 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAEQ-Bench: Measuring Empathy of Omni-Modal Large Models
Jan 15, 2026While the automatic evaluation of omni-modal large models (OLMs) is essential, assessing empathy remains a significant challenge due to its inherent affectivity. To investigate this challenge, we introduce AEQ-Bench (Audio Empathy Quotient Benchmark), a novel benchmark to systematically assess two core empathetic capabilities of OLMs: (i) generating empathetic responses by comprehending affective cues from multi-modal inputs (audio + text), and (ii) judging the empathy of audio responses without relying on text transcription. Compared to existing benchmarks, AEQ-Bench incorporates two novel settings that vary in context specificity and speech tone. Comprehensive assessment across linguistic and paralinguistic metrics reveals that (1) OLMs trained with audio output capabilities generally outperformed models with text-only outputs, and (2) while OLMs align with human judgments for coarse-grained quality assessment, they remain unreliable for evaluating fine-grained paralinguistic expressiveness.
InSight-o3: Empowering Multimodal Foundation Models with Generalized Visual Search
Dec 21, 2025The ability for AI agents to "think with images" requires a sophisticated blend of reasoning and perception. However, current open multimodal agents still largely fall short on the reasoning aspect crucial for real-world tasks like analyzing documents with dense charts/diagrams and navigating maps. To address this gap, we introduce O3-Bench, a new benchmark designed to evaluate multimodal reasoning with interleaved attention to visual details. O3-Bench features challenging problems that require agents to piece together subtle visual information from distinct image areas through multi-step reasoning. The problems are highly challenging even for frontier systems like OpenAI o3, which only obtains 40.8% accuracy on O3-Bench. To make progress, we propose InSight-o3, a multi-agent framework consisting of a visual reasoning agent (vReasoner) and a visual search agent (vSearcher) for which we introduce the task of generalized visual search -- locating relational, fuzzy, or conceptual regions described in free-form language, beyond just simple objects or figures in natural images. We then present a multimodal LLM purpose-trained for this task via reinforcement learning. As a plug-and-play agent, our vSearcher empowers frontier multimodal models (as vReasoners), significantly improving their performance on a wide range of benchmarks. This marks a concrete step towards powerful o3-like open systems. Our code and dataset can be found at https://github.com/m-Just/InSight-o3 .
The Synergy Dilemma of Long-CoT SFT and RL: Investigating Post-Training Techniques for Reasoning VLMs
Jul 10, 2025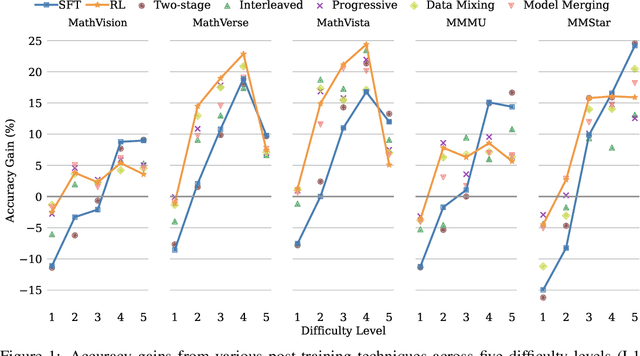
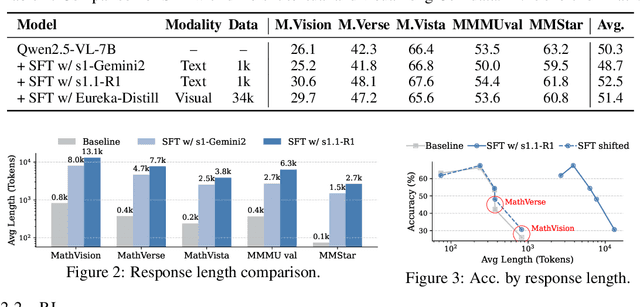
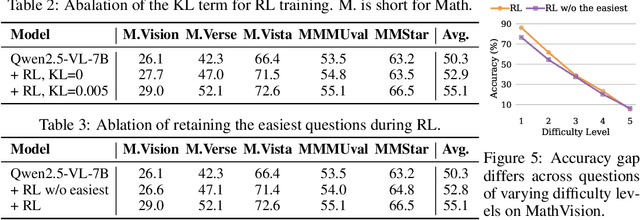
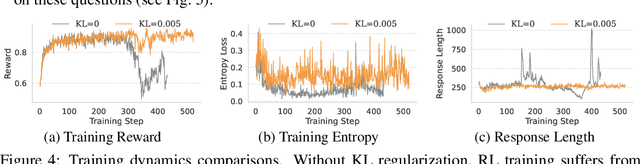
Large vision-language models (VLMs) increasingly adopt post-training techniques such as long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL) to elicit sophisticated reasoning. While these methods exhibit synergy in language-only models, their joint effectiveness in VLMs remains uncertain. We present a systematic investigation into the distinct roles and interplay of long-CoT SFT and RL across multiple multimodal reasoning benchmarks. We find that SFT improves performance on difficult questions by in-depth, structured reasoning, but introduces verbosity and degrades performance on simpler ones. In contrast, RL promotes generalization and brevity, yielding consistent improvements across all difficulty levels, though the improvements on the hardest questions are less prominent compared to SFT. Surprisingly, combining them through two-staged, interleaved, or progressive training strategies, as well as data mixing and model merging, all fails to produce additive benefits, instead leading to trade-offs in accuracy, reasoning style, and response length. This ``synergy dilemma'' highlights the need for more seamless and adaptive approaches to unlock the full potential of combined post-training techniques for reasoning VLMs.
