 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient Federated Chain: Transforming Blockchain Consensus into an Active Defense Layer for Federated Learning
Feb 25, 2026Federated Learning (FL) has emerged as a key paradigm for building Trustworthy AI systems by enabling privacy-preserving, decentralized model training. However, FL is highly susceptible to adversarial attacks that compromise model integrity and data confidentiality, a vulnerability exacerbated by the fact that conventional data inspection methods are incompatible with its decentralized design. While integrating FL with Blockchain technology has been proposed to address some limitations, its potential for mitigating adversarial attacks remains largely unexplored. This paper introduces Resilient Federated Chain (RFC), a novel blockchain-enabled FL framework designed specifically to enhance resilience against such threats. RFC builds upon the existing Proof of Federated Learning architecture by repurposing the redundancy of its Pooled Mining mechanism as an active defense layer that can be combined with robust aggregation rules. Furthermore, the framework introduces a flexible evaluation function in its consensus mechanism, allowing for adaptive defense against different attack strategies. Extensive experimental evaluation on image classification tasks under various adversarial scenarios, demonstrates that RFC significantly improves robustness compared to baseline methods, providing a viable solution for securing decentralized learning environments.
Improving $(α, f)$-Byzantine Resilience in Federated Learning via layerwise aggregation and cosine distance
Mar 27, 2025



The rapid development of artificial intelligence systems has amplified societal concerns regarding their usage, necessitating regulatory frameworks that encompass data privacy. Federated Learning (FL) is posed as potential solution to data privacy challenges in distributed machine learning by enabling collaborative model training {without data sharing}. However, FL systems remain vulnerable to Byzantine attacks, where malicious nodes contribute corrupted model updates. While Byzantine Resilient operators have emerged as a widely adopted robust aggregation algorithm to mitigate these attacks, its efficacy diminishes significantly in high-dimensional parameter spaces, sometimes leading to poor performing models. This paper introduces Layerwise Cosine Aggregation, a novel aggregation scheme designed to enhance robustness of these rules in such high-dimensional settings while preserving computational efficiency. A theoretical analysis is presented, demonstrating the superior robustness of the proposed Layerwise Cosine Aggregation compared to original robust aggregation operators. Empirical evaluation across diverse image classification datasets, under varying data distributions and Byzantine attack scenarios, consistently demonstrates the improved performance of Layerwise Cosine Aggregation, achieving up to a 16% increase in model accuracy.
Membership Inference Attacks fueled by Few-Short Learning to detect privacy leakage tackling data integrity
Mar 12, 2025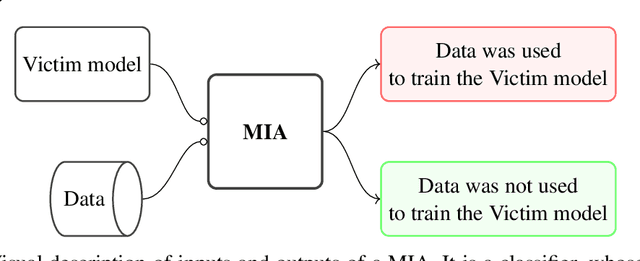
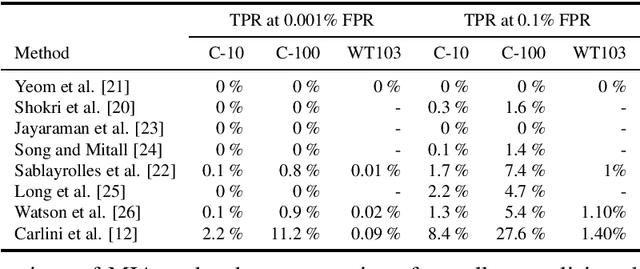
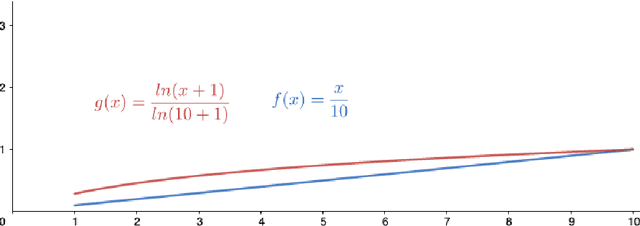
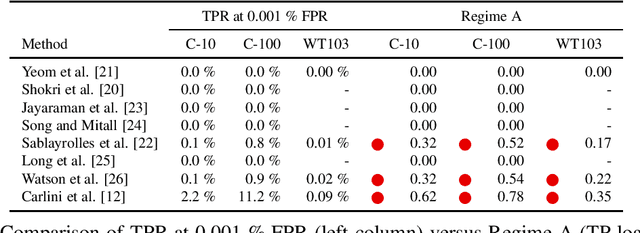
