 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Adapts to Any: Meta Reward Modeling for Personalized LLM Alignment
Jan 26, 2026Alignment of Large Language Models (LLMs) aims to align outputs with human preferences, and personalized alignment further adapts models to individual users. This relies on personalized reward models that capture user-specific preferences and automatically provide individualized feedback. However, developing these models faces two critical challenges: the scarcity of feedback from individual users and the need for efficient adaptation to unseen users. We argue that addressing these constraints requires a paradigm shift from fitting data to learn user preferences to learn the process of preference adaptation. To realize this, we propose Meta Reward Modeling (MRM), which reformulates personalized reward modeling as a meta-learning problem. Specifically, we represent each user's reward model as a weighted combination of base reward functions, and optimize the initialization of these weights using a Model-Agnostic Meta-Learning (MAML)-style framework to support fast adaptation under limited feedback. To ensure robustness, we introduce the Robust Personalization Objective (RPO), which places greater emphasis on hard-to-learn users during meta optimization. Extensive experiments on personalized preference datasets validate that MRM enhances few-shot personalization, improves user robustness, and consistently outperforms baselines.
Agent-as-a-Judge
Jan 08, 2026LLM-as-a-Judge has revolutionized AI evaluation by leveraging large language models for scalable assessments. However, as evaluands become increasingly complex, specialized, and multi-step, the reliability of LLM-as-a-Judge has become constrained by inherent biases, shallow single-pass reasoning, and the inability to verify assessments against real-world observations. This has catalyzed the transition to Agent-as-a-Judge, where agentic judges employ planning, tool-augmented verification, multi-agent collaboration, and persistent memory to enable more robust, verifiable, and nuanced evaluations. Despite the rapid proliferation of agentic evaluation systems, the field lacks a unified framework to navigate this shifting landscape. To bridge this gap, we present the first comprehensive survey tracing this evolution. Specifically, we identify key dimensions that characterize this paradigm shift and establish a developmental taxonomy. We organize core methodologies and survey applications across general and professional domains. Furthermore, we analyze frontier challenges and identify promising research directions, ultimately providing a clear roadmap for the next generation of agentic evaluation.
InSight-o3: Empowering Multimodal Foundation Models with Generalized Visual Search
Dec 21, 2025The ability for AI agents to "think with images" requires a sophisticated blend of reasoning and perception. However, current open multimodal agents still largely fall short on the reasoning aspect crucial for real-world tasks like analyzing documents with dense charts/diagrams and navigating maps. To address this gap, we introduce O3-Bench, a new benchmark designed to evaluate multimodal reasoning with interleaved attention to visual details. O3-Bench features challenging problems that require agents to piece together subtle visual information from distinct image areas through multi-step reasoning. The problems are highly challenging even for frontier systems like OpenAI o3, which only obtains 40.8% accuracy on O3-Bench. To make progress, we propose InSight-o3, a multi-agent framework consisting of a visual reasoning agent (vReasoner) and a visual search agent (vSearcher) for which we introduce the task of generalized visual search -- locating relational, fuzzy, or conceptual regions described in free-form language, beyond just simple objects or figures in natural images. We then present a multimodal LLM purpose-trained for this task via reinforcement learning. As a plug-and-play agent, our vSearcher empowers frontier multimodal models (as vReasoners), significantly improving their performance on a wide range of benchmarks. This marks a concrete step towards powerful o3-like open systems. Our code and dataset can be found at https://github.com/m-Just/InSight-o3 .
The Synergy Dilemma of Long-CoT SFT and RL: Investigating Post-Training Techniques for Reasoning VLMs