DetCLIPv3: Towards Versatile Generative Open-vocabulary Object Detection
Apr 14, 2024



Existing open-vocabulary object detectors typically require a predefined set of categories from users, significantly confining their application scenarios. In this paper, we introduce DetCLIPv3, a high-performing detector that excels not only at both open-vocabulary object detection, but also generating hierarchical labels for detected objects. DetCLIPv3 is characterized by three core designs: 1. Versatile model architecture: we derive a robust open-set detection framework which is further empowered with generation ability via the integration of a caption head. 2. High information density data: we develop an auto-annotation pipeline leveraging visual large language model to refine captions for large-scale image-text pairs, providing rich, multi-granular object labels to enhance the training. 3. Efficient training strategy: we employ a pre-training stage with low-resolution inputs that enables the object captioner to efficiently learn a broad spectrum of visual concepts from extensive image-text paired data. This is followed by a fine-tuning stage that leverages a small number of high-resolution samples to further enhance detection performance. With these effective designs, DetCLIPv3 demonstrates superior open-vocabulary detection performance, \eg, our Swin-T backbone model achieves a notable 47.0 zero-shot fixed AP on the LVIS minival benchmark, outperforming GLIPv2, GroundingDINO, and DetCLIPv2 by 18.0/19.6/6.6 AP, respectively. DetCLIPv3 also achieves a state-of-the-art 19.7 AP in dense captioning task on VG dataset, showcasing its strong generative capability.
PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
Mar 07, 2024



In this paper, we introduce PixArt-\Sigma, a Diffusion Transformer model~(DiT) capable of directly generating images at 4K resolution. PixArt-\Sigma represents a significant advancement over its predecessor, PixArt-\alpha, offering images of markedly higher fidelity and improved alignment with text prompts. A key feature of PixArt-\Sigma is its training efficiency. Leveraging the foundational pre-training of PixArt-\alpha, it evolves from the `weaker' baseline to a `stronger' model via incorporating higher quality data, a process we term "weak-to-strong training". The advancements in PixArt-\Sigma are twofold: (1) High-Quality Training Data: PixArt-\Sigma incorporates superior-quality image data, paired with more precise and detailed image captions. (2) Efficient Token Compression: we propose a novel attention module within the DiT framework that compresses both keys and values, significantly improving efficiency and facilitating ultra-high-resolution image generation. Thanks to these improvements, PixArt-\Sigma achieves superior image quality and user prompt adherence capabilities with significantly smaller model size (0.6B parameters) than existing text-to-image diffusion models, such as SDXL (2.6B parameters) and SD Cascade (5.1B parameters). Moreover, PixArt-\Sigma's capability to generate 4K images supports the creation of high-resolution posters and wallpapers, efficiently bolstering the production of high-quality visual content in industries such as film and gaming.
