 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Knowledge Collides: A Mechanistic Study of Intra-Memory Knowledge Conflict in Language Models
Jan 14, 2026In language models (LMs), intra-memory knowledge conflict largely arises when inconsistent information about the same event is encoded within the model's parametric knowledge. While prior work has primarily focused on resolving conflicts between a model's internal knowledge and external resources through approaches such as fine-tuning or knowledge editing, the problem of localizing conflicts that originate during pre-training within the model's internal representations remain unexplored. In this work, we design a framework based on mechanistic interpretability methods to identify where and how conflicting knowledge from the pre-training data is encoded within LMs. Our findings contribute to a growing body of evidence that specific internal components of a language model are responsible for encoding conflicting knowledge from pre-training, and we demonstrate how mechanistic interpretability methods can be leveraged to causally intervene in and control conflicting knowledge at inference time.
Wikipedia is Not a Dictionary, Delete! Text Classification as a Proxy for Analysing Wiki Deletion Discussions
Mar 13, 2025



Automated content moderation for collaborative knowledge hubs like Wikipedia or Wikidata is an important yet challenging task due to multiple factors. In this paper, we construct a database of discussions happening around articles marked for deletion in several Wikis and in three languages, which we then use to evaluate a range of LMs on different tasks (from predicting the outcome of the discussion to identifying the implicit policy an individual comment might be pointing to). Our results reveal, among others, that discussions leading to deletion are easier to predict, and that, surprisingly, self-produced tags (keep, delete or redirect) don't always help guiding the classifiers, presumably because of users' hesitation or deliberation within comments.
Automatic Extraction of Metaphoric Analogies from Literary Texts: Task Formulation, Dataset Construction, and Evaluation
Dec 19, 2024



Extracting metaphors and analogies from free text requires high-level reasoning abilities such as abstraction and language understanding. Our study focuses on the extraction of the concepts that form metaphoric analogies in literary texts. To this end, we construct a novel dataset in this domain with the help of domain experts. We compare the out-of-the-box ability of recent large language models (LLMs) to structure metaphoric mappings from fragments of texts containing proportional