Deep learning models have an intrinsic privacy issue as they memorize parts of their training data, creating a privacy leakage. Membership Inference Attacks (MIA) exploit it to obtain confidential information about the data used for training, aiming to steal information. They can be repurposed as a measurement of data integrity by inferring whether it was used to train a machine learning model. While state-of-the-art attacks achieve a significant privacy leakage, their requirements are not feasible enough, hindering their role as practical tools to assess the magnitude of the privacy risk. Moreover, the most appropriate evaluation metric of MIA, the True Positive Rate at low False Positive Rate lacks interpretability. We claim that the incorporation of Few-Shot Learning techniques to the MIA field and a proper qualitative and quantitative privacy evaluation measure should deal with these issues. In this context, our proposal is twofold. We propose a Few-Shot learning based MIA, coined as the FeS-MIA model, which eases the evaluation of the privacy breach of a deep learning model by significantly reducing the number of resources required for the purpose. Furthermore, we propose an interpretable quantitative and qualitative measure of privacy, referred to as Log-MIA measure. Jointly, these proposals provide new tools to assess the privacy leakage and to ease the evaluation of the training data integrity of deep learning models, that is, to analyze the privacy breach of a deep learning model. Experiments carried out with MIA over image classification and language modeling tasks and its comparison to the state-of-the-art show that our proposals excel at reporting the privacy leakage of a deep learning model with little extra information.
Krum Federated Chain (KFC): Using blockchain to defend against adversarial attacks in Federated Learning
Feb 10, 2025Federated Learning presents a nascent approach to machine learning, enabling collaborative model training across decentralized devices while safeguarding data privacy. However, its distributed nature renders it susceptible to adversarial attacks. Integrating blockchain technology with Federated Learning offers a promising avenue to enhance security and integrity. In this paper, we tackle the potential of blockchain in defending Federated Learning against adversarial attacks. First, we test Proof of Federated Learning, a well known consensus mechanism designed ad-hoc to federated contexts, as a defense mechanism demonstrating its efficacy against Byzantine and backdoor attacks when at least one miner remains uncompromised. Second, we propose Krum Federated Chain, a novel defense strategy combining Krum and Proof of Federated Learning, valid to defend against any configuration of Byzantine or backdoor attacks, even when all miners are compromised. Our experiments conducted on image classification datasets validate the effectiveness of our proposed approaches.
RAB$^2$-DEF: Dynamic and explainable defense against adversarial attacks in Federated Learning to fair poor clients
Oct 10, 2024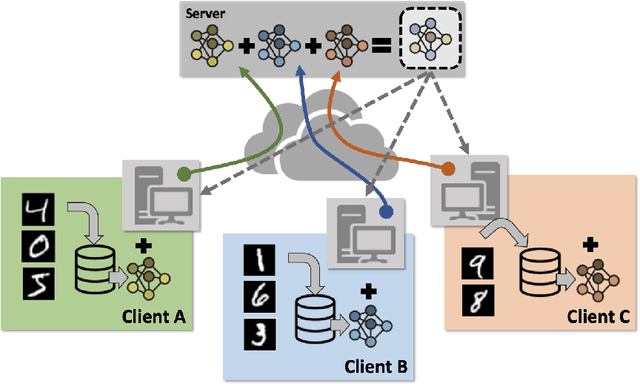

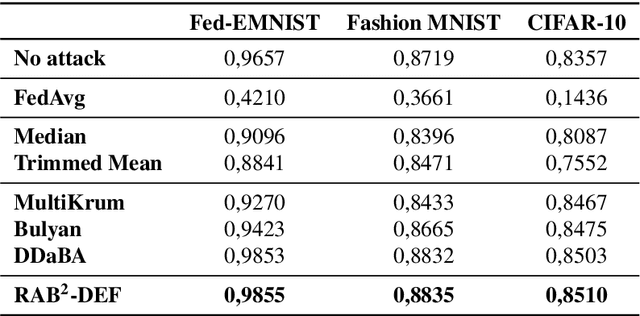
At the same time that artificial intelligence is becoming popular, concern and the need for regulation is growing, including among other requirements the data privacy. In this context, Federated Learning is proposed as a solution to data privacy concerns derived from different source data scenarios due to its distributed learning. The defense mechanisms proposed in literature are just focused on defending against adversarial attacks and the performance, leaving aside other important qualities such as explainability, fairness to poor quality clients, dynamism in terms of attacks configuration and generality in terms of being resilient against different kinds of attacks. In this work, we propose RAB$^2$-DEF, a $\textbf{r}$esilient $\textbf{a}$gainst $\textbf{b}\text{yzantine}$ and $\textbf{b}$ackdoor attacks which is $\textbf{d}$ynamic, $\textbf{e}$xplainable and $\textbf{f}$air to poor clients using local linear explanations. We test the performance of RAB$^2$-DEF in image datasets and both byzantine and backdoor attacks considering the state-of-the-art defenses and achieve that RAB$^2$-DEF is a proper defense at the same time that it boosts the other qualities towards trustworthy artificial intelligence.