PerceptionGPT: Effectively Fusing Visual Perception into LLM
Nov 11, 2023



The integration of visual inputs with large language models (LLMs) has led to remarkable advancements in multi-modal capabilities, giving rise to visual large language models (VLLMs). However, effectively harnessing VLLMs for intricate visual perception tasks remains a challenge. In this paper, we present a novel end-to-end framework named PerceptionGPT, which efficiently and effectively equips the VLLMs with visual perception abilities by leveraging the representation power of LLMs' token embedding. Our proposed method treats the token embedding of the LLM as the carrier of spatial information, then leverage lightweight visual task encoders and decoders to perform visual perception tasks (e.g., detection, segmentation). Our approach significantly alleviates the training difficulty suffered by previous approaches that formulate the visual outputs as discrete tokens, and enables achieving superior performance with fewer trainable parameters, less training data and shorted training time. Moreover, as only one token embedding is required to decode the visual outputs, the resulting sequence length during inference is significantly reduced. Consequently, our approach enables accurate and flexible representations, seamless integration of visual perception tasks, and efficient handling of a multiple of visual outputs. We validate the effectiveness and efficiency of our approach through extensive experiments. The results demonstrate significant improvements over previous methods with much fewer trainable parameters and GPU hours, which facilitates future research in enabling LLMs with visual perception abilities.
PixArt-$α$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Oct 16, 2023



The most advanced text-to-image (T2I) models require significant training costs (e.g., millions of GPU hours), seriously hindering the fundamental innovation for the AIGC community while increasing CO2 emissions. This paper introduces PIXART-$\alpha$, a Transformer-based T2I diffusion model whose image generation quality is competitive with state-of-the-art image generators (e.g., Imagen, SDXL, and even Midjourney), reaching near-commercial application standards. Additionally, it supports high-resolution image synthesis up to 1024px resolution with low training cost, as shown in Figure 1 and 2. To achieve this goal, three core designs are proposed: (1) Training strategy decomposition: We devise three distinct training steps that separately optimize pixel dependency, text-image alignment, and image aesthetic quality; (2) Efficient T2I Transformer: We incorporate cross-attention modules into Diffusion Transformer (DiT) to inject text conditions and streamline the computation-intensive class-condition branch; (3) High-informative data: We emphasize the significance of concept density in text-image pairs and leverage a large Vision-Language model to auto-label dense pseudo-captions to assist text-image alignment learning. As a result, PIXART-$\alpha$'s training speed markedly surpasses existing large-scale T2I models, e.g., PIXART-$\alpha$ only takes 10.8% of Stable Diffusion v1.5's training time (675 vs. 6,250 A100 GPU days), saving nearly \$300,000 (\$26,000 vs. \$320,000) and reducing 90% CO2 emissions. Moreover, compared with a larger SOTA model, RAPHAEL, our training cost is merely 1%. Extensive experiments demonstrate that PIXART-$\alpha$ excels in image quality, artistry, and semantic control. We hope PIXART-$\alpha$ will provide new insights to the AIGC community and startups to accelerate building their own high-quality yet low-cost generative models from scratch.
DiT-3D: Exploring Plain Diffusion Transformers for 3D Shape Generation
Jul 04, 2023
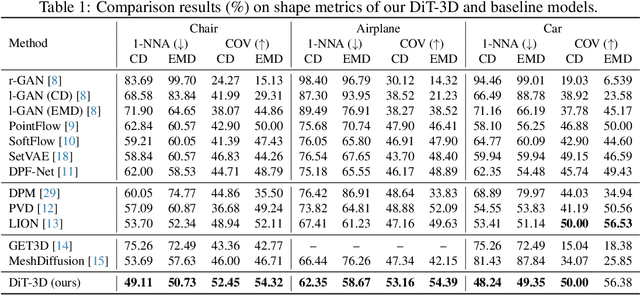
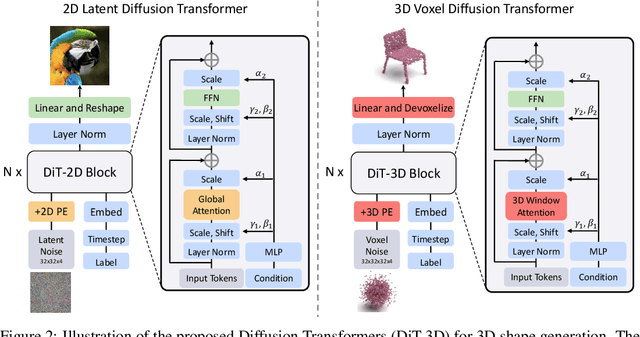
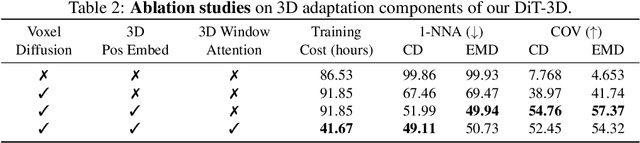
