 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models
Dec 15, 2025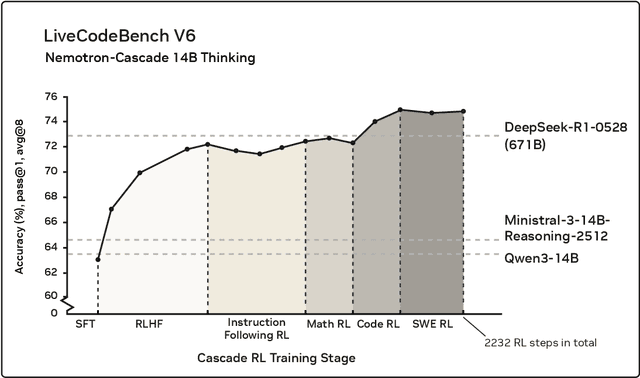
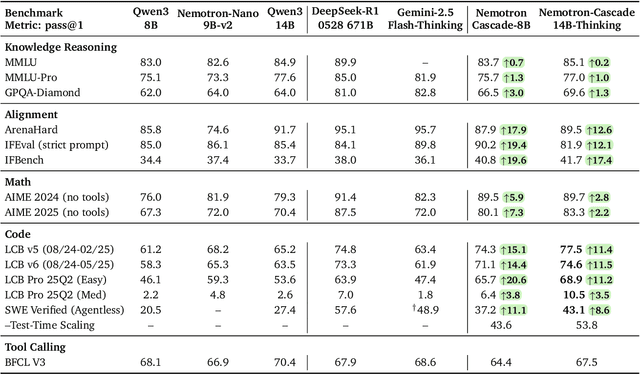
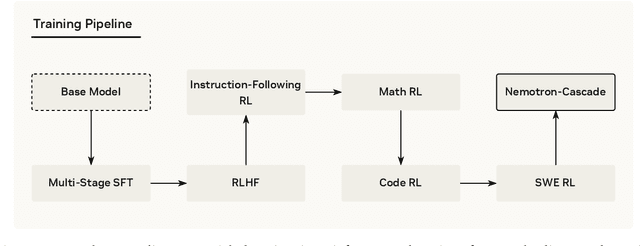
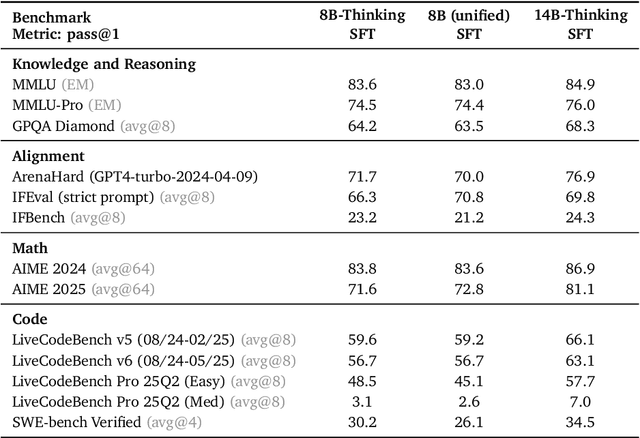
Building general-purpose reasoning models with reinforcement learning (RL) entails substantial cross-domain heterogeneity, including large variation in inference-time response lengths and verification latency. Such variability complicates the RL infrastructure, slows training, and makes training curriculum (e.g., response length extension) and hyperparameter selection challenging. In this work, we propose cascaded domain-wise reinforcement learning (Cascade RL) to develop general-purpose reasoning models, Nemotron-Cascade, capable of operating in both instruct and deep thinking modes. Departing from conventional approaches that blend heterogeneous prompts from different domains, Cascade RL orchestrates sequential, domain-wise RL, reducing engineering complexity and delivering state-of-the-art performance across a wide range of benchmarks. Notably, RLHF for alignment, when used as a pre-step, boosts the model's reasoning ability far beyond mere preference optimization, and subsequent domain-wise RLVR stages rarely degrade the benchmark performance attained in earlier domains and may even improve it (see an illustration in Figure 1). Our 14B model, after RL, outperforms its SFT teacher, DeepSeek-R1-0528, on LiveCodeBench v5/v6/Pro and achieves silver-medal performance in the 2025 International Olympiad in Informatics (IOI). We transparently share our training and data recipes.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Mar 18, 2025Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, Cosmos-Reason1-8B and Cosmos-Reason1-56B. We curate data and train our models in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL) as the post-training. To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and reinforcement learning bring significant improvements. To facilitate the development of Physical AI, we will make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
NVLM: Open Frontier-Class Multimodal LLMs
Sep 17, 2024

