 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating COVID-19 vaccine allocation policies using Bayesian $m$-top exploration
Jan 30, 2023Individual-based epidemiological models support the study of fine-grained preventive measures, such as tailored vaccine allocation policies, in silico. As individual-based models are computationally intensive, it is pivotal to identify optimal strategies within a reasonable computational budget. Moreover, due to the high societal impact associated with the implementation of preventive strategies, uncertainty regarding decisions should be communicated to policy makers, which is naturally embedded in a Bayesian approach. We present a novel technique for evaluating vaccine allocation strategies using a multi-armed bandit framework in combination with a Bayesian anytime $m$-top exploration algorithm. $m$-top exploration allows the algorithm to learn $m$ policies for which it expects the highest utility, enabling experts to inspect this small set of alternative strategies, along with their quantified uncertainty. The anytime component provides policy advisors with flexibility regarding the computation time and the desired confidence, which is important as it is difficult to make this trade-off beforehand. We consider the Belgian COVID-19 epidemic using the individual-based model STRIDE, where we learn a set of vaccination policies that minimize the number of infections and hospitalisations. Through experiments we show that our method can efficiently identify the $m$-top policies, which is validated in a scenario where the ground truth is available. Finally, we explore how vaccination policies can best be organised under different contact reduction schemes. Through these experiments, we show that the top policies follow a clear trend regarding the prioritised age groups and assigned vaccine type, which provides insights for future vaccination campaigns.
Exploring the Pareto front of multi-objective COVID-19 mitigation policies using reinforcement learning
Apr 11, 2022

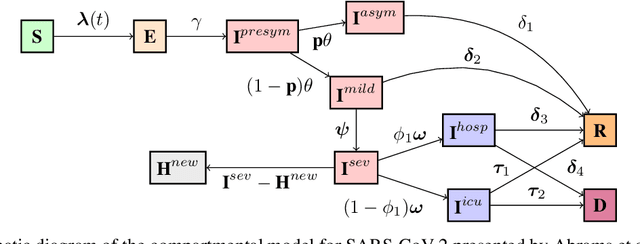
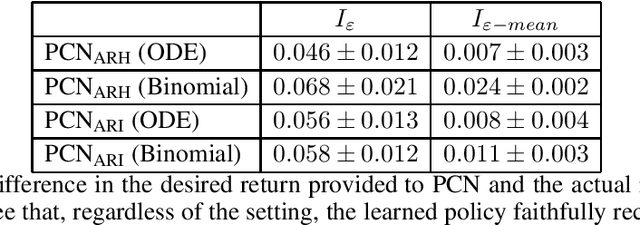
Infectious disease outbreaks can have a disruptive impact on public health and societal processes. As decision making in the context of epidemic mitigation is hard, reinforcement learning provides a methodology to automatically learn prevention strategies in combination with complex epidemic models. Current research focuses on optimizing policies w.r.t. a single objective, such as the pathogen's attack rate. However, as the mitigation of epidemics involves distinct, and possibly conflicting criteria (i.a., prevalence, mortality, morbidity, cost), a multi-objective approach is warranted to learn balanced policies. To lift this decision-making process to real-world epidemic models, we apply deep multi-objective reinforcement learning and build upon a state-of-the-art algorithm, Pareto Conditioned Networks (PCN), to learn a set of solutions that approximates the Pareto front of the decision problem. We consider the first wave of the Belgian COVID-19 epidemic, which was mitigated by a lockdown, and study different deconfinement strategies, aiming to minimize both COVID-19 cases (i.e., infections and hospitalizations) and the societal burden that is induced by the applied mitigation measures. We contribute a multi-objective Markov decision process that encapsulates the stochastic compartment model that was used to inform policy makers during the COVID-19 epidemic. As these social mitigation measures are implemented in a continuous action space that modulates the contact matrix of the age-structured epidemic model, we extend PCN to this setting. We evaluate the solution returned by PCN, and observe that it correctly learns to reduce the social burden whenever the hospitalization rates are sufficiently low. In this work, we thus show that multi-objective reinforcement learning is attainable in complex epidemiological models and provides essential insights to balance complex mitigation policies.