 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriadic Fusion of Cognitive, Functional, and Causal Dimensions for Explainable LLMs: The TAXAL Framework
Sep 05, 2025



Large Language Models (LLMs) are increasingly being deployed in high-risk domains where opacity, bias, and instability undermine trust and accountability. Traditional explainability methods, focused on surface outputs, do not capture the reasoning pathways, planning logic, and systemic impacts of agentic LLMs. We introduce TAXAL (Triadic Alignment for eXplainability in Agentic LLMs), a triadic fusion framework that unites three complementary dimensions: cognitive (user understanding), functional (practical utility), and causal (faithful reasoning). TAXAL provides a unified, role-sensitive foundation for designing, evaluating, and deploying explanations in diverse sociotechnical settings. Our analysis synthesizes existing methods, ranging from post-hoc attribution and dialogic interfaces to explanation-aware prompting, and situates them within the TAXAL triadic fusion model. We further demonstrate its applicability through case studies in law, education, healthcare, and public services, showing how explanation strategies adapt to institutional constraints and stakeholder roles. By combining conceptual clarity with design patterns and deployment pathways, TAXAL advances explainability as a technical and sociotechnical practice, supporting trustworthy and context-sensitive LLM applications in the era of agentic AI.
A Domain-Based Taxonomy of Jailbreak Vulnerabilities in Large Language Models
Apr 07, 2025The study of large language models (LLMs) is a key area in open-world machine learning. Although LLMs demonstrate remarkable natural language processing capabilities, they also face several challenges, including consistency issues, hallucinations, and jailbreak vulnerabilities. Jailbreaking refers to the crafting of prompts that bypass alignment safeguards, leading to unsafe outputs that compromise the integrity of LLMs. This work specifically focuses on the challenge of jailbreak vulnerabilities and introduces a novel taxonomy of jailbreak attacks grounded in the training domains of LLMs. It characterizes alignment failures through generalization, objectives, and robustness gaps. Our primary contribution is a perspective on jailbreak, framed through the different linguistic domains that emerge during LLM training and alignment. This viewpoint highlights the limitations of existing approaches and enables us to classify jailbreak attacks on the basis of the underlying model deficiencies they exploit. Unlike conventional classifications that categorize attacks based on prompt construction methods (e.g., prompt templating), our approach provides a deeper understanding of LLM behavior. We introduce a taxonomy with four categories -- mismatched generalization, competing objectives, adversarial robustness, and mixed attacks -- offering insights into the fundamental nature of jailbreak vulnerabilities. Finally, we present key lessons derived from this taxonomic study.
An overview of model uncertainty and variability in LLM-based sentiment analysis. Challenges, mitigation strategies and the role of explainability
Apr 06, 2025

Large Language Models (LLMs) have significantly advanced sentiment analysis, yet their inherent uncertainty and variability pose critical challenges to achieving reliable and consistent outcomes. This paper systematically explores the Model Variability Problem (MVP) in LLM-based sentiment analysis, characterized by inconsistent sentiment classification, polarization, and uncertainty arising from stochastic inference mechanisms, prompt sensitivity, and biases in training data. We analyze the core causes of MVP, presenting illustrative examples and a case study to highlight its impact. In addition, we investigate key challenges and mitigation strategies, paying particular attention to the role of temperature as a driver of output randomness and emphasizing the crucial role of explainability in improving transparency and user trust. By providing a structured perspective on stability, reproducibility, and trustworthiness, this study helps develop more reliable, explainable, and robust sentiment analysis models, facilitating their deployment in high-stakes domains such as finance, healthcare, and policymaking, among others.
FLEX: FLEXible Federated Learning Framework
Apr 09, 2024



