 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTweetNLP: Cutting-Edge Natural Language Processing for Social Media
Jun 29, 2022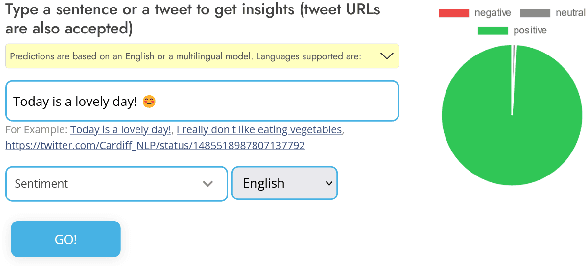
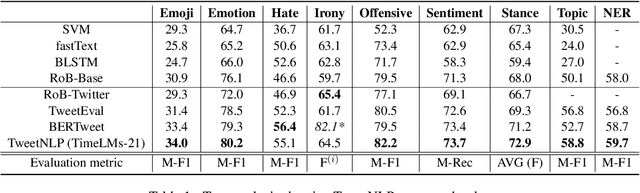
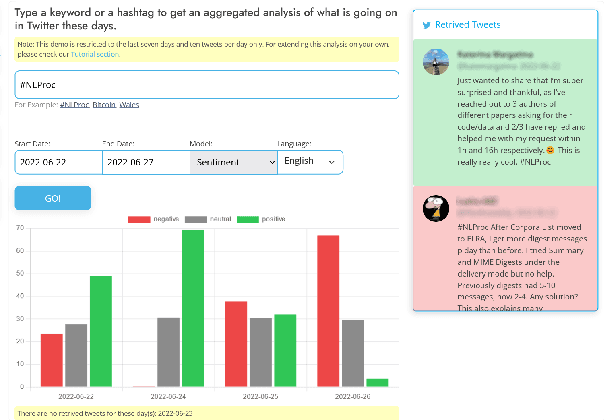

In this paper we present TweetNLP, an integrated platform for Natural Language Processing (NLP) in social media. TweetNLP supports a diverse set of NLP tasks, including generic focus areas such as sentiment analysis and named entity recognition, as well as social media-specific tasks such as emoji prediction and offensive language identification. Task-specific systems are powered by reasonably-sized Transformer-based language models specialized on social media text (in particular, Twitter) which can be run without the need for dedicated hardware or cloud services. The main contributions of TweetNLP are: (1) an integrated Python library for a modern toolkit supporting social media analysis using our various task-specific models adapted to the social domain; (2) an interactive online demo for codeless experimentation using our models; and (3) a tutorial covering a wide variety of typical social media applications.
Survey on Federated Learning Threats: concepts, taxonomy on attacks and defences, experimental study and challenges
Jan 20, 2022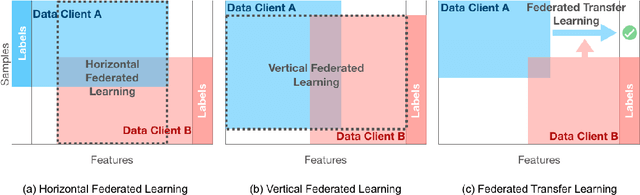
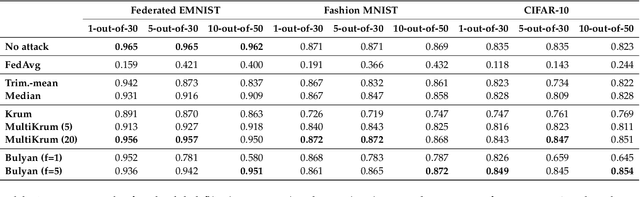
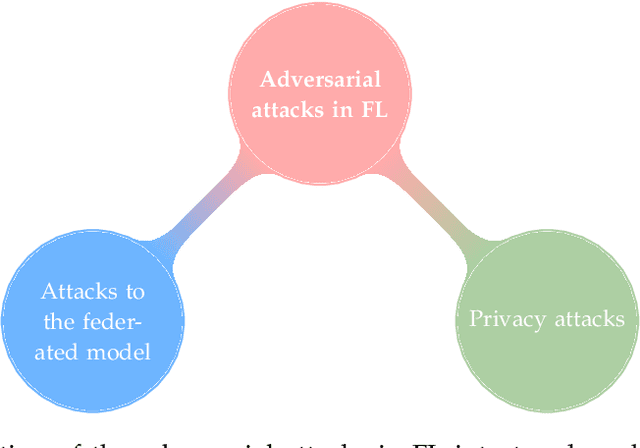
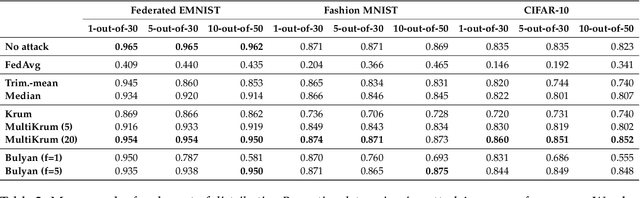
Federated learning is a machine learning paradigm that emerges as a solution to the privacy-preservation demands in artificial intelligence. As machine learning, federated learning is threatened by adversarial attacks against the integrity of the learning model and the privacy of data via a distributed approach to tackle local and global learning. This weak point is exacerbated by the inaccessibility of data in federated learning, which makes harder the protection against adversarial attacks and evidences the need to furtherance the research on defence methods to make federated learning a real solution for safeguarding data privacy. In this paper, we present an extensive review of the threats of federated learning, as well as as their corresponding countermeasures, attacks versus defences. This survey provides a taxonomy of adversarial attacks and a taxonomy of defence methods that depict a general picture of this vulnerability of federated learning and how to overcome it. Likewise, we expound guidelines for selecting the most adequate defence method according to the category of the adversarial attack. Besides, we carry out an extensive experimental study from which we draw further conclusions about the behaviour of attacks and defences and the guidelines for selecting the most adequate defence method according to the category of the adversarial attack. This study is finished leading to meditated learned lessons and challenges.
