approach, and build on the structure of independent Q-learners. Inspired by influence-based abstraction, we start from the observation that compact representations of the observation-action histories can be sufficient to learn close to optimal decentralized policies. Combining this observation with a dueling architecture, our algorithm, LAN, represents these policies as separate individual advantage functions w.r.t. a centralized critic. These local advantage networks condition only on a single agent's local observation-action history. The centralized value function conditions on the agents' representations as well as the full state of the environment. The value function, which is cast aside before execution, serves as a stabilizer that coordinates the learning and to formulate DQN targets during learning. In contrast with other methods, this enables LAN to keep the number of network parameters of its centralized network independent in the number of agents, without imposing additional constraints like monotonic value functions. When evaluated on the StarCraft multi-agent challenge benchmark, LAN shows state-of-the-art performance and scores more than 80% wins in two previously unsolved maps `corridor' and `3s5z_vs_3s6z', leading to an improvement of 10% over QPLEX on average performance on the 14 maps. Moreover when the number of agents becomes large, LAN uses significantly fewer parameters than QPLEX or even QMIX. We thus show that LAN's structure forms a key improvement that helps MARL methods remain scalable.