analogies. The models are further evaluated on the generation of implicit elements of the analogy, which are indirectly suggested in the texts and inferred by human readers. The competitive results obtained by LLMs in our experiments are encouraging and open up new avenues such as automatically extracting analogies and metaphors from text instead of investing resources in domain experts to manually label data.
WiDe-analysis: Enabling One-click Content Moderation Analysis on Wikipedia's Articles for Deletion
Aug 10, 2024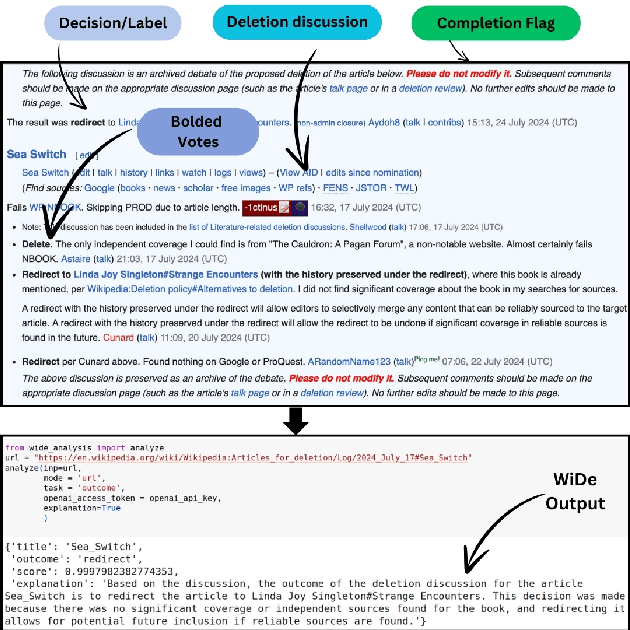
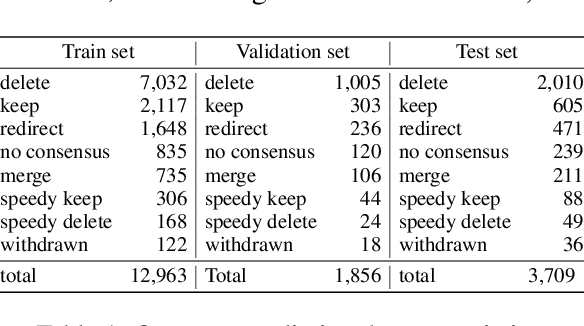
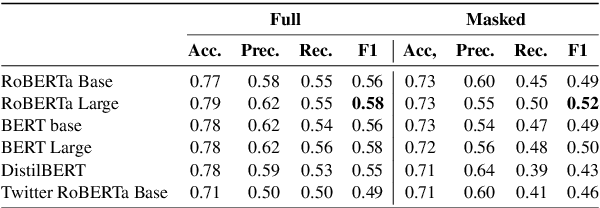
Content moderation in online platforms is crucial for ensuring activity therein adheres to existing policies, especially as these platforms grow. NLP research in this area has typically focused on automating some part of it given that it is not feasible to monitor all active discussions effectively. Past works have focused on revealing deletion patterns with like sentiment analysis, or on developing platform-specific models such as Wikipedia policy or stance detectors. Unsurprisingly, however, this valuable body of work is rather scattered, with little to no agreement with regards to e.g., the deletion discussions corpora used for training or the number of stance labels. Moreover, while efforts have been made to connect stance with rationales (e.g., to ground a deletion decision on the relevant policy), there is little explanability work beyond that. In this paper, we introduce a suite of experiments on Wikipedia deletion discussions and wide-analyis (Wikipedia Deletion Analysis), a Python package aimed at providing one click analysis to content moderation discussions. We release all assets associated with wide-analysis, including data, models and the Python package, and a HuggingFace space with the goal to accelerate research on automating content moderation in Wikipedia and beyond.
CHEW: A Dataset of CHanging Events in Wikipedia
Jun 27, 2024



We introduce CHEW, a novel dataset of changing events in Wikipedia expressed in naturally occurring text. We use CHEW for probing LLMs for their timeline understanding of Wikipedia entities and events in generative and classification experiments. Our results suggest that LLMs, despite having temporal information available, struggle to construct accurate timelines. We further show the usefulness of CHEW-derived embeddings for identifying meaning shift.
BLEnD: A Benchmark for LLMs on Everyday Knowledge in Diverse Cultures and Languages
Jun 14, 2024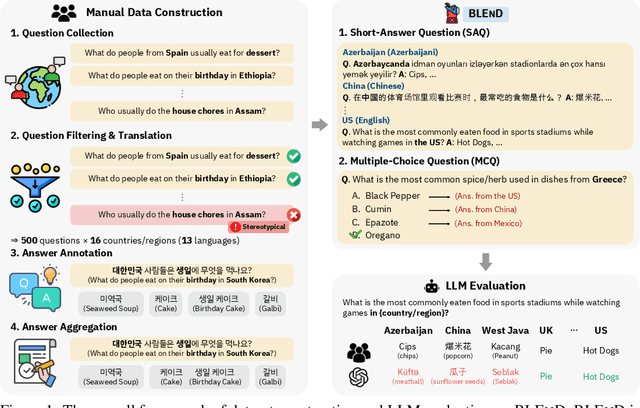
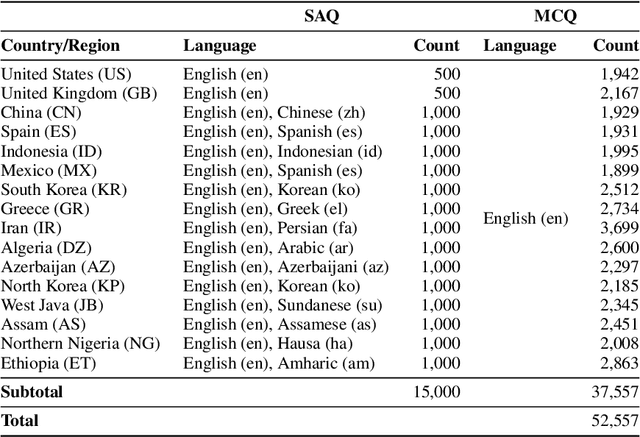