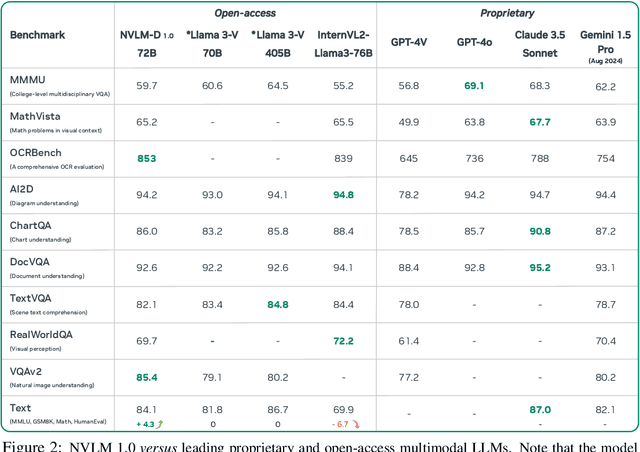

We introduce NVLM 1.0, a family of frontier-class multimodal large language models (LLMs) that achieve state-of-the-art results on vision-language tasks, rivaling the leading proprietary models (e.g., GPT-4o) and open-access models (e.g., Llama 3-V 405B and InternVL 2). Remarkably, NVLM 1.0 shows improved text-only performance over its LLM backbone after multimodal training. In terms of model design, we perform a comprehensive comparison between decoder-only multimodal LLMs (e.g., LLaVA) and cross-attention-based models (e.g., Flamingo). Based on the strengths and weaknesses of both approaches, we propose a novel architecture that enhances both training efficiency and multimodal reasoning capabilities. Furthermore, we introduce a 1-D tile-tagging design for tile-based dynamic high-resolution images, which significantly boosts performance on multimodal reasoning and OCR-related tasks. Regarding training data, we meticulously curate and provide detailed information on our multimodal pretraining and supervised fine-tuning datasets. Our findings indicate that dataset quality and task diversity are more important than scale, even during the pretraining phase, across all architectures. Notably, we develop production-grade multimodality for the NVLM-1.0 models, enabling them to excel in vision-language tasks while maintaining and even improving text-only performance compared to their LLM backbones. To achieve this, we craft and integrate a high-quality text-only dataset into multimodal training, alongside a substantial amount of multimodal math and reasoning data, leading to enhanced math and coding capabilities across modalities. To advance research in the field, we are releasing the model weights and will open-source the code for the community: https://nvlm-project.github.io/.
BLEnD: A Benchmark for LLMs on Everyday Knowledge in Diverse Cultures and Languages