FLEX: FLEXible Federated Learning Framework
Apr 09, 2024



In the realm of Artificial Intelligence (AI), the need for privacy and security in data processing has become paramount. As AI applications continue to expand, the collection and handling of sensitive data raise concerns about individual privacy protection. Federated Learning (FL) emerges as a promising solution to address these challenges by enabling decentralized model training on local devices, thus preserving data privacy. This paper introduces FLEX: a FLEXible Federated Learning Framework designed to provide maximum flexibility in FL research experiments. By offering customizable features for data distribution, privacy parameters, and communication strategies, FLEX empowers researchers to innovate and develop novel FL techniques. The framework also includes libraries for specific FL implementations including: (1) anomalies, (2) blockchain, (3) adversarial attacks and defences, (4) natural language processing and (5) decision trees, enhancing its versatility and applicability in various domains. Overall, FLEX represents a significant advancement in FL research, facilitating the development of robust and efficient FL applications.
An Interpretable Client Decision Tree Aggregation process for Federated Learning
Apr 03, 2024


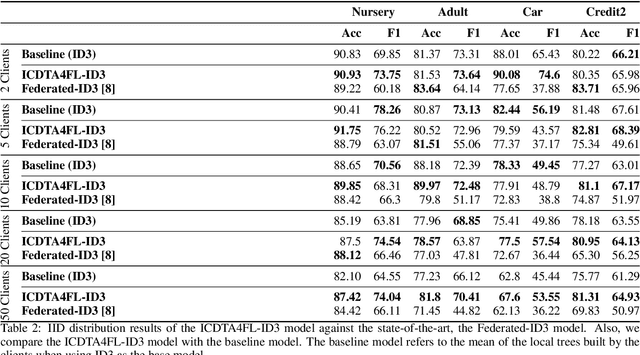
Trustworthy Artificial Intelligence solutions are essential in today's data-driven applications, prioritizing principles such as robustness, safety, transparency, explainability, and privacy among others. This has led to the emergence of Federated Learning as a solution for privacy and distributed machine learning. While decision trees, as self-explanatory models, are ideal for collaborative model training across multiple devices in resource-constrained environments such as federated learning environments for injecting interpretability in these models. Decision tree structure makes the aggregation in a federated learning environment not trivial. They require techniques that can merge their decision paths without introducing bias or overfitting while keeping the aggregated decision trees robust and generalizable. In this paper, we propose an Interpretable Client Decision Tree Aggregation process for Federated Learning scenarios that keeps the interpretability and the precision of the base decision trees used for the aggregation. This model is based on aggregating multiple decision paths of the decision trees and can be used on different decision tree types, such as ID3 and CART. We carry out the experiments within four datasets, and the analysis shows that the tree built with the model improves the local models, and outperforms the state-of-the-art.
