 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient Federated Chain: Transforming Blockchain Consensus into an Active Defense Layer for Federated Learning
Feb 25, 2026Federated Learning (FL) has emerged as a key paradigm for building Trustworthy AI systems by enabling privacy-preserving, decentralized model training. However, FL is highly susceptible to adversarial attacks that compromise model integrity and data confidentiality, a vulnerability exacerbated by the fact that conventional data inspection methods are incompatible with its decentralized design. While integrating FL with Blockchain technology has been proposed to address some limitations, its potential for mitigating adversarial attacks remains largely unexplored. This paper introduces Resilient Federated Chain (RFC), a novel blockchain-enabled FL framework designed specifically to enhance resilience against such threats. RFC builds upon the existing Proof of Federated Learning architecture by repurposing the redundancy of its Pooled Mining mechanism as an active defense layer that can be combined with robust aggregation rules. Furthermore, the framework introduces a flexible evaluation function in its consensus mechanism, allowing for adaptive defense against different attack strategies. Extensive experimental evaluation on image classification tasks under various adversarial scenarios, demonstrates that RFC significantly improves robustness compared to baseline methods, providing a viable solution for securing decentralized learning environments.
Featured Reproducing Kernel Banach Spaces for Learning and Neural Networks
Feb 06, 2026Reproducing kernel Hilbert spaces provide a foundational framework for kernel-based learning, where regularization and interpolation problems admit finite-dimensional solutions through classical representer theorems. Many modern learning models, however -- including fixed-architecture neural networks equipped with non-quadratic norms -- naturally give rise to non-Hilbertian geometries that fall outside this setting. In Banach spaces, continuity of point-evaluation functionals alone is insufficient to guarantee feature representations or kernel-based learning formulations. In this work, we develop a functional-analytic framework for learning in Banach spaces based on the notion of featured reproducing kernel Banach spaces. We identify the precise structural conditions under which feature maps, kernel constructions, and representer-type results can be recovered beyond the Hilbertian regime. Within this framework, supervised learning is formulated as a minimal-norm interpolation or regularization problem, and existence results together with conditional representer theorems are established. We further extend the theory to vector-valued featured reproducing kernel Banach spaces and show that fixed-architecture neural networks naturally induce special instances of such spaces. This provides a unified function-space perspective on kernel methods and neural networks and clarifies when kernel-based learning principles extend beyond reproducing kernel Hilbert spaces.
SeNeDiF-OOD: Semantic Nested Dichotomy Fusion for Out-of-Distribution Detection Methodology in Open-World Classification. A Case Study on Monument Style Classification
Jan 27, 2026Out-of-distribution (OOD) detection is a fundamental requirement for the reliable deployment of artificial intelligence applications in open-world environments. However, addressing the heterogeneous nature of OOD data, ranging from low-level corruption to semantic shifts, remains a complex challenge that single-stage detectors often fail to resolve. To address this issue, we propose SeNeDiF-OOD, a novel methodology based on Semantic Nested Dichotomy Fusion. This framework decomposes the detection task into a hierarchical structure of binary fusion nodes, where each layer is designed to integrate decision boundaries aligned with specific levels of semantic abstraction. To validate the proposed framework, we present a comprehensive case study using MonuMAI, a real-world architectural style recognition system exposed to an open environment. This application faces a diverse range of inputs, including non-monument images, unknown architectural styles, and adversarial attacks, making it an ideal testbed for our proposal. Through extensive experimental evaluation in this domain, results demonstrate that our hierarchical fusion methodology significantly outperforms traditional baselines, effectively filtering these diverse OOD categories while preserving in-distribution performance.
DenoGrad: Deep Gradient Denoising Framework for Enhancing the Performance of Interpretable AI Models
Nov 13, 2025The performance of Machine Learning (ML) models, particularly those operating within the Interpretable Artificial Intelligence (Interpretable AI) framework, is significantly affected by the presence of noise in both training and production data. Denoising has therefore become a critical preprocessing step, typically categorized into instance removal and instance correction techniques. However, existing correction approaches often degrade performance or oversimplify the problem by altering the original data distribution. This leads to unrealistic scenarios and biased models, which is particularly problematic in contexts where interpretable AI models are employed, as their interpretability depends on the fidelity of the underlying data patterns. In this paper, we argue that defining noise independently of the solution may be ineffective, as its nature can vary significantly across tasks and datasets. Using a task-specific high quality solution as a reference can provide a more precise and adaptable noise definition. To this end, we propose DenoGrad, a novel Gradient-based instance Denoiser framework that leverages gradients from an accurate Deep Learning (DL) model trained on the target data -- regardless of the specific task -- to detect and adjust noisy samples. Unlike conventional approaches, DenoGrad dynamically corrects noisy instances, preserving problem's data distribution, and improving AI models robustness. DenoGrad is validated on both tabular and time series datasets under various noise settings against the state-of-the-art. DenoGrad outperforms existing denoising strategies, enhancing the performance of interpretable IA models while standing out as the only high quality approach that preserves the original data distribution.
Triadic Fusion of Cognitive, Functional, and Causal Dimensions for Explainable LLMs: The TAXAL Framework
Sep 05, 2025