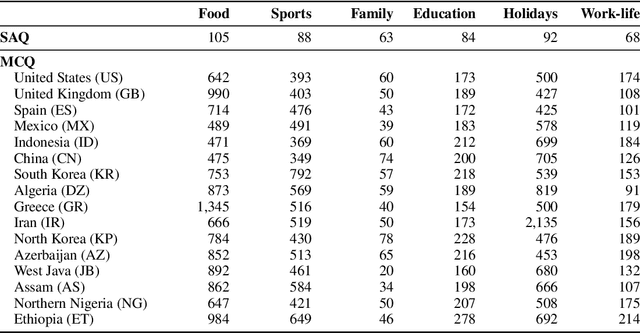
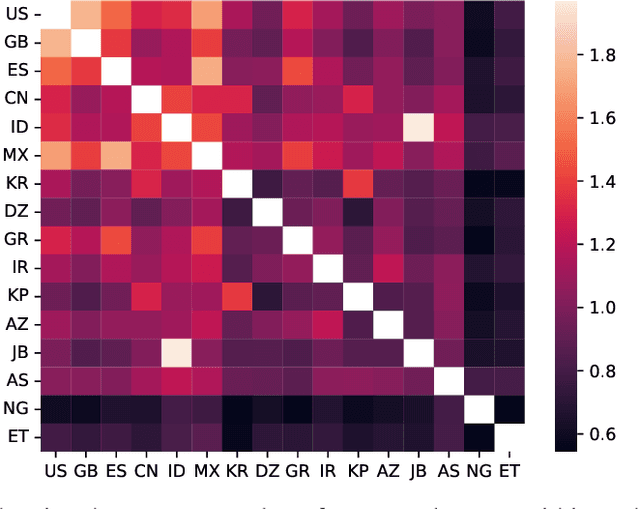
Large language models (LLMs) often lack culture-specific knowledge of daily life, especially across diverse regions and non-English languages. Existing benchmarks for evaluating LLMs' cultural sensitivities are limited to a single language or collected from online sources such as Wikipedia, which do not reflect the mundane everyday lifestyles of diverse regions. That is, information about the food people eat for their birthday celebrations, spices they typically use, musical instruments youngsters play, or the sports they practice in school is common cultural knowledge but uncommon in easily collected online sources, especially for underrepresented cultures. To address this issue, we introduce BLEnD, a hand-crafted benchmark designed to evaluate LLMs' everyday knowledge across diverse cultures and languages. BLEnD comprises 52.6k question-answer pairs from 16 countries/regions, in 13 different languages, including low-resource ones such as Amharic, Assamese, Azerbaijani, Hausa, and Sundanese. We construct the benchmark to include two formats of questions: short-answer and multiple-choice. We show that LLMs perform better for cultures that are highly represented online, with a maximum 57.34% difference in GPT-4, the best-performing model, in the short-answer format. For cultures represented by mid-to-high-resource languages, LLMs perform better in their local languages, but for cultures represented by low-resource languages, LLMs perform better in English than the local languages. We make our dataset publicly available at: https://github.com/nlee0212/BLEnD.
Hoaxpedia: A Unified Wikipedia Hoax Articles Dataset
May 03, 2024



Hoaxes are a recognised form of disinformation created deliberately, with potential serious implications in the credibility of reference knowledge resources such as Wikipedia. What makes detecting Wikipedia hoaxes hard is that they often are written according to the official style guidelines. In this work, we first provide a systematic analysis of the similarities and discrepancies between legitimate and hoax Wikipedia articles, and introduce Hoaxpedia, a collection of 311 Hoax articles (from existing literature as well as official Wikipedia lists) alongside semantically similar real articles. We report results of binary classification experiments in the task of predicting whether a Wikipedia article is real or hoax, and analyze several settings as well as a range of language models. Our results suggest that detecting deceitful content in Wikipedia based on content alone, despite not having been explored much in the past, is a promising direction.