Survey on Federated Learning Threats: concepts, taxonomy on attacks and defences, experimental study and challenges
Jan 20, 2022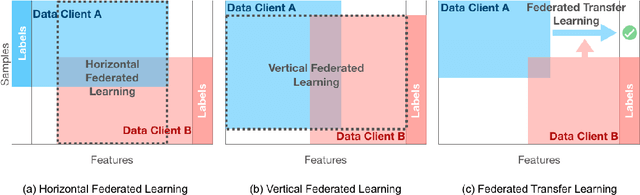
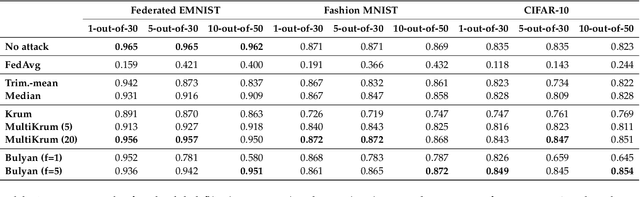
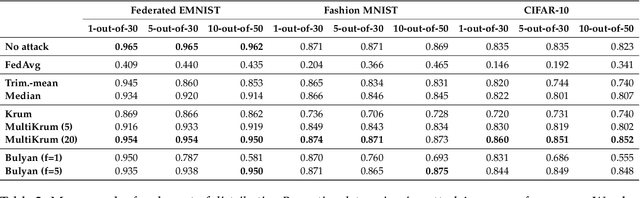
Federated learning is a machine learning paradigm that emerges as a solution to the privacy-preservation demands in artificial intelligence. As machine learning, federated learning is threatened by adversarial attacks against the integrity of the learning model and the privacy of data via a distributed approach to tackle local and global learning. This weak point is exacerbated by the inaccessibility of data in federated learning, which makes harder the protection against adversarial attacks and evidences the need to furtherance the research on defence methods to make federated learning a real solution for safeguarding data privacy. In this paper, we present an extensive review of the threats of federated learning, as well as as their corresponding countermeasures, attacks versus defences. This survey provides a taxonomy of adversarial attacks and a taxonomy of defence methods that depict a general picture of this vulnerability of federated learning and how to overcome it. Likewise, we expound guidelines for selecting the most adequate defence method according to the category of the adversarial attack. Besides, we carry out an extensive experimental study from which we draw further conclusions about the behaviour of attacks and defences and the guidelines for selecting the most adequate defence method according to the category of the adversarial attack. This study is finished leading to meditated learned lessons and challenges.
Dynamic Federated Learning Model for Identifying Adversarial Clients
Jul 29, 2020
Federated learning, as a distributed learning that conducts the training on the local devices without accessing to the training data, is vulnerable to dirty-label data poisoning adversarial attacks. We claim that the federated learning model has to avoid those kind of adversarial attacks through filtering out the clients that manipulate the local data. We propose a dynamic federated learning model that dynamically discards those adversarial clients, which allows to prevent the corruption of the global learning model. We evaluate the dynamic discarding of adversarial clients deploying a deep learning classification model in a federated learning setting, and using the EMNIST Digits and Fashion MNIST image classification datasets. Likewise, we analyse the capacity of detecting clients with poor data distribution and reducing the number of rounds of learning by selecting the clients to aggregate. The results show that the dynamic selection of the clients to aggregate enhances the performance of the global learning model, discards the adversarial and poor clients and reduces the rounds of learning.
Federated Learning and Differential Privacy: Software tools analysis, the Sherpa.ai FL framework and methodological guidelines for preserving data privacy
Jul 02, 2020The high demand of artificial intelligence services at the edges that also preserve data privacy has pushed the research on novel machine learning paradigms that fit those requirements. Federated learning has the ambition to protect data privacy through distributed learning methods that keep the data in their data silos. Likewise, differential privacy attains to improve the protection of data privacy by measuring the privacy loss in the communication among the elements of federated learning. The prospective matching of federated learning and differential privacy to the challenges of data privacy protection has caused the release of several software tools that support their functionalities, but they lack of the needed unified vision for those techniques, and a methodological workflow that support their use. Hence, we present the Sherpa.ai Federated Learning framework that is built upon an holistic view of federated learning and differential privacy. It results from the study of how to adapt the machine learning paradigm to federated learning, and the definition of methodological guidelines for developing artificial intelligence services based on federated learning and differential privacy. We show how to follow the methodological guidelines with the Sherpa.ai Federated Learning framework by means of a classification and a regression use cases.