Jul 10, 2025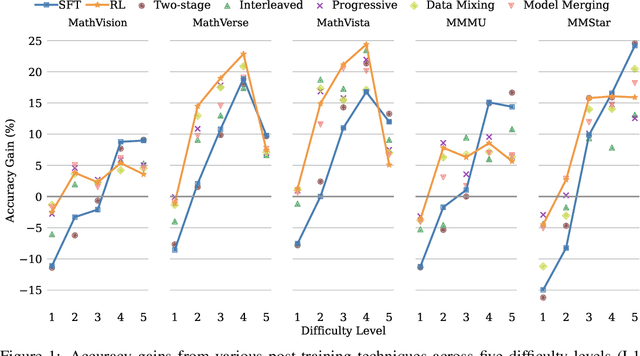
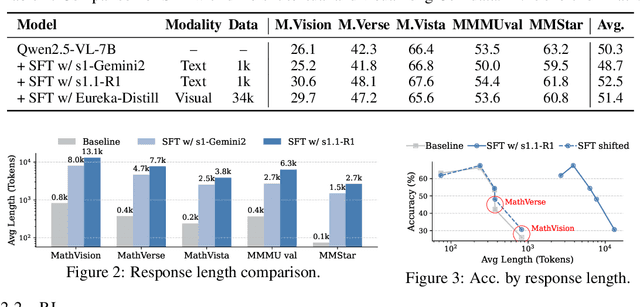
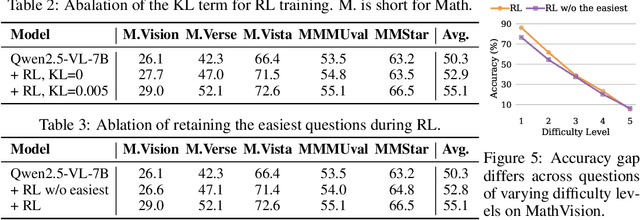
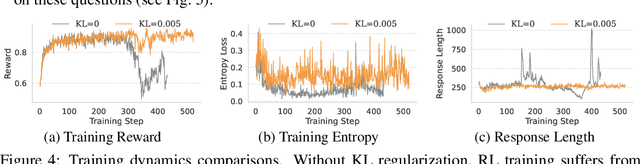
Large vision-language models (VLMs) increasingly adopt post-training techniques such as long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL) to elicit sophisticated reasoning. While these methods exhibit synergy in language-only models, their joint effectiveness in VLMs remains uncertain. We present a systematic investigation into the distinct roles and interplay of long-CoT SFT and RL across multiple multimodal reasoning benchmarks. We find that SFT improves performance on difficult questions by in-depth, structured reasoning, but introduces verbosity and degrades performance on simpler ones. In contrast, RL promotes generalization and brevity, yielding consistent improvements across all difficulty levels, though the improvements on the hardest questions are less prominent compared to SFT. Surprisingly, combining them through two-staged, interleaved, or progressive training strategies, as well as data mixing and model merging, all fails to produce additive benefits, instead leading to trade-offs in accuracy, reasoning style, and response length. This ``synergy dilemma'' highlights the need for more seamless and adaptive approaches to unlock the full potential of combined post-training techniques for reasoning VLMs.
Quantization Hurts Reasoning? An Empirical Study on Quantized Reasoning Models
Apr 07, 2025Recent advancements in reasoning language models have demonstrated remarkable performance in complex tasks, but their extended chain-of-thought reasoning process increases inference overhead. While quantization has been widely adopted to reduce the inference cost of large language models, its impact on reasoning models remains understudied. In this study, we conduct the first systematic study on quantized reasoning models, evaluating the open-sourced DeepSeek-R1-Distilled Qwen and LLaMA families ranging from 1.5B to 70B parameters, and QwQ-32B. Our investigation covers weight, KV cache, and activation quantization using state-of-the-art algorithms at varying bit-widths, with extensive evaluation across mathematical (AIME, MATH-500), scientific (GPQA), and programming (LiveCodeBench) reasoning benchmarks. Our findings reveal that while lossless quantization can be achieved with W8A8 or W4A16 quantization, lower bit-widths introduce significant accuracy risks. We further identify model size, model origin, and task difficulty as critical determinants of performance. Contrary to expectations, quantized models do not exhibit increased output lengths. In addition, strategically scaling the model sizes or reasoning steps can effectively enhance the performance. All quantized models and codes will be open-sourced in https://github.com/ruikangliu/Quantized-Reasoning-Models.
Learning to Align Multi-Faceted Evaluation: A Unified and Robust Framework
Feb 26, 2025Large Language Models (LLMs) are being used more and more extensively for automated evaluation in various scenarios. Previous studies have attempted to fine-tune open-source LLMs to replicate the evaluation explanations and judgments of powerful proprietary models, such as GPT-4. However, these methods are largely limited to text-based analyses under predefined general criteria, resulting in reduced adaptability for unseen instructions and demonstrating instability in evaluating adherence to quantitative and structural constraints. To address these limitations, we propose a novel evaluation framework, ARJudge, that adaptively formulates evaluation criteria and synthesizes both text-based and code-driven analyses to evaluate LLM responses. ARJudge consists of two components: a fine-tuned Analyzer that generates multi-faceted evaluation analyses and a tuning-free Refiner that combines and refines all analyses to make the final judgment. We construct a Composite Analysis Corpus that integrates tasks for evaluation criteria generation alongside text-based and code-driven analysis generation to train the Analyzer. Our results demonstrate that ARJudge outperforms existing fine-tuned evaluators in effectiveness and robustness. Furthermore, it demonstrates the importance of multi-faceted evaluation and code-driven analyses in enhancing evaluation capabilities.