Jun 14, 2024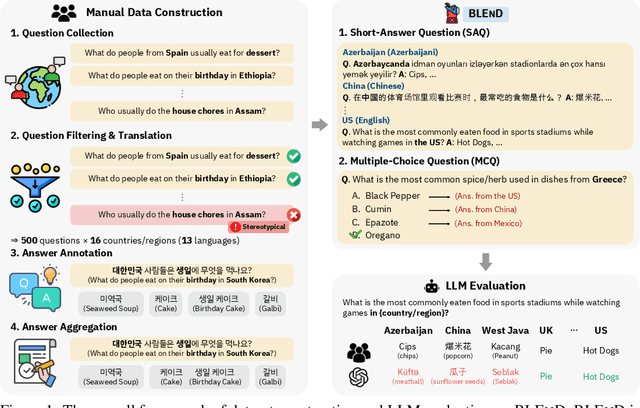
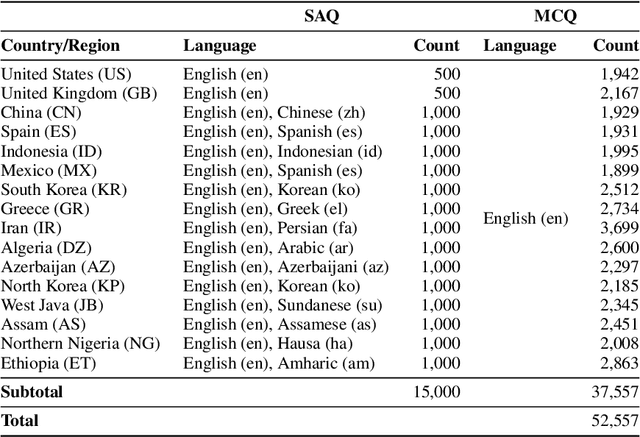
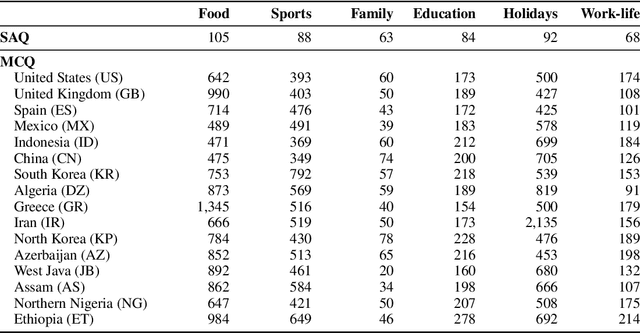
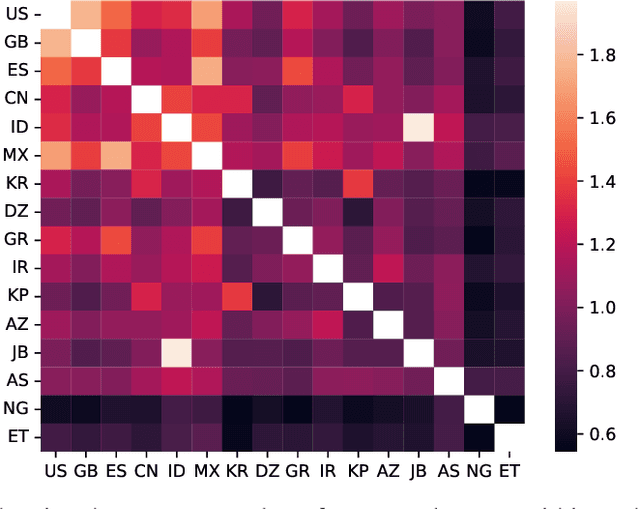
Large language models (LLMs) often lack culture-specific knowledge of daily life, especially across diverse regions and non-English languages. Existing benchmarks for evaluating LLMs' cultural sensitivities are limited to a single language or collected from online sources such as Wikipedia, which do not reflect the mundane everyday lifestyles of diverse regions. That is, information about the food people eat for their birthday celebrations, spices they typically use, musical instruments youngsters play, or the sports they practice in school is common cultural knowledge but uncommon in easily collected online sources, especially for underrepresented cultures. To address this issue, we introduce BLEnD, a hand-crafted benchmark designed to evaluate LLMs' everyday knowledge across diverse cultures and languages. BLEnD comprises 52.6k question-answer pairs from 16 countries/regions, in 13 different languages, including low-resource ones such as Amharic, Assamese, Azerbaijani, Hausa, and Sundanese. We construct the benchmark to include two formats of questions: short-answer and multiple-choice. We show that LLMs perform better for cultures that are highly represented online, with a maximum 57.34% difference in GPT-4, the best-performing model, in the short-answer format. For cultures represented by mid-to-high-resource languages, LLMs perform better in their local languages, but for cultures represented by low-resource languages, LLMs perform better in English than the local languages. We make our dataset publicly available at: https://github.com/nlee0212/BLEnD.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Measuring Political Bias in Large Language Models: What Is Said and How It Is Said
Mar 27, 2024