In the realm of Artificial Intelligence (AI), the need for privacy and security in data processing has become paramount. As AI applications continue to expand, the collection and handling of sensitive data raise concerns about individual privacy protection. Federated Learning (FL) emerges as a promising solution to address these challenges by enabling decentralized model training on local devices, thus preserving data privacy. This paper introduces FLEX: a FLEXible Federated Learning Framework designed to provide maximum flexibility in FL research experiments. By offering customizable features for data distribution, privacy parameters, and communication strategies, FLEX empowers researchers to innovate and develop novel FL techniques. The framework also includes libraries for specific FL implementations including: (1) anomalies, (2) blockchain, (3) adversarial attacks and defences, (4) natural language processing and (5) decision trees, enhancing its versatility and applicability in various domains. Overall, FLEX represents a significant advancement in FL research, facilitating the development of robust and efficient FL applications.
An Interpretable Client Decision Tree Aggregation process for Federated Learning
Apr 03, 2024


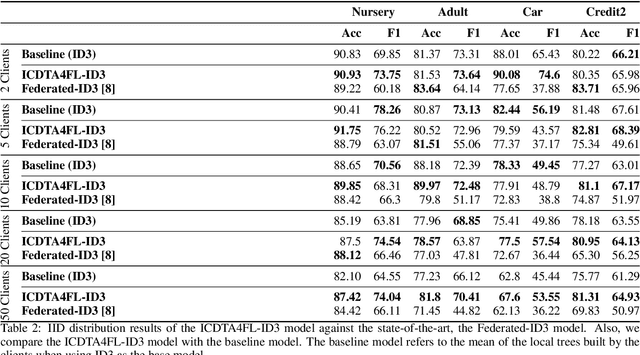
Trustworthy Artificial Intelligence solutions are essential in today's data-driven applications, prioritizing principles such as robustness, safety, transparency, explainability, and privacy among others. This has led to the emergence of Federated Learning as a solution for privacy and distributed machine learning. While decision trees, as self-explanatory models, are ideal for collaborative model training across multiple devices in resource-constrained environments such as federated learning environments for injecting interpretability in these models. Decision tree structure makes the aggregation in a federated learning environment not trivial. They require techniques that can merge their decision paths without introducing bias or overfitting while keeping the aggregated decision trees robust and generalizable. In this paper, we propose an Interpretable Client Decision Tree Aggregation process for Federated Learning scenarios that keeps the interpretability and the precision of the base decision trees used for the aggregation. This model is based on aggregating multiple decision paths of the decision trees and can be used on different decision tree types, such as ID3 and CART. We carry out the experiments within four datasets, and the analysis shows that the tree built with the model improves the local models, and outperforms the state-of-the-art.
Large language models for crowd decision making based on prompt design strategies using ChatGPT: models, analysis and challenges
Mar 22, 2024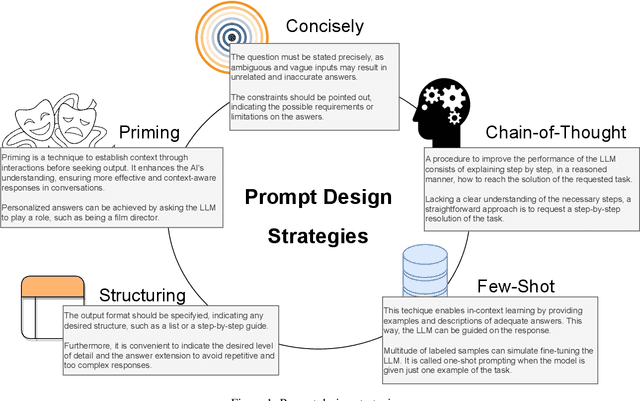