Large Language Models (LLMs) are increasingly being deployed in high-risk domains where opacity, bias, and instability undermine trust and accountability. Traditional explainability methods, focused on surface outputs, do not capture the reasoning pathways, planning logic, and systemic impacts of agentic LLMs. We introduce TAXAL (Triadic Alignment for eXplainability in Agentic LLMs), a triadic fusion framework that unites three complementary dimensions: cognitive (user understanding), functional (practical utility), and causal (faithful reasoning). TAXAL provides a unified, role-sensitive foundation for designing, evaluating, and deploying explanations in diverse sociotechnical settings. Our analysis synthesizes existing methods, ranging from post-hoc attribution and dialogic interfaces to explanation-aware prompting, and situates them within the TAXAL triadic fusion model. We further demonstrate its applicability through case studies in law, education, healthcare, and public services, showing how explanation strategies adapt to institutional constraints and stakeholder roles. By combining conceptual clarity with design patterns and deployment pathways, TAXAL advances explainability as a technical and sociotechnical practice, supporting trustworthy and context-sensitive LLM applications in the era of agentic AI.
Explainability in Context: A Multilevel Framework Aligning AI Explanations with Stakeholder with LLMs
Jun 06, 2025The growing application of artificial intelligence in sensitive domains has intensified the demand for systems that are not only accurate but also explainable and trustworthy. Although explainable AI (XAI) methods have proliferated, many do not consider the diverse audiences that interact with AI systems: from developers and domain experts to end-users and society. This paper addresses how trust in AI is influenced by the design and delivery of explanations and proposes a multilevel framework that aligns explanations with the epistemic, contextual, and ethical expectations of different stakeholders. The framework consists of three layers: algorithmic and domain-based, human-centered, and social explainability. We highlight the emerging role of Large Language Models (LLMs) in enhancing the social layer by generating accessible, natural language explanations. Through illustrative case studies, we demonstrate how this approach facilitates technical fidelity, user engagement, and societal accountability, reframing XAI as a dynamic, trust-building process.
Addressing Data Quality Decompensation in Federated Learning via Dynamic Client Selection
May 27, 2025



In cross-silo Federated Learning (FL), client selection is critical to ensure high model performance, yet it remains challenging due to data quality decompensation, budget constraints, and incentive compatibility. As training progresses, these factors exacerbate client heterogeneity and degrade global performance. Most existing approaches treat these challenges in isolation, making jointly optimizing multiple factors difficult. To address this, we propose Shapley-Bid Reputation Optimized Federated Learning (SBRO-FL), a unified framework integrating dynamic bidding, reputation modeling, and cost-aware selection. Clients submit bids based on their perceived data quality, and their contributions are evaluated using Shapley values to quantify their marginal impact on the global model. A reputation system, inspired by prospect theory, captures historical performance while penalizing inconsistency. The client selection problem is formulated as a 0-1 integer program that maximizes reputation-weighted utility under budget constraints. Experiments on FashionMNIST, EMNIST, CIFAR-10, and SVHN datasets show that SBRO-FL improves accuracy, convergence speed, and robustness, even in adversarial and low-bid interference scenarios. Our results highlight the importance of balancing data reliability, incentive compatibility, and cost efficiency to enable scalable and trustworthy FL deployments.
A Domain-Based Taxonomy of Jailbreak Vulnerabilities in Large Language Models
Apr 07, 2025The study of large language models (LLMs) is a key area in open-world machine learning. Although LLMs demonstrate remarkable natural language processing capabilities, they also face several challenges, including consistency issues, hallucinations, and jailbreak vulnerabilities. Jailbreaking refers to the crafting of prompts that bypass alignment safeguards, leading to unsafe outputs that compromise the integrity of LLMs. This work specifically focuses on the challenge of jailbreak vulnerabilities and introduces a novel taxonomy of jailbreak attacks grounded in the training domains of LLMs. It characterizes alignment failures through generalization, objectives, and robustness gaps. Our primary contribution is a perspective on jailbreak, framed through the different linguistic domains that emerge during LLM training and alignment. This viewpoint highlights the limitations of existing approaches and enables us to classify jailbreak attacks on the basis of the underlying model deficiencies they exploit. Unlike conventional classifications that categorize attacks based on prompt construction methods (e.g., prompt templating), our approach provides a deeper understanding of LLM behavior. We introduce a taxonomy with four categories -- mismatched generalization, competing objectives, adversarial robustness, and mixed attacks -- offering insights into the fundamental nature of jailbreak vulnerabilities. Finally, we present key lessons derived from this taxonomic study.
An overview of model uncertainty and variability in LLM-based sentiment analysis. Challenges, mitigation strategies and the role of explainability
Apr 06, 2025

