 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBATQuant: Outlier-resilient MXFP4 Quantization via Learnable Block-wise Optimization
Mar 17, 2026Microscaling floating-point (MXFP) formats have emerged as a promising standard for deploying Multi-modal Large Language Models (MLLMs) and Large Language Models (LLMs) on modern accelerator architectures. However, existing Post-Training Quantization (PTQ) methods, particularly rotation-based techniques designed for integer formats, suffer from severe performance collapse when applied to MXFP4. Recent studies attribute this failure to a fundamental format mismatch: global orthogonal rotations inadvertently transfer outlier energy across quantization blocks, inducing new outliers that disrupt local block-wise scaling, while often creating bimodal activation distributions that underutilize the limited quantization range. To address these issues, we propose BATQuant (Block-wise Affine Transformation), which restricts transformations to align with MXFP granularity to prevent cross-block outlier propagation, while relaxing orthogonality constraints to optimize distribution shaping. To ensure parameter efficiency, we introduce Global and Private Kronecker (GPK) decomposition to effectively reduces storage and runtime overhead and incorporate Block-wise Learnable Clipping to suppress residual outliers. Extensive experiments on both MLLMs and LLMs demonstrate that BATQuant establishes new state-of-the-art results under aggressive W4A4KV16 configurations, recovering up to 96.43% of full-precision performance on multimodal benchmarks and clearly outperforming existing methods across diverse tasks.
FreeAct: Freeing Activations for LLM Quantization
Mar 05, 2026Quantization is pivotal for mitigating the significant memory and computational overhead of Large Language Models (LLMs). While emerging transformation-based methods have successfully enhanced quantization by projecting feature spaces onto smoother manifolds using orthogonal matrices, they typically enforce a rigid one-to-one transformation constraint. This static approach fails to account for the dynamic patterns inherent in input activations, particularly within diffusion LLMs (dLLMs) and Multimodal LLMs (MLLMs), where varying token types exhibit distinct distributions. To advance this, we propose FreeAct, a novel quantization framework that relaxes the static one-to-one constraint to accommodate dynamic activation disparities. Theoretically, we leverage the rank-deficient nature of activations to derive a solution space that extends beyond simple inverse matrices, enabling the decoupling of activation transformations from weights. Methodologically, FreeAct identifies token-specific dynamics (i.e., vision v.s. text, or masked tokens) and allocates distinct transformation matrices to the activation side, while maintaining a unified, static transformation for the weights. Extensive experiments across dLLMs and MLLMs demonstrate that FreeAct significantly outperforms baselines, up to 5.3% performance improvement, with in-depth analyses. Our code will be publicly released.
What Makes Low-Bit Quantization-Aware Training Work for Reasoning LLMs? A Systematic Study
Jan 21, 2026Reasoning models excel at complex tasks such as coding and mathematics, yet their inference is often slow and token-inefficient. To improve the inference efficiency, post-training quantization (PTQ) usually comes with the cost of large accuracy drops, especially for reasoning tasks under low-bit settings. In this study, we present a systematic empirical study of quantization-aware training (QAT) for reasoning models. Our key findings include: (1) Knowledge distillation is a robust objective for reasoning models trained via either supervised fine-tuning or reinforcement learning; (2) PTQ provides a strong initialization for QAT, improving accuracy while reducing training cost; (3) Reinforcement learning remains feasible for quantized models given a viable cold start and yields additional gains; and (4) Aligning the PTQ calibration domain with the QAT training domain accelerates convergence and often improves the final accuracy. Finally, we consolidate these findings into an optimized workflow (Reasoning-QAT), and show that it consistently outperforms state-of-the-art PTQ methods across multiple LLM backbones and reasoning datasets. For instance, on Qwen3-0.6B, it surpasses GPTQ by 44.53% on MATH-500 and consistently recovers performance in the 2-bit regime.