Sentiment Analysis based Multi-person Multi-criteria Decision Making Methodology: Using Natural Language Processing and Deep Learning for Decision Aid
Jul 31, 2020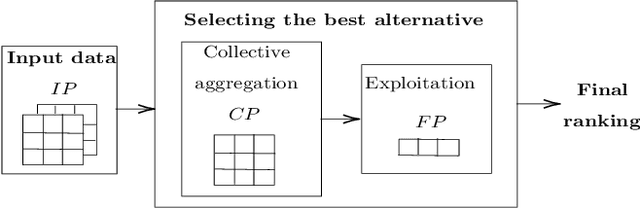
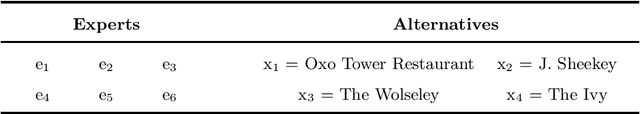

Decision making models are constrained by taking the expert evaluations with pre-defined numerical or linguistic terms. We claim that the use of sentiment analysis will allow decision making models to consider expert evaluations in natural language. Accordingly, we propose the Sentiment Analysis based Multi-person Multi-criteria Decision Making (SA-MpMcDM) methodology, which builds the expert evaluations from their natural language reviews, and even from their numerical ratings if they are available. The SA-MpMcDM methodology incorporates an end-to-end multi-task deep learning model for aspect based sentiment analysis, named DMuABSA model, able to identify the aspect categories mentioned in an expert review, and to distill their opinions and criteria. The individual expert evaluations are aggregated via a criteria weighting through the attention of the experts. We evaluate the methodology in a restaurant decision problem, hence we build the TripR-2020 dataset of restaurant reviews, which we manually annotate and release. We analyze the SA-MpMcDM methodology in different scenarios using and not using natural language and numerical evaluations. The analysis shows that the combination of both sources of information results in a higher quality preference vector.
Dynamic Federated Learning Model for Identifying Adversarial Clients
Jul 29, 2020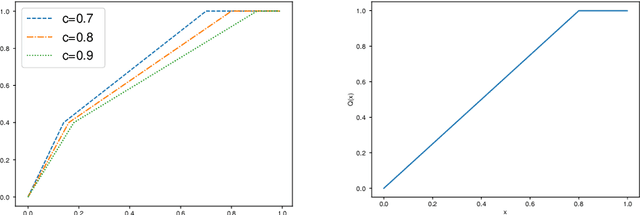
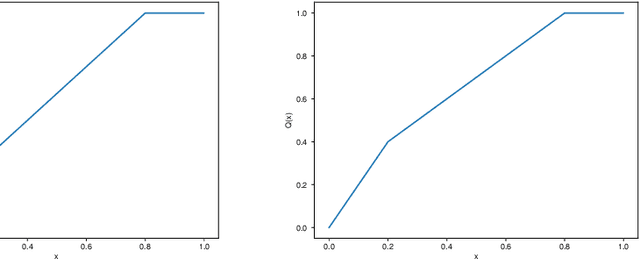
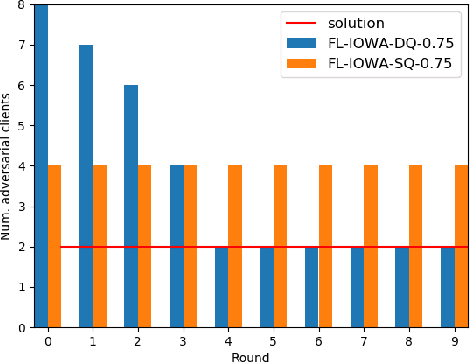
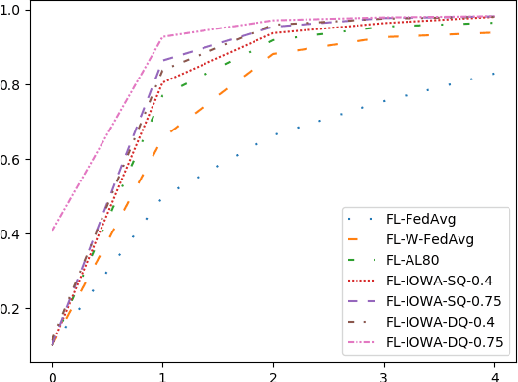
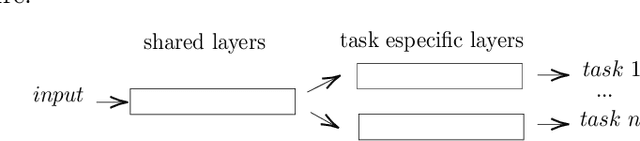
Federated learning, as a distributed learning that conducts the training on the local devices without accessing to the training data, is vulnerable to dirty-label data poisoning adversarial attacks. We claim that the federated learning model has to avoid those kind of adversarial attacks through filtering out the clients that manipulate the local data. We propose a dynamic federated learning model that dynamically discards those adversarial clients, which allows to prevent the corruption of the global learning model. We evaluate the dynamic discarding of adversarial clients deploying a deep learning classification model in a federated learning setting, and using the EMNIST Digits and Fashion MNIST image classification datasets. Likewise, we analyse the capacity of detecting clients with poor data distribution and reducing the number of rounds of learning by selecting the clients to aggregate. The results show that the dynamic selection of the clients to aggregate enhances the performance of the global learning model, discards the adversarial and poor clients and reduces the rounds of learning.
Federated Learning and Differential Privacy: Software tools analysis, the Sherpa.ai FL framework and methodological guidelines for preserving data privacy
Jul 02, 2020The high demand of artificial intelligence services at the edges that also preserve data privacy has pushed the research on novel machine learning paradigms that fit those requirements. Federated learning has the ambition to protect data privacy through distributed learning methods that keep the data in their data silos. Likewise, differential privacy attains to improve the protection of data privacy by measuring the privacy loss in the communication among the elements of federated learning. The prospective matching of federated learning and differential privacy to the challenges of data privacy protection has caused the release of several software tools that support their functionalities, but they lack of the needed unified vision for those techniques, and a methodological workflow that support their use. Hence, we present the Sherpa.ai Federated Learning framework that is built upon an holistic view of federated learning and differential privacy. It results from the study of how to adapt the machine learning paradigm to federated learning, and the definition of methodological guidelines for developing artificial intelligence services based on federated learning and differential privacy. We show how to follow the methodological guidelines with the Sherpa.ai Federated Learning framework by means of a classification and a regression use cases.
Learning Cross-lingual Embeddings from Twitter via Distant Supervision
May 17, 2019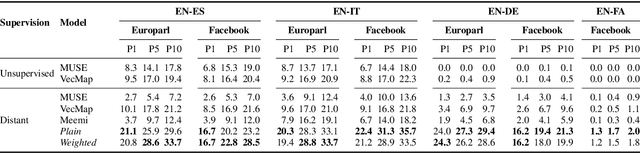
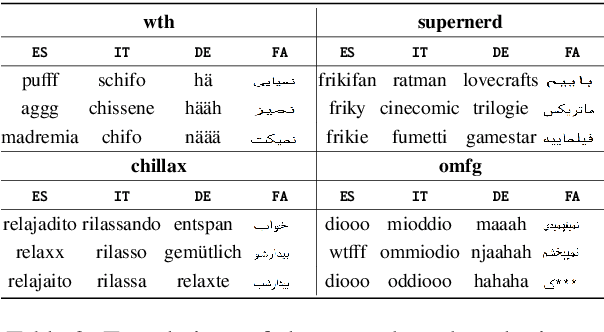

Cross-lingual embeddings represent the meaning of words from different languages in the same vector space. Recent work has shown that it is possible to construct such representations by aligning independently learned monolingual embedding spaces, and that accurate alignments can be obtained even without external bilingual data. In this paper we explore a research direction which has been surprisingly neglected in the literature: leveraging noisy user-generated text to learn cross-lingual embeddings particularly tailored towards social media applications. While the noisiness and informal nature of the social media genre poses additional challenges to cross-lingual embedding methods, we find that it also provides key opportunities due to the abundance of code-switching and the existence of a shared vocabulary of emoji and named entities. Our contribution consists in a very simple post-processing step that exploits these phenomena to significantly improve the performance of state-of-the-art alignment methods.