Recent Diffusion Transformers (e.g., DiT) have demonstrated their powerful effectiveness in generating high-quality 2D images. However, it is still being determined whether the Transformer architecture performs equally well in 3D shape generation, as previous 3D diffusion methods mostly adopted the U-Net architecture. To bridge this gap, we propose a novel Diffusion Transformer for 3D shape generation, namely DiT-3D, which can directly operate the denoising process on voxelized point clouds using plain Transformers. Compared to existing U-Net approaches, our DiT-3D is more scalable in model size and produces much higher quality generations. Specifically, the DiT-3D adopts the design philosophy of DiT but modifies it by incorporating 3D positional and patch embeddings to adaptively aggregate input from voxelized point clouds. To reduce the computational cost of self-attention in 3D shape generation, we incorporate 3D window attention into Transformer blocks, as the increased 3D token length resulting from the additional dimension of voxels can lead to high computation. Finally, linear and devoxelization layers are used to predict the denoised point clouds. In addition, our transformer architecture supports efficient fine-tuning from 2D to 3D, where the pre-trained DiT-2D checkpoint on ImageNet can significantly improve DiT-3D on ShapeNet. Experimental results on the ShapeNet dataset demonstrate that the proposed DiT-3D achieves state-of-the-art performance in high-fidelity and diverse 3D point cloud generation. In particular, our DiT-3D decreases the 1-Nearest Neighbor Accuracy of the state-of-the-art method by 4.59 and increases the Coverage metric by 3.51 when evaluated on Chamfer Distance.
DetGPT: Detect What You Need via Reasoning
May 24, 2023



In recent years, the field of computer vision has seen significant advancements thanks to the development of large language models (LLMs). These models have enabled more effective and sophisticated interactions between humans and machines, paving the way for novel techniques that blur the lines between human and machine intelligence. In this paper, we introduce a new paradigm for object detection that we call reasoning-based object detection. Unlike conventional object detection methods that rely on specific object names, our approach enables users to interact with the system using natural language instructions, allowing for a higher level of interactivity. Our proposed method, called DetGPT, leverages state-of-the-art multi-modal models and open-vocabulary object detectors to perform reasoning within the context of the user's instructions and the visual scene. This enables DetGPT to automatically locate the object of interest based on the user's expressed desires, even if the object is not explicitly mentioned. For instance, if a user expresses a desire for a cold beverage, DetGPT can analyze the image, identify a fridge, and use its knowledge of typical fridge contents to locate the beverage. This flexibility makes our system applicable across a wide range of fields, from robotics and automation to autonomous driving. Overall, our proposed paradigm and DetGPT demonstrate the potential for more sophisticated and intuitive interactions between humans and machines. We hope that our proposed paradigm and approach will provide inspiration to the community and open the door to more interative and versatile object detection systems. Our project page is launched at detgpt.github.io.
DiffFit: Unlocking Transferability of Large Diffusion Models via Simple Parameter-Efficient Fine-Tuning
May 04, 2023



Diffusion models have proven to be highly effective in generating high-quality images. However, adapting large pre-trained diffusion models to new domains remains an open challenge, which is critical for real-world applications. This paper proposes DiffFit, a parameter-efficient strategy to fine-tune large pre-trained diffusion models that enable fast adaptation to new domains. DiffFit is embarrassingly simple that only fine-tunes the bias term and newly-added scaling factors in specific layers, yet resulting in significant training speed-up and reduced model storage costs. Compared with full fine-tuning, DiffFit achieves 2$\times$ training speed-up and only needs to store approximately 0.12\% of the total model parameters. Intuitive theoretical analysis has been provided to justify the efficacy of scaling factors on fast adaptation. On 8 downstream datasets, DiffFit achieves superior or competitive performances compared to the full fine-tuning while being more efficient. Remarkably, we show that DiffFit can adapt a pre-trained low-resolution generative model to a high-resolution one by adding minimal cost. Among diffusion-based methods, DiffFit sets a new state-of-the-art FID of 3.02 on ImageNet 512$\times$512 benchmark by fine-tuning only 25 epochs from a public pre-trained ImageNet 256$\times$256 checkpoint while being 30$\times$ more training efficient than the closest competitor.