 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLARE: Diffusion for Hybrid Language Model
Jun 01, 2026Autoregressive (AR) large language models (LLMs) have achieved broad practical success, but sequential decoding remains a key bottleneck for low-latency deployment. Recent efficient-inference work has progressed along two axes: reducing the cost of each model invocation through efficient architectures, and reducing serial decoding steps through parallel generation. Hybrid attention backbones address the former, while diffusion language models (dLLMs) pursue the latter via iterative parallel denoising. Combining these advantages remains challenging: AR-to-dLLM conversion often fails to preserve seed-checkpoint capability, and hybrid-attention recurrent states and masking constraints make diffusion training and serving nontrivial. We present FLARE, a systematic conversion framework for hybrid-attention LLMs. Our analysis identifies transfer data quality as the primary determinant of capability preservation, outweighing loss formulation and attention-mask design. The resulting framework combines a token-equal AR-and-diffusion objective, hardware-aware kernels, and unified inference, enabling one checkpoint to support both AR-style verified decoding and diffusion-style parallel denoising. Starting from strong AR checkpoints with limited post-training data, FLARE is competitive with leading open-source dLLMs across model scales and delivers consistent throughput gains over open-source dLLM baselines in single-GPU concurrent serving. Our results further suggest that practical dLLMs are limited not only by decoding algorithms, but also by transfer data quality and the training inefficiency of current block-diffusion objectives, motivating joint design of data, objectives, architectures, and inference systems.
Coarse-to-Real: Generative Rendering for Populated Dynamic Scenes
Jan 29, 2026Traditional rendering pipelines rely on complex assets, accurate materials and lighting, and substantial computational resources to produce realistic imagery, yet they still face challenges in scalability and realism for populated dynamic scenes. We present C2R (Coarse-to-Real), a generative rendering framework that synthesizes real-style urban crowd videos from coarse 3D simulations. Our approach uses coarse 3D renderