 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialz: A Python Toolkit for Steering Vectors
May 04, 2025We introduce Dialz, a framework for advancing research on steering vectors for open-source LLMs, implemented in Python. Steering vectors allow users to modify activations at inference time to amplify or weaken a 'concept', e.g. honesty or positivity, providing a more powerful alternative to prompting or fine-tuning. Dialz supports a diverse set of tasks, including creating contrastive pair datasets, computing and applying steering vectors, and visualizations. Unlike existing libraries, Dialz emphasizes modularity and usability, enabling both rapid prototyping and in-depth analysis. We demonstrate how Dialz can be used to reduce harmful outputs such as stereotypes, while also providing insights into model behaviour across different layers. We release Dialz with full documentation, tutorials, and support for popular open-source models to encourage further research in safe and controllable language generation. Dialz enables faster research cycles and facilitates insights into model interpretability, paving the way for safer, more transparent, and more reliable AI systems.
Trust in Disinformation Narratives: a Trust in the News Experiment
Mar 14, 2025Understanding why people trust or distrust one another, institutions, or information is a complex task that has led scholars from various fields of study to employ diverse epistemological and methodological approaches. Despite the challenges, it is generally agreed that the antecedents of trust (and distrust) encompass a multitude of emotional and cognitive factors, including a general disposition to trust and an assessment of trustworthiness factors. In an era marked by increasing political polarization, cultural backlash, widespread disinformation and fake news, and the use of AI software to produce news content, the need to study trust in the news has gained significant traction. This study presents the findings of a trust in the news experiment designed in collaboration with Spanish and UK journalists, fact-checkers, and the CardiffNLP Natural Language Processing research group. The purpose of this experiment, conducted in June 2023, was to examine the extent to which people trust a set of fake news articles based on previously identified disinformation narratives related to gender, climate change, and COVID-19. The online experiment participants (801 in Spain and 800 in the UK) were asked to read three fake news items and rate their level of trust on a scale from 1 (not true) to 8 (true). The pieces used a combination of factors, including stance (favourable, neutral, or against the narrative), presence of toxic expressions, clickbait titles, and sources of information to test which elements influenced people's responses the most. Half of the pieces were produced by humans and the other half by ChatGPT. The results show that the topic of news articles, stance, people's age, gender, and political ideologies significantly affected their levels of trust in the news, while the authorship (humans or ChatGPT) does not have a significant impact.
Wikipedia is Not a Dictionary, Delete! Text Classification as a Proxy for Analysing Wiki Deletion Discussions
Mar 13, 2025Automated content moderation for collaborative knowledge hubs like Wikipedia or Wikidata is an important yet challenging task due to multiple factors. In this paper, we construct a database of discussions happening around articles marked for deletion in several Wikis and in three languages, which we then use to evaluate a range of LMs on different tasks (from predicting the outcome of the discussion to identifying the implicit policy an individual comment might be pointing to). Our results reveal, among others, that discussions leading to deletion are easier to predict, and that, surprisingly, self-produced tags (keep, delete or redirect) don't always help guiding the classifiers, presumably because of users' hesitation or deliberation within comments.
Shifting Perspectives: Steering Vector Ensembles for Robust Bias Mitigation in LLMs
Mar 07, 2025We present a novel approach to bias mitigation in large language models (LLMs) by applying steering vectors to modify model activations in forward passes. We employ Bayesian optimization to systematically identify effective contrastive pair datasets across nine bias axes. When optimized on the BBQ dataset, our individually tuned steering vectors achieve average improvements of 12.2%, 4.7%, and 3.2% over the baseline for Mistral, Llama, and Qwen, respectively. Building on these promising results, we introduce Steering Vector Ensembles (SVE), a method that averages multiple individually optimized steering vectors, each targeting a specific bias axis such as age, race, or gender. By leveraging their collective strength, SVE outperforms individual steering vectors in both bias reduction and maintaining model performance. The work presents the first systematic investigation of steering vectors for bias mitigation, and we demonstrate that SVE is a powerful and computationally efficient strategy for reducing bias in LLMs, with broader implications for enhancing AI safety.
GEAR: A Simple GENERATE, EMBED, AVERAGE AND RANK Approach for Unsupervised Reverse Dictionary
Dec 09, 2024
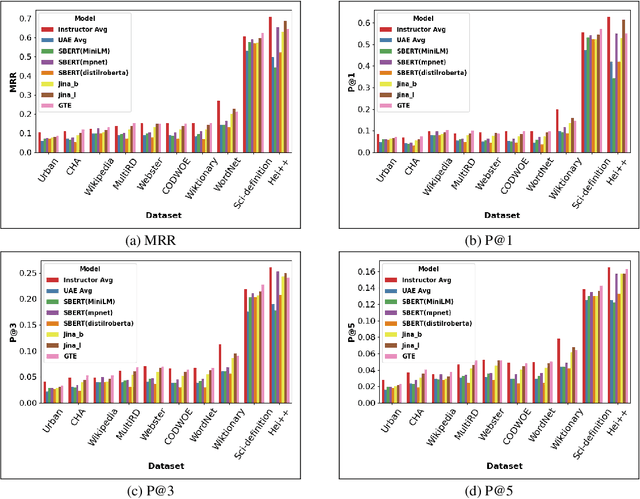
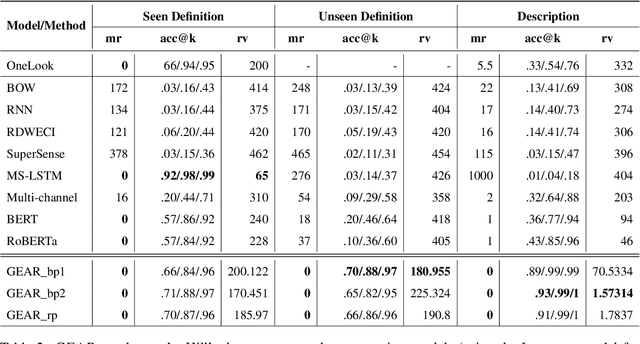
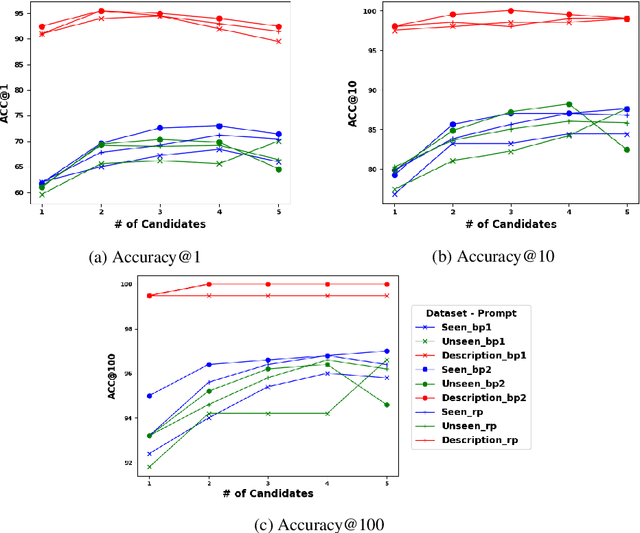
Reverse Dictionary (RD) is the task of obtaining the most relevant word or set of words given a textual description or dictionary definition. Effective RD methods have applications in accessibility, translation or writing support systems. Moreover, in NLP research we find RD to be used to benchmark text encoders at various granularities, as it often requires word, definition and sentence embeddings. In this paper, we propose a simple approach to RD that leverages LLMs in combination with embedding models. Despite its simplicity, this approach outperforms supervised baselines in well studied RD datasets, while also showing less over-fitting. We also conduct a number of experiments on different dictionaries and analyze how different styles, registers and target audiences impact the quality of RD systems. We conclude that, on average, untuned embeddings alone fare way below an LLM-only baseline (although they are competitive in highly technical dictionaries), but are crucial for boosting performance in combined methods.
WiDe-analysis: Enabling One-click Content Moderation Analysis on Wikipedia's Articles for Deletion
Aug 10, 2024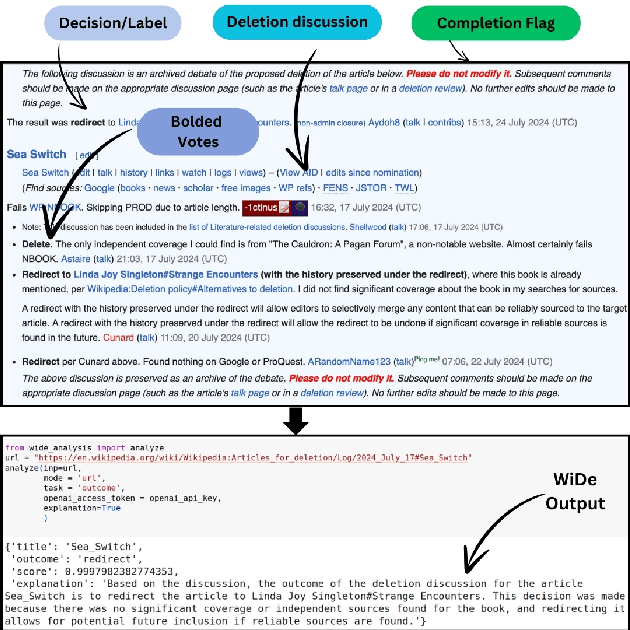
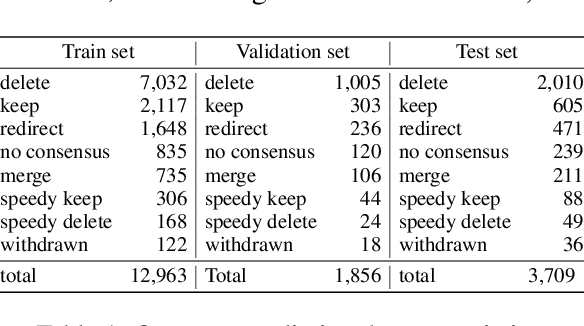
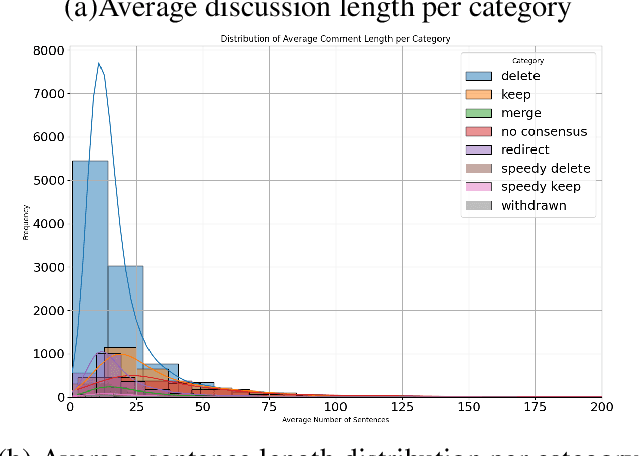
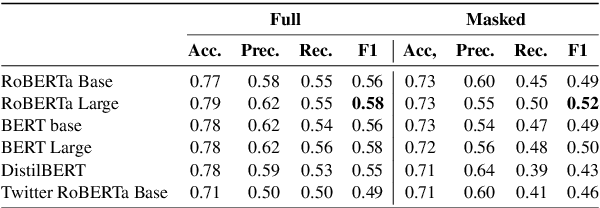
Content moderation in online platforms is crucial for ensuring activity therein adheres to existing policies, especially as these platforms grow. NLP research in this area has typically focused on automating some part of it given that it is not feasible to monitor all active discussions effectively. Past works have focused on revealing deletion patterns with like sentiment analysis, or on developing platform-specific models such as Wikipedia policy or stance detectors. Unsurprisingly, however, this valuable body of work is rather scattered, with little to no agreement with regards to e.g., the deletion discussions corpora used for training or the number of stance labels. Moreover, while efforts have been made to connect stance with rationales (e.g., to ground a deletion decision on the relevant policy), there is little explanability work beyond that. In this paper, we introduce a suite of experiments on Wikipedia deletion discussions and wide-analyis (Wikipedia Deletion Analysis), a Python package aimed at providing one click analysis to content moderation discussions. We release all assets associated with wide-analysis, including data, models and the Python package, and a HuggingFace space with the goal to accelerate research on automating content moderation in Wikipedia and beyond.
Who is better at math, Jenny or Jingzhen? Uncovering Stereotypes in Large Language Models
Jul 09, 2024Large language models (LLMs) have been shown to propagate and amplify harmful stereotypes, particularly those that disproportionately affect marginalised communities. To understand the effect of these stereotypes more comprehensively, we introduce GlobalBias, a dataset of 876k sentences incorporating 40 distinct gender-by-ethnicity groups alongside descriptors typically used in bias literature, which enables us to study a broad set of stereotypes from around the world. We use GlobalBias to directly probe a suite of LMs via perplexity, which we use as a proxy to determine how certain stereotypes are represented in the model's internal representations. Following this, we generate character profiles based on given names and evaluate the prevalence of stereotypes in model outputs. We find that the demographic groups associated with various stereotypes remain consistent across model likelihoods and model outputs. Furthermore, larger models consistently display higher levels of stereotypical outputs, even when explicitly instructed not to.
CHEW: A Dataset of CHanging Events in Wikipedia
Jun 27, 2024



We introduce CHEW, a novel dataset of changing events in Wikipedia expressed in naturally occurring text. We use CHEW for probing LLMs for their timeline understanding of Wikipedia entities and events in generative and classification experiments. Our results suggest that LLMs, despite having temporal information available, struggle to construct accurate timelines. We further show the usefulness of CHEW-derived embeddings for identifying meaning shift.
Hoaxpedia: A Unified Wikipedia Hoax Articles Dataset
May 03, 2024Hoaxes are a recognised form of disinformation created deliberately, with potential serious implications in the credibility of reference knowledge resources such as Wikipedia. What makes detecting Wikipedia hoaxes hard is that they often are written according to the official style guidelines. In this work, we first provide a systematic analysis of the similarities and discrepancies between legitimate and hoax Wikipedia articles, and introduce Hoaxpedia, a collection of 311 Hoax articles (from existing literature as well as official Wikipedia lists) alongside semantically similar real articles. We report results of binary classification experiments in the task of predicting whether a Wikipedia article is real or hoax, and analyze several settings as well as a range of language models. Our results suggest that detecting deceitful content in Wikipedia based on content alone, despite not having been explored much in the past, is a promising direction.
Construction Artifacts in Metaphor Identification Datasets
Nov 15, 2023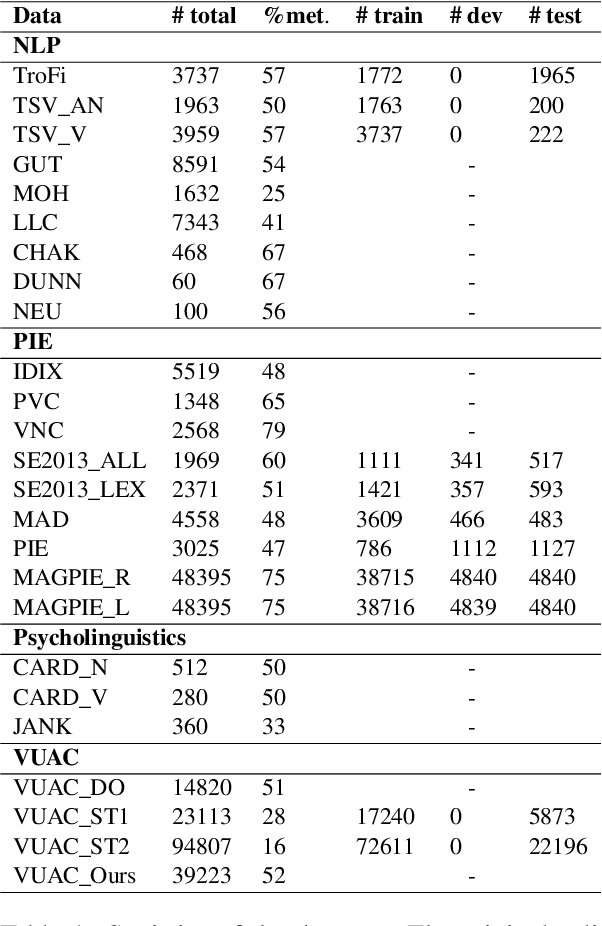
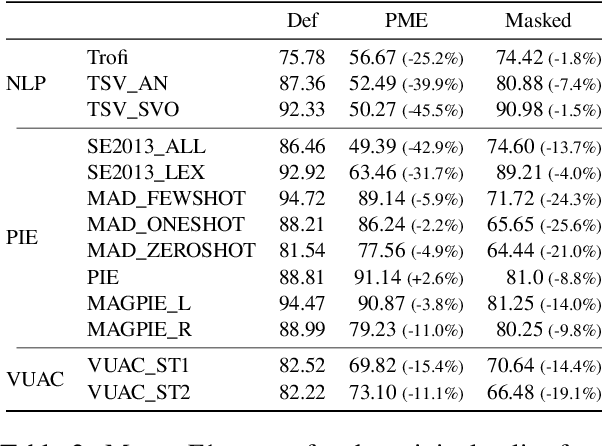
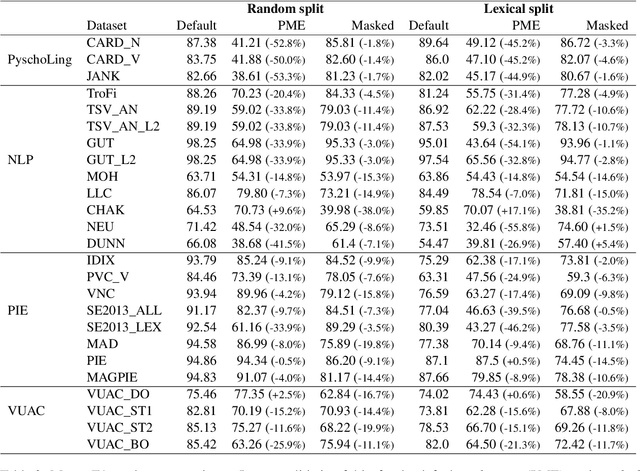
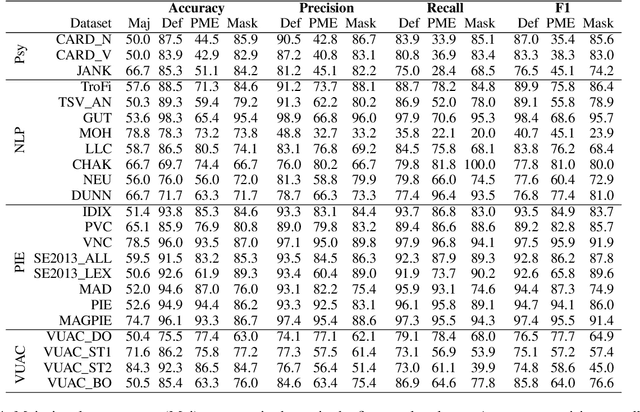
Metaphor identification aims at understanding whether a given expression is used figuratively in context. However, in this paper we show how existing metaphor identification datasets can be gamed by fully ignoring the potential metaphorical expression or the context in which it occurs. We test this hypothesis in a variety of datasets and settings, and show that metaphor identification systems based on language models without complete information can be competitive with those using the full context. This is due to the construction procedures to build such datasets, which introduce unwanted biases for positive and negative classes. Finally, we test the same hypothesis on datasets that are carefully sampled from natural corpora and where this bias is not present, making these datasets more challenging and reliable.