Benchmarking Post-Training Quantization of Large Language Models under Microscaling Floating Point Formats
Jan 14, 2026Microscaling Floating-Point (MXFP) has emerged as a promising low-precision format for large language models (LLMs). Despite various post-training quantization (PTQ) algorithms being proposed, they mostly focus on integer quantization, while their applicability and behavior under MXFP formats remain largely unexplored. To address this gap, this work conducts a systematic investigation of PTQ under MXFP formats, encompassing over 7 PTQ algorithms, 15 evaluation benchmarks, and 3 LLM families. The key findings include: 1) MXFP8 consistently achieves near-lossless performance, while MXFP4 introduces substantial accuracy degradation and remains challenging; 2) PTQ effectiveness under MXFP depends strongly on format compatibility, with some algorithmic paradigms being consistently more effective than others; 3) PTQ performance exhibits highly consistent trends across model families and modalities, in particular, quantization sensitivity is dominated by the language model rather than the vision encoder in multimodal LLMs; 4) The scaling factor of quantization is a critical error source in MXFP4, and a simple pre-scale optimization strategy can significantly mitigate its impact. Together, these results provide practical guidance on adapting existing PTQ methods to MXFP quantization.
The Synergy Dilemma of Long-CoT SFT and RL: Investigating Post-Training Techniques for Reasoning VLMs
Jul 10, 2025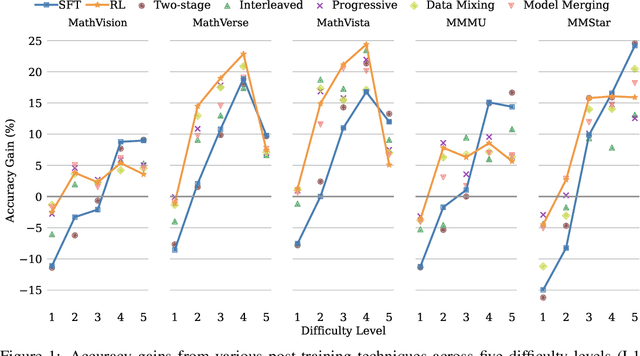
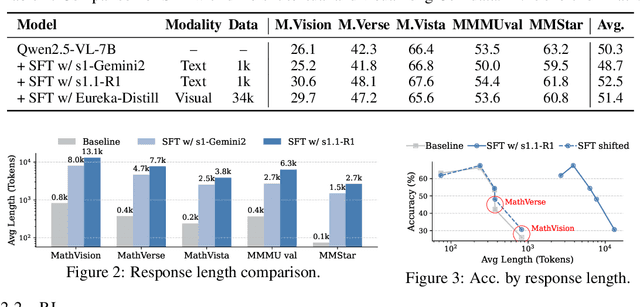
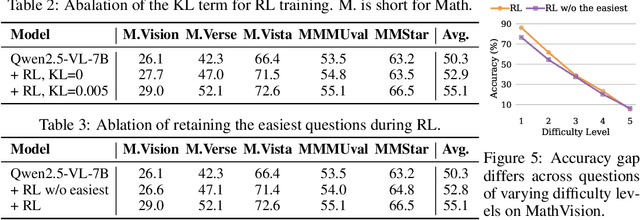
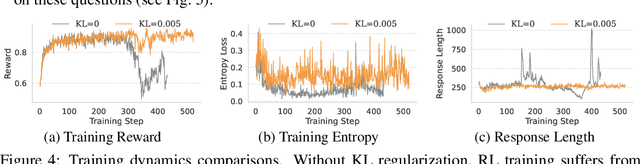
Large vision-language models (VLMs) increasingly adopt post-training techniques such as long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL) to elicit sophisticated reasoning. While these methods exhibit synergy in language-only models, their joint effectiveness in VLMs remains uncertain. We present a systematic investigation into the distinct roles and interplay of long-CoT SFT and RL across multiple multimodal reasoning benchmarks. We find that SFT improves performance on difficult questions by in-depth, structured reasoning, but introduces verbosity and degrades performance on simpler ones. In contrast, RL promotes generalization and brevity, yielding consistent improvements across all difficulty levels, though the improvements on the hardest questions are less prominent compared to SFT. Surprisingly, combining them through two-staged, interleaved, or progressive training strategies, as well as data mixing and model merging, all fails to produce additive benefits, instead leading to trade-offs in accuracy, reasoning style, and response length. This ``synergy dilemma'' highlights the need for more seamless and adaptive approaches to unlock the full potential of combined post-training techniques for reasoning VLMs.