Large Language Models (LLMs) have significantly advanced sentiment analysis, yet their inherent uncertainty and variability pose critical challenges to achieving reliable and consistent outcomes. This paper systematically explores the Model Variability Problem (MVP) in LLM-based sentiment analysis, characterized by inconsistent sentiment classification, polarization, and uncertainty arising from stochastic inference mechanisms, prompt sensitivity, and biases in training data. We analyze the core causes of MVP, presenting illustrative examples and a case study to highlight its impact. In addition, we investigate key challenges and mitigation strategies, paying particular attention to the role of temperature as a driver of output randomness and emphasizing the crucial role of explainability in improving transparency and user trust. By providing a structured perspective on stability, reproducibility, and trustworthiness, this study helps develop more reliable, explainable, and robust sentiment analysis models, facilitating their deployment in high-stakes domains such as finance, healthcare, and policymaking, among others.
STOOD-X methodology: using statistical nonparametric test for OOD Detection Large-Scale datasets enhanced with explainability
Apr 03, 2025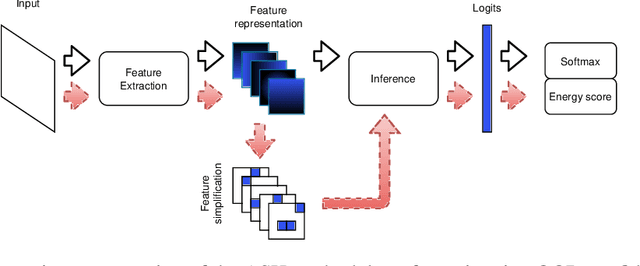

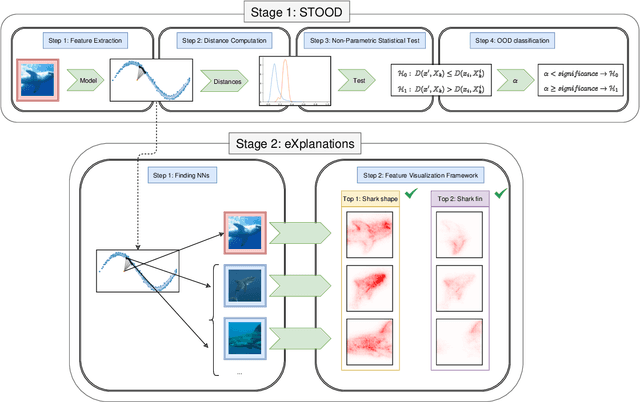

Out-of-Distribution (OOD) detection is a critical task in machine learning, particularly in safety-sensitive applications where model failures can have serious consequences. However, current OOD detection methods often suffer from restrictive distributional assumptions, limited scalability, and a lack of interpretability. To address these challenges, we propose STOOD-X, a two-stage methodology that combines a Statistical nonparametric Test for OOD Detection with eXplainability enhancements. In the first stage, STOOD-X uses feature-space distances and a Wilcoxon-Mann-Whitney test to identify OOD samples without assuming a specific feature distribution. In the second stage, it generates user-friendly, concept-based visual explanations that reveal the features driving each decision, aligning with the BLUE XAI paradigm. Through extensive experiments on benchmark datasets and multiple architectures, STOOD-X achieves competitive performance against state-of-the-art post hoc OOD detectors, particularly in high-dimensional and complex settings. In addition, its explainability framework enables human oversight, bias detection, and model debugging, fostering trust and collaboration between humans and AI systems. The STOOD-X methodology therefore offers a robust, explainable, and scalable solution for real-world OOD detection tasks.