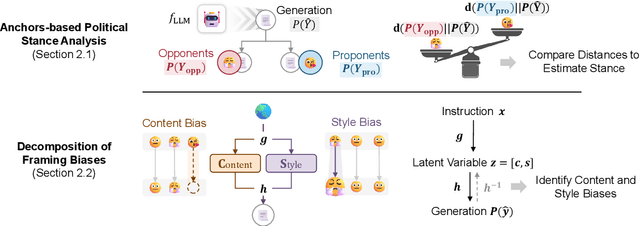

We propose to measure political bias in LLMs by analyzing both the content and style of their generated content regarding political issues. Existing benchmarks and measures focus on gender and racial biases. However, political bias exists in LLMs and can lead to polarization and other harms in downstream applications. In order to provide transparency to users, we advocate that there should be fine-grained and explainable measures of political biases generated by LLMs. Our proposed measure looks at different political issues such as reproductive rights and climate change, at both the content (the substance of the generation) and the style (the lexical polarity) of such bias. We measured the political bias in eleven open-sourced LLMs and showed that our proposed framework is easily scalable to other topics and is explainable.
Mitigating Framing Bias with Polarity Minimization Loss
Nov 03, 2023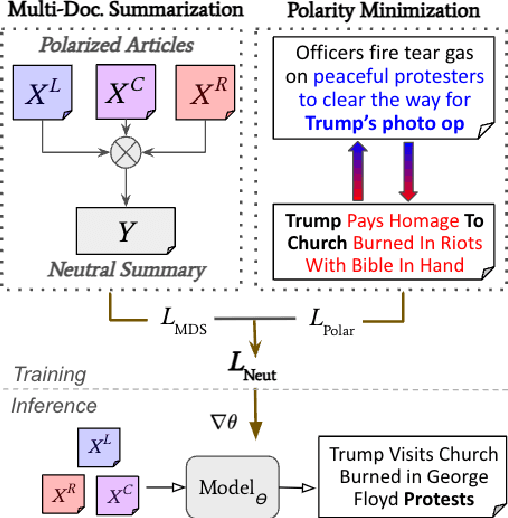
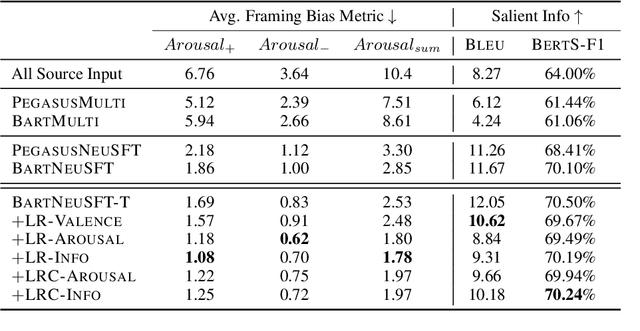

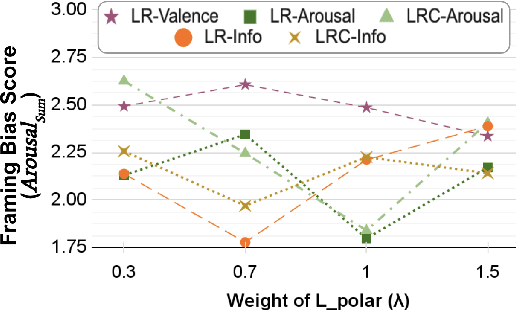
Framing bias plays a significant role in exacerbating political polarization by distorting the perception of actual events. Media outlets with divergent political stances often use polarized language in their reporting of the same event. We propose a new loss function that encourages the model to minimize the polarity difference between the polarized input articles to reduce framing bias. Specifically, our loss is designed to jointly optimize the model to map polarity ends bidirectionally. Our experimental results demonstrate that incorporating the proposed polarity minimization loss leads to a substantial reduction in framing bias when compared to a BART-based multi-document summarization model. Notably, we find that the effectiveness of this approach is most pronounced when the model is trained to minimize the polarity loss associated with informational framing bias (i.e., skewed selection of information to report).
Towards Mitigating Hallucination in Large Language Models via Self-Reflection
Oct 10, 2023

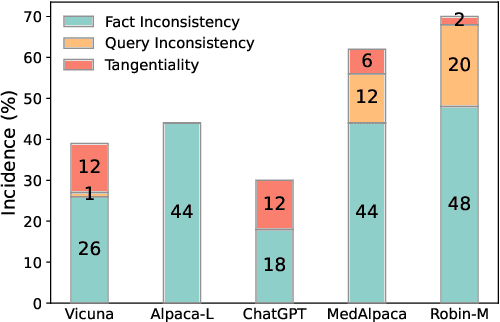

Large language models (LLMs) have shown promise for generative and knowledge-intensive tasks including question-answering (QA) tasks. However, the practical deployment still faces challenges, notably the issue of "hallucination", where models generate plausible-sounding but unfaithful or nonsensical information. This issue becomes particularly critical in the medical domain due to the uncommon professional concepts and potential social risks involved. This paper analyses the phenomenon of hallucination in medical generative QA systems using widely adopted LLMs and datasets. Our investigation centers on the identification and comprehension of common problematic answers, with a specific emphasis on hallucination. To tackle this challenge, we present an interactive self-reflection methodology that incorporates knowledge acquisition and answer generation. Through this feedback process, our approach steadily enhances the factuality, consistency, and entailment of the generated answers. Consequently, we harness the interactivity and multitasking ability of LLMs and produce progressively more precise and accurate answers. Experimental results on both automatic and human evaluation demonstrate the superiority of our approach in hallucination reduction compared to baselines.