L-MTP: Leap Multi-Token Prediction Beyond Adjacent Context for Large Language Models
May 23, 2025Large language models (LLMs) have achieved notable progress. Despite their success, next-token prediction (NTP), the dominant method for LLM training and inference, is constrained in both contextual coverage and inference efficiency due to its inherently sequential process. To overcome these challenges, we propose leap multi-token prediction~(L-MTP), an innovative token prediction method that extends the capabilities of multi-token prediction (MTP) by introducing a leap-based mechanism. Unlike conventional MTP, which generates multiple tokens at adjacent positions, L-MTP strategically skips over intermediate tokens, predicting non-sequential ones in a single forward pass. This structured leap not only enhances the model's ability to capture long-range dependencies but also enables a decoding strategy specially optimized for non-sequential leap token generation, effectively accelerating inference. We theoretically demonstrate the benefit of L-MTP in improving inference efficiency. Experiments across diverse benchmarks validate its merit in boosting both LLM performance and inference speed. The source code will be publicly available.
Quantization Hurts Reasoning? An Empirical Study on Quantized Reasoning Models
Apr 07, 2025Recent advancements in reasoning language models have demonstrated remarkable performance in complex tasks, but their extended chain-of-thought reasoning process increases inference overhead. While quantization has been widely adopted to reduce the inference cost of large language models, its impact on reasoning models remains understudied. In this study, we conduct the first systematic study on quantized reasoning models, evaluating the open-sourced DeepSeek-R1-Distilled Qwen and LLaMA families ranging from 1.5B to 70B parameters, and QwQ-32B. Our investigation covers weight, KV cache, and activation quantization using state-of-the-art algorithms at varying bit-widths, with extensive evaluation across mathematical (AIME, MATH-500), scientific (GPQA), and programming (LiveCodeBench) reasoning benchmarks. Our findings reveal that while lossless quantization can be achieved with W8A8 or W4A16 quantization, lower bit-widths introduce significant accuracy risks. We further identify model size, model origin, and task difficulty as critical determinants of performance. Contrary to expectations, quantized models do not exhibit increased output lengths. In addition, strategically scaling the model sizes or reasoning steps can effectively enhance the performance. All quantized models and codes will be open-sourced in https://github.com/ruikangliu/Quantized-Reasoning-Models.
Learning with Noisily-labeled Class-imbalanced Data
Nov 20, 2022
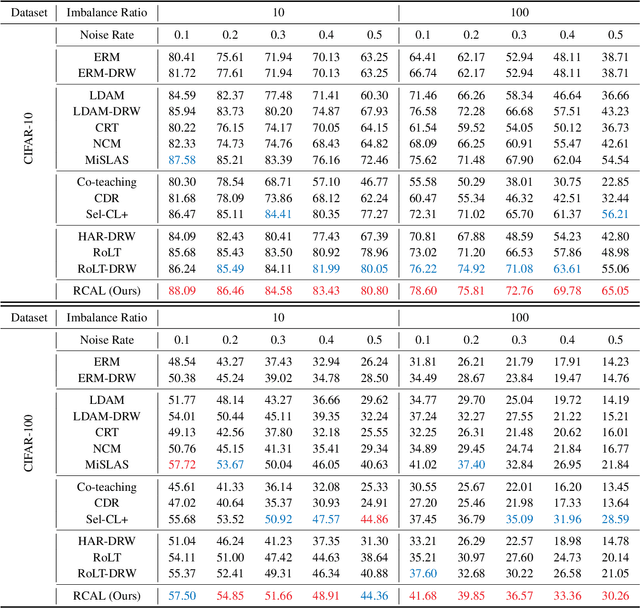

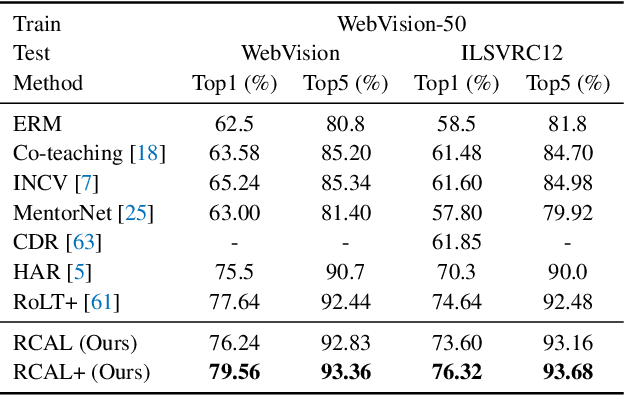
Real-world large-scale datasets are both noisily labeled and class-imbalanced. The issues seriously hurt the generalization of trained models. It is hence significant to address the simultaneous incorrect labeling and class-imbalance, i.e., the problem of learning with noisy labels on long-tailed data. Previous works develop several methods for the problem. However, they always rely on strong assumptions that are invalid or hard to be checked in practice. In this paper, to handle the problem and address the limitations of prior works, we propose a representation calibration method RCAL. Specifically, RCAL works with the representations extracted by unsupervised contrastive learning. We assume that without incorrect labeling and class imbalance, the representations of instances in each class conform to a multivariate Gaussian distribution, which is much milder and easier to be checked. Based on the assumption, we recover underlying representation distributions from polluted ones resulting from mislabeled and class-imbalanced data. Additional data points are then sampled from the recovered distributions to help generalization. Moreover, during classifier training, representation learning takes advantage of representation robustness brought by contrastive learning, which further improves the classifier performance. Experiments on multiple benchmarks justify our claims and confirm the superiority of the proposed method.
Tackling Instance-Dependent Label Noise with Dynamic Distribution Calibration
Oct 11, 2022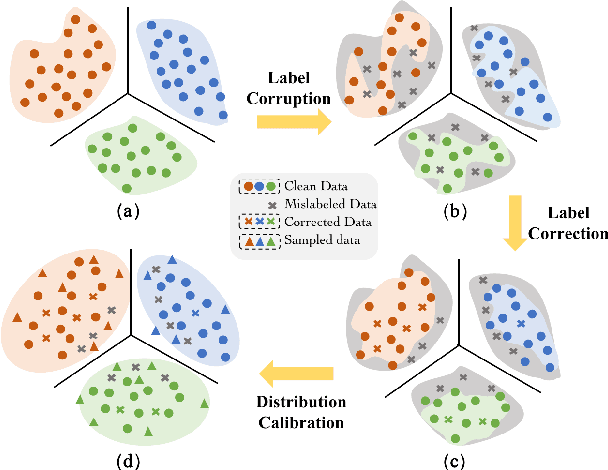
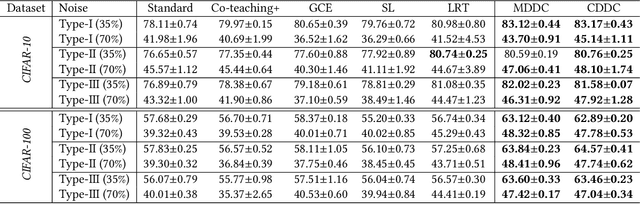
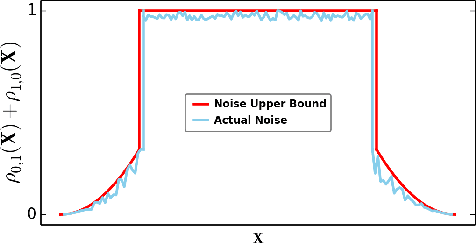
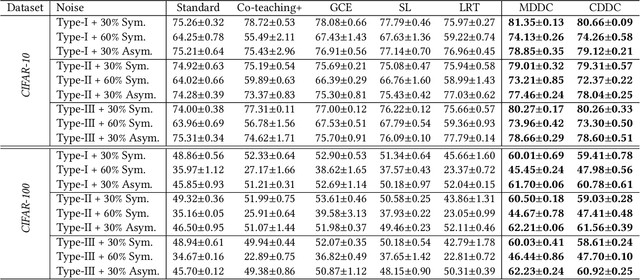
Instance-dependent label noise is realistic but rather challenging, where the label-corruption process depends on instances directly. It causes a severe distribution shift between the distributions of training and test data, which impairs the generalization of trained models. Prior works put great effort into tackling the issue. Unfortunately, these works always highly rely on strong assumptions or remain heuristic without theoretical guarantees. In this paper, to address the distribution shift in learning with instance-dependent label noise, a dynamic distribution-calibration strategy is adopted. Specifically, we hypothesize that, before training data are corrupted by label noise, each class conforms to a multivariate Gaussian distribution at the feature level. Label noise produces outliers to shift the Gaussian distribution. During training, to calibrate the shifted distribution, we propose two methods based on the mean and covariance of multivariate Gaussian distribution respectively. The mean-based method works in a recursive dimension-reduction manner for robust mean estimation, which is theoretically guaranteed to train a high-quality model against label noise. The covariance-based method works in a distribution disturbance manner, which is experimentally verified to improve the model robustness. We demonstrate the utility and effectiveness of our methods on datasets with synthetic label noise and real-world unknown noise.