 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEAR: A Simple GENERATE, EMBED, AVERAGE AND RANK Approach for Unsupervised Reverse Dictionary
Paper and Code
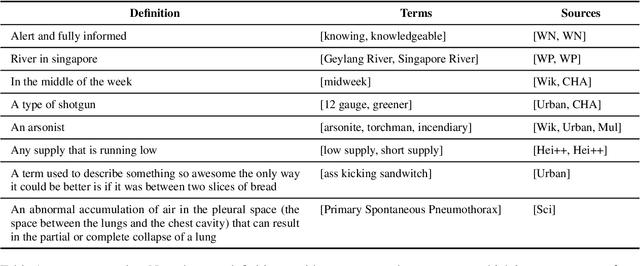
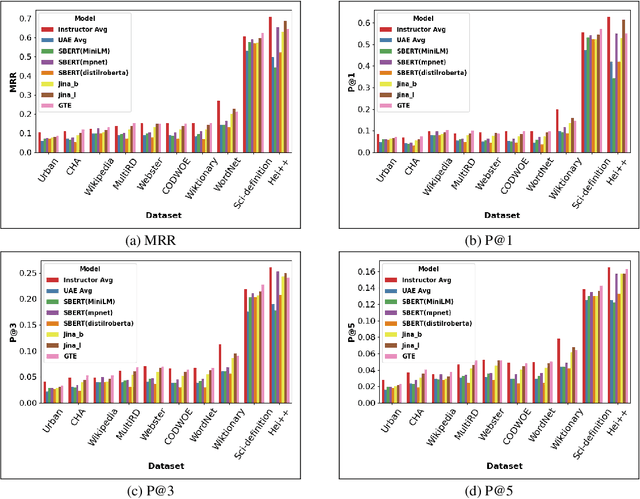
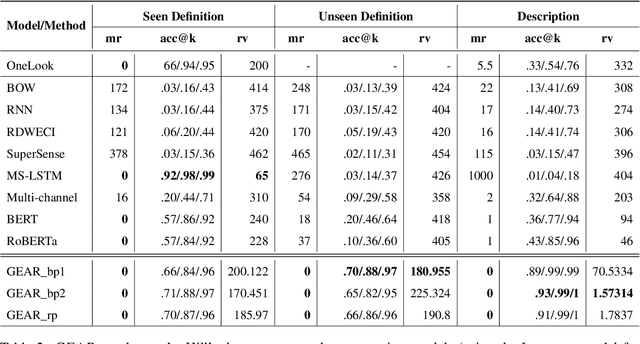
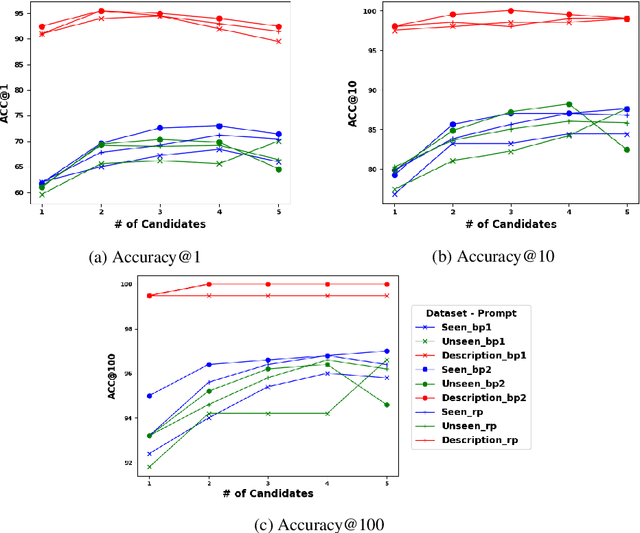
Reverse Dictionary (RD) is the task of obtaining the most relevant word or set of words given a textual description or dictionary definition. Effective RD methods have applications in accessibility, translation or writing support systems. Moreover, in NLP research we find RD to be used to benchmark text encoders at various granularities, as it often requires word, definition and sentence embeddings. In this paper, we propose a simple approach to RD that leverages LLMs in combination with embedding models. Despite its simplicity, this approach outperforms supervised baselines in well studied RD datasets, while also showing less over-fitting. We also conduct a number of experiments on different dictionaries and analyze how different styles, registers and target audiences impact the quality of RD systems. We conclude that, on average, untuned embeddings alone fare way below an LLM-only baseline (although they are competitive in highly technical dictionaries), but are crucial for boosting performance in combined methods.