Subtle Errors Matter: Preference Learning via Error-injected Self-editing
Oct 09, 2024


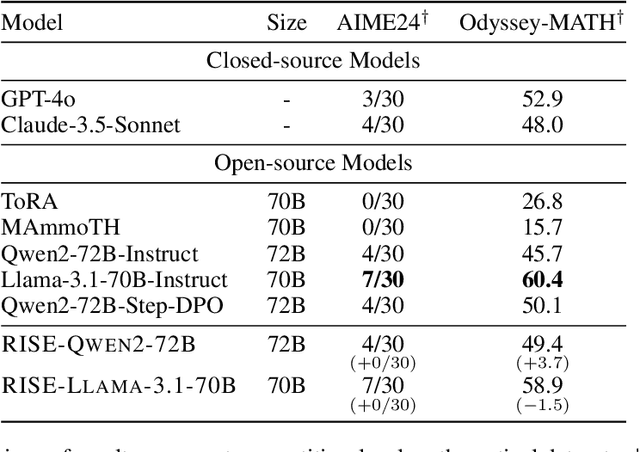
Large Language Models (LLMs) have exhibited strong mathematical reasoning and computational prowess, tackling tasks ranging from basic arithmetic to advanced competition-level problems. However, frequently occurring subtle errors, such as miscalculations or incorrect substitutions, limit the models' full mathematical potential. Existing studies to improve mathematical ability typically involve distilling reasoning skills from stronger LLMs or applying preference learning to step-wise response pairs. Although these methods leverage samples of varying granularity to mitigate reasoning errors, they overlook the frequently occurring subtle errors. A major reason is that sampled preference pairs involve differences unrelated to the errors, which may distract the model from focusing on subtle errors. In this work, we propose a novel preference learning framework called eRror-Injected Self-Editing (RISE), which injects predefined subtle errors into partial tokens of correct solutions to construct hard pairs for error mitigation. In detail, RISE uses the model itself to edit a small number of tokens in the solution, injecting designed subtle errors. Then, pairs composed of self-edited solutions and their corresponding correct ones, along with pairs of correct and incorrect solutions obtained through sampling, are used together for subtle error-aware DPO training. Compared with other preference learning methods, RISE further refines the training objective to focus on predefined errors and their tokens, without requiring fine-grained sampling or preference annotation. Extensive experiments validate the effectiveness of RISE, with preference learning on Qwen2-7B-Instruct yielding notable improvements of 3.0% on GSM8K and 7.9% on MATH.
Towards Mitigating Hallucination in Large Language Models via Self-Reflection
Oct 10, 2023

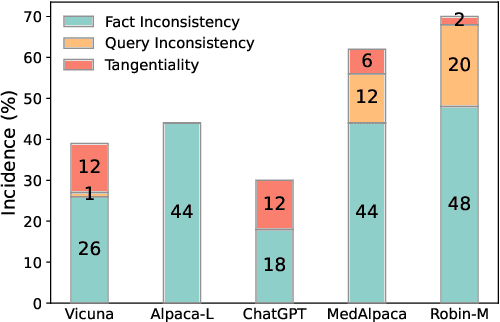

Large language models (LLMs) have shown promise for generative and knowledge-intensive tasks including question-answering (QA) tasks. However, the practical deployment still faces challenges, notably the issue of "hallucination", where models generate plausible-sounding but unfaithful or nonsensical information. This issue becomes particularly critical in the medical domain due to the uncommon professional concepts and potential social risks involved. This paper analyses the phenomenon of hallucination in medical generative QA systems using widely adopted LLMs and datasets. Our investigation centers on the identification and comprehension of common problematic answers, with a specific emphasis on hallucination. To tackle this challenge, we present an interactive self-reflection methodology that incorporates knowledge acquisition and answer generation. Through this feedback process, our approach steadily enhances the factuality, consistency, and entailment of the generated answers. Consequently, we harness the interactivity and multitasking ability of LLMs and produce progressively more precise and accurate answers. Experimental results on both automatic and human evaluation demonstrate the superiority of our approach in hallucination reduction compared to baselines.
Improving Query-Focused Meeting Summarization with Query-Relevant Knowledge
Sep 05, 2023Query-Focused Meeting Summarization (QFMS) aims to generate a summary of a given meeting transcript conditioned upon a query. The main challenges for QFMS are the long input text length and sparse query-relevant information in the meeting transcript. In this paper, we propose a knowledge-enhanced two-stage framework called Knowledge-Aware Summarizer (KAS) to tackle the challenges. In the first stage, we introduce knowledge-aware scores to improve the query-relevant segment extraction. In the second stage, we incorporate query-relevant knowledge in the summary generation. Experimental results on the QMSum dataset show that our approach achieves state-of-the-art performance. Further analysis proves the competency of our methods in generating relevant and faithful summaries.
Instruct-Align: Teaching Novel Languages with to LLMs through Alignment-based Cross-Lingual Instruction
May 23, 2023Instruction-tuned large language models (LLMs) have shown remarkable generalization capability over multiple tasks in multiple languages. Nevertheless, their generalization towards different languages varies especially to underrepresented languages or even to unseen languages. Prior works on adapting new languages to LLMs find that naively adapting new languages to instruction-tuned LLMs will result in catastrophic forgetting, which in turn causes the loss of multitasking ability in these LLMs. To tackle this, we propose the Instruct-Align a.k.a (IA)$^1$ framework, which enables instruction-tuned LLMs to learn cross-lingual alignment between unseen and previously learned languages via alignment-based cross-lingual instruction-tuning. Our preliminary result on BLOOMZ-560M shows that (IA)$^1$ is able to learn a new language effectively with only a limited amount of parallel data and at the same time prevent catastrophic forgetting by applying continual instruction-tuning through experience replay. Our work contributes to the progression of language adaptation methods for instruction-tuned LLMs and opens up the possibility of adapting underrepresented low-resource languages into existing instruction-tuned LLMs. Our code will be publicly released upon acceptance.