Social Media and Internet have the potential to be exploited as a source of opinion to enrich Decision Making solutions. Crowd Decision Making (CDM) is a methodology able to infer opinions and decisions from plain texts, such as reviews published in social media platforms, by means of Sentiment Analysis. Currently, the emergence and potential of Large Language Models (LLMs) lead us to explore new scenarios of automatically understand written texts, also known as natural language processing. This paper analyzes the use of ChatGPT based on prompt design strategies to assist in CDM processes to extract opinions and make decisions. We integrate ChatGPT in CDM processes as a flexible tool that infer the opinions expressed in texts, providing numerical or linguistic evaluations where the decision making models are based on the prompt design strategies. We include a multi-criteria decision making scenario with a category ontology for criteria. We also consider ChatGPT as an end-to-end CDM model able to provide a general opinion and score on the alternatives. We conduct empirical experiments on real data extracted from TripAdvisor, the TripR-2020Large dataset. The analysis of results show a promising branch for developing quality decision making models using ChatGPT. Finally, we discuss the challenges of consistency, sensitivity and explainability associated to the use of LLMs in CDM processes, raising open questions for future studies.
Design and consensus content validity of the questionnaire for b-learning education: A 2-Tuple Fuzzy Linguistic Delphi based Decision Support Tool
Feb 01, 2024Classic Delphi and Fuzzy Delphi methods are used to test content validity of data collection tools such as questionnaires. Fuzzy Delphi takes the opinion issued by judges from a linguistic perspective reducing ambiguity in opinions by using fuzzy numbers. We propose an extension named 2-Tuple Fuzzy Linguistic Delphi method to deal with scenarios in which judges show different expertise degrees by using fuzzy multigranular semantics of the linguistic terms and to obtain intermediate and final results expressed by 2-tuple linguistic values. The key idea of our proposal is to validate the full questionnaire by means of the evaluation of its parts, defining the validity of each item as a Decision Making problem. Taking the opinion of experts, we measure the degree of consensus, the degree of consistency, and the linguistic score of each item, in order to detect those items that affect, positively or negatively, the quality of the instrument. Considering the real need to evaluate a b-learning educational experience with a consensual questionnaire, we present a Decision Making model for questionnaire validation that solves it. Additionally, we contribute to this consensus reaching problem by developing an online tool under GPL v3 license. The software visualizes the collective valuations for each iteration and assists to determine which parts of the questionnaire should be modified to reach a consensual solution.
* 47 pages, 7 figures
Sentiment Analysis based Multi-person Multi-criteria Decision Making Methodology: Using Natural Language Processing and Deep Learning for Decision Aid
Jul 31, 2020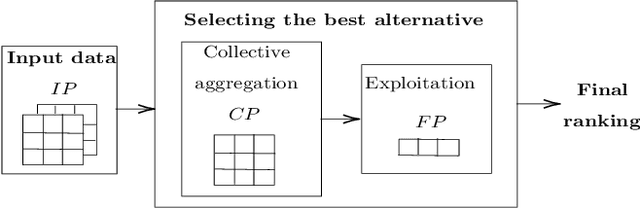
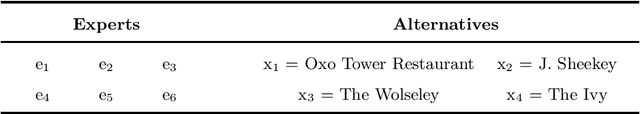
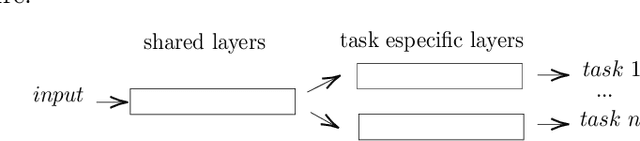

Decision making models are constrained by taking the expert evaluations with pre-defined numerical or linguistic terms. We claim that the use of sentiment analysis will allow decision making models to consider expert evaluations in natural language. Accordingly, we propose the Sentiment Analysis based Multi-person Multi-criteria Decision Making (SA-MpMcDM) methodology, which builds the expert evaluations from their natural language reviews, and even from their numerical ratings if they are available. The SA-MpMcDM methodology incorporates an end-to-end multi-task deep learning model for aspect based sentiment analysis, named DMuABSA model, able to identify the aspect categories mentioned in an expert review, and to distill their opinions and criteria. The individual expert evaluations are aggregated via a criteria weighting through the attention of the experts. We evaluate the methodology in a restaurant decision problem, hence we build the TripR-2020 dataset of restaurant reviews, which we manually annotate and release. We analyze the SA-MpMcDM methodology in different scenarios using and not using natural language and numerical evaluations. The analysis shows that the combination of both sources of information results in a higher quality preference vector.