WIKITIDE: A Wikipedia-Based Timestamped Definition Pairs Dataset
Aug 18, 2023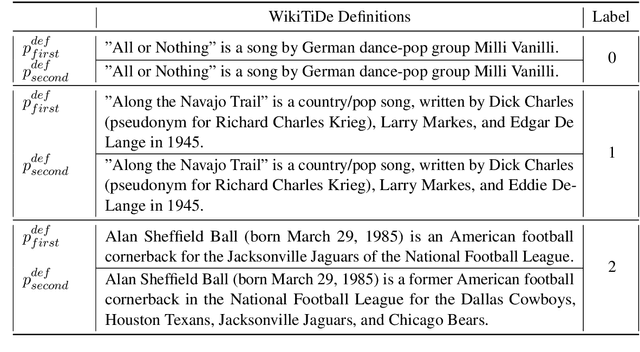
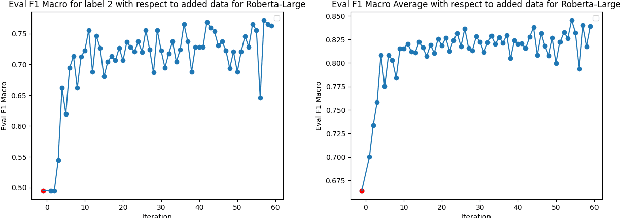
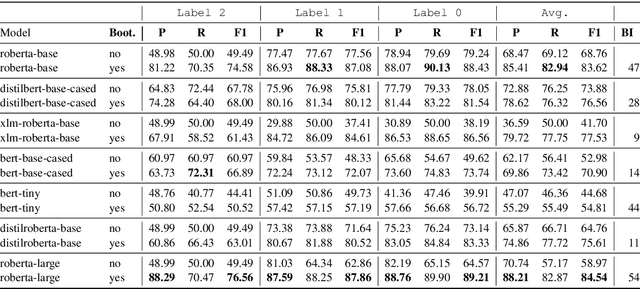
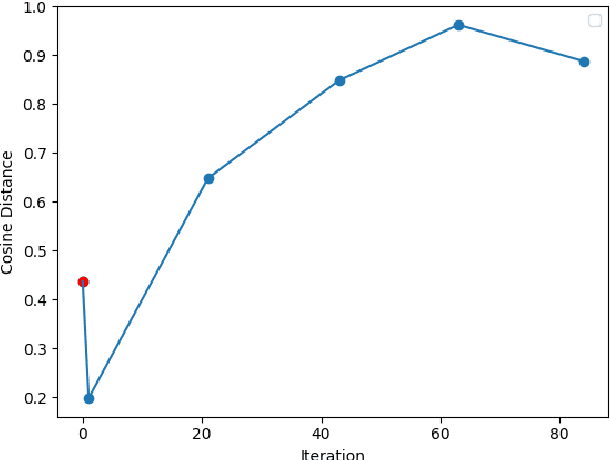
A fundamental challenge in the current NLP context, dominated by language models, comes from the inflexibility of current architectures to 'learn' new information. While model-centric solutions like continual learning or parameter-efficient fine tuning are available, the question still remains of how to reliably identify changes in language or in the world. In this paper, we propose WikiTiDe, a dataset derived from pairs of timestamped definitions extracted from Wikipedia. We argue that such resource can be helpful for accelerating diachronic NLP, specifically, for training models able to scan knowledge resources for core updates concerning a concept, an event, or a named entity. Our proposed end-to-end method is fully automatic, and leverages a bootstrapping algorithm for gradually creating a high-quality dataset. Our results suggest that bootstrapping the seed version of WikiTiDe leads to better fine-tuned models. We also leverage fine-tuned models in a number of downstream tasks, showing promising results with respect to competitive baselines.