 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Guided Iterated Pareto Referent Optimisation for Accessible Route Planning
Apr 01, 2026We propose the Preference Guided Iterated Pareto Referent Optimisation (PG-IPRO) for urban route planning for people with different accessibility requirements and preferences. With this algorithm the user can interact with the system by giving feedback on a route, i.e., the user can say which objective should be further minimized, or conversely can be relaxed. This leads to intuitive user interaction, that is especially effective during early iterations compared to information-gain-based interaction. Furthermore, due to PG-IPRO's iterative nature, the full set of alternative, possibly optimal policies (the Pareto front), is never computed, leading to higher computational efficiency and shorter waiting times for users.
Probabilistic Wind Power Forecasting with Tree-Based Machine Learning and Weather Ensembles
Feb 13, 2026Accurate production forecasts are essential to continue facilitating the integration of renewable energy sources into the power grid. This paper illustrates how to obtain probabilistic day-ahead forecasts of wind power generation via gradient boosting trees using an ensemble of weather forecasts. To this end, we perform a comparative analysis across three state-of-the-art probabilistic prediction methods-conformalised quantile regression, natural gradient boosting and conditional diffusion models-all of which can be combined with tree-based machine learning. The methods are validated using four years of data for all wind farms present within the Belgian offshore zone. Additionally, the point forecasts are benchmarked against deterministic engineering methods, using either the power curve or an advanced approach incorporating a calibrated analytical wake model. The experimental results show that the machine learning methods improve the mean absolute error by up to 53% and 33% compared to the power curve and the calibrated wake model. Considering the three probabilistic prediction methods, the conditional diffusion model is found to yield the best overall probabilistic and point estimate of wind power generation. Moreover, the findings suggest that the use of an ensemble of weather forecasts can improve point forecast accuracy by up to 23%.
Explainable RL Policies by Distilling to Locally-Specialized Linear Policies with Voronoi State Partitioning
Nov 17, 2025Deep Reinforcement Learning is one of the state-of-the-art methods for producing near-optimal system controllers. However, deep RL algorithms train a deep neural network, that lacks transparency, which poses challenges when the controller has to meet regulations, or foster trust. To alleviate this, one could transfer the learned behaviour into a model that is human-readable by design using knowledge distilla- tion. Often this is done with a single model which mimics the original model on average but could struggle in more dynamic situations. A key challenge is that this simpler model should have the right balance be- tween flexibility and complexity or right balance between balance bias and accuracy. We propose a new model-agnostic method to divide the state space into regions where a simplified, human-understandable model can operate in. In this paper, we use Voronoi partitioning to find regions where linear models can achieve similar performance to the original con- troller. We evaluate our approach on a gridworld environment and a classic control task. We observe that our proposed distillation to locally- specialized linear models produces policies that are explainable and show that the distillation matches or even slightly outperforms the black-box policy they are distilled from.
* Accepted for BNAIC/BeNeLearn 2025
Automated Behavior Planning for Fruit Tree Pruning via Redundant Robot Manipulators: Addressing the Behavior Planning Challenge
Oct 14, 2025Pruning is an essential agricultural practice for orchards. Proper pruning can promote healthier growth and optimize fruit production throughout the orchard's lifespan. Robot manipulators have been developed as an automated solution for this repetitive task, which typically requires seasonal labor with specialized skills. While previous research has primarily focused on the challenges of perception, the complexities of manipulation are often overlooked. These challenges involve planning and control in both joint and Cartesian spaces to guide the end-effector through intricate, obstructive branches. Our work addresses the behavior planning challenge for a robotic pruning system, which entails a multi-level planning problem in environments with complex collisions. In this paper, we formulate the planning problem for a high-dimensional robotic arm in a pruning scenario, investigate the system's intrinsic redundancies, and propose a comprehensive pruning workflow that integrates perception, modeling, and holistic planning. In our experiments, we demonstrate that more comprehensive planning methods can significantly enhance the performance of the robotic manipulator. Finally, we implement the proposed workflow on a real-world robot. As a result, this work complements previous efforts on robotic pruning and motivates future research and development in planning for pruning applications.
Inclusive Fitness as a Key Step Towards More Advanced Social Behaviors in Multi-Agent Reinforcement Learning Settings
Oct 14, 2025The competitive and cooperative forces of natural selection have driven the evolution of intelligence for millions of years, culminating in nature's vast biodiversity and the complexity of human minds. Inspired by this process, we propose a novel multi-agent reinforcement learning framework where each agent is assigned a genotype and where reward functions are modelled after the concept of inclusive fitness. An agent's genetic material may be shared with other agents, and our inclusive reward function naturally accounts for this. We study the resulting social dynamics in two types of network games with prisoner's dilemmas and find that our results align with well-established principles from biology, such as Hamilton's rule. Furthermore, we outline how this framework can extend to more open-ended environments with spatial and temporal structure, finite resources, and evolving populations. We hypothesize the emergence of an arms race of strategies, where each new strategy is a gradual improvement over earlier adaptations of other agents, effectively producing a multi-agent autocurriculum analogous to biological evolution. In contrast to the binary team-based structures prevalent in earlier research, our gene-based reward structure introduces a spectrum of cooperation ranging from full adversity to full cooperativeness based on genetic similarity, enabling unique non team-based social dynamics. For example, one agent having a mutual cooperative relationship with two other agents, while the two other agents behave adversarially towards each other. We argue that incorporating inclusive fitness in agents provides a foundation for the emergence of more strategically advanced and socially intelligent agents.
Fairness-Aware Reinforcement Learning (FAReL): A Framework for Transparent and Balanced Sequential Decision-Making
Sep 26, 2025Equity in real-world sequential decision problems can be enforced using fairness-aware methods. Therefore, we require algorithms that can make suitable and transparent trade-offs between performance and the desired fairness notions. As the desired performance-fairness trade-off is hard to specify a priori, we propose a framework where multiple trade-offs can be explored. Insights provided by the reinforcement learning algorithm regarding the obtainable performance-fairness trade-offs can then guide stakeholders in selecting the most appropriate policy. To capture fairness, we propose an extended Markov decision process, $f$MDP, that explicitly encodes individuals and groups. Given this $f$MDP, we formalise fairness notions in the context of sequential decision problems and formulate a fairness framework that computes fairness measures over time. We evaluate our framework in two scenarios with distinct fairness requirements: job hiring, where strong teams must be composed while treating applicants equally, and fraud detection, where fraudulent transactions must be detected while ensuring the burden on customers is fairly distributed. We show that our framework learns policies that are more fair across multiple scenarios, with only minor loss in performance reward. Moreover, we observe that group and individual fairness notions do not necessarily imply one another, highlighting the benefit of our framework in settings where both fairness types are desired. Finally, we provide guidelines on how to apply this framework across different problem settings.
Explainability in Context: A Multilevel Framework Aligning AI Explanations with Stakeholder with LLMs
Jun 06, 2025The growing application of artificial intelligence in sensitive domains has intensified the demand for systems that are not only accurate but also explainable and trustworthy. Although explainable AI (XAI) methods have proliferated, many do not consider the diverse audiences that interact with AI systems: from developers and domain experts to end-users and society. This paper addresses how trust in AI is influenced by the design and delivery of explanations and proposes a multilevel framework that aligns explanations with the epistemic, contextual, and ethical expectations of different stakeholders. The framework consists of three layers: algorithmic and domain-based, human-centered, and social explainability. We highlight the emerging role of Large Language Models (LLMs) in enhancing the social layer by generating accessible, natural language explanations. Through illustrative case studies, we demonstrate how this approach facilitates technical fidelity, user engagement, and societal accountability, reframing XAI as a dynamic, trust-building process.
Explainable AI Based Diagnosis of Poisoning Attacks in Evolutionary Swarms
May 02, 2025Swarming systems, such as for example multi-drone networks, excel at cooperative tasks like monitoring, surveillance, or disaster assistance in critical environments, where autonomous agents make decentralized decisions in order to fulfill team-level objectives in a robust and efficient manner. Unfortunately, team-level coordinated strategies in the wild are vulnerable to data poisoning attacks, resulting in either inaccurate coordination or adversarial behavior among the agents. To address this challenge, we contribute a framework that investigates the effects of such data poisoning attacks, using explainable AI methods. We model the interaction among agents using evolutionary intelligence, where an optimal coalition strategically emerges to perform coordinated tasks. Then, through a rigorous evaluation, the swarm model is systematically poisoned using data manipulation attacks. We showcase the applicability of explainable AI methods to quantify the effects of poisoning on the team strategy and extract footprint characterizations that enable diagnosing. Our findings indicate that when the model is poisoned above 10%, non-optimal strategies resulting in inefficient cooperation can be identified.
* To appear in short form in Genetic and Evolutionary Computation Conference (GECCO '25 Companion), 2025
Human-Readable Programs as Actors of Reinforcement Learning Agents Using Critic-Moderated Evolution
Oct 29, 2024With Deep Reinforcement Learning (DRL) being increasingly considered for the control of real-world systems, the lack of transparency of the neural network at the core of RL becomes a concern. Programmatic Reinforcement Learning (PRL) is able to to create representations of this black-box in the form of source code, not only increasing the explainability of the controller but also allowing for user adaptations. However, these methods focus on distilling a black-box policy into a program and do so after learning using the Mean Squared Error between produced and wanted behaviour, discarding other elements of the RL algorithm. The distilled policy may therefore perform significantly worse than the black-box learned policy. In this paper, we propose to directly learn a program as the policy of an RL agent. We build on TD3 and use its critics as the basis of the objective function of a genetic algorithm that syntheses the program. Our approach builds the program during training, as opposed to after the fact. This steers the program to actual high rewards, instead of a simple Mean Squared Error. Also, our approach leverages the TD3 critics to achieve high sample-efficiency, as opposed to pure genetic methods that rely on Monte-Carlo evaluations. Our experiments demonstrate the validity, explainability and sample-efficiency of our approach in a simple gridworld environment.
Online Planning in POMDPs with State-Requests
Jul 26, 2024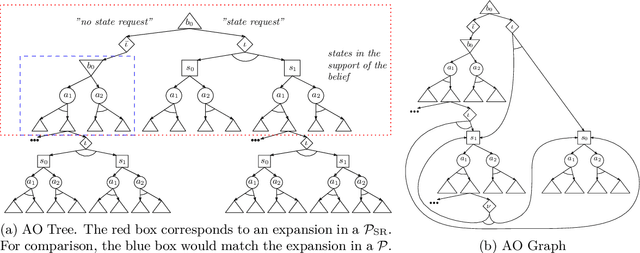
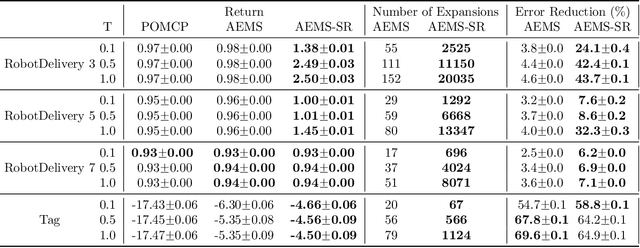
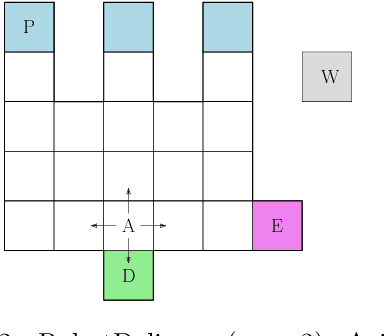
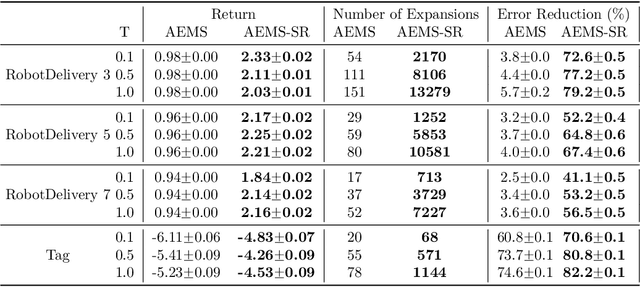
In key real-world problems, full state information is sometimes available but only at a high cost, like activating precise yet energy-intensive sensors or consulting humans, thereby compelling the agent to operate under partial observability. For this scenario, we propose AEMS-SR (Anytime Error Minimization Search with State Requests), a principled online planning algorithm tailored for POMDPs with state requests. By representing the search space as a graph instead of a tree, AEMS-SR avoids the exponential growth of the search space originating from state requests. Theoretical analysis demonstrates AEMS-SR's $\varepsilon$-optimality, ensuring solution quality, while empirical evaluations illustrate its effectiveness compared with AEMS and POMCP, two SOTA online planning algorithms. AEMS-SR enables efficient planning in domains characterized by partial observability and costly state requests offering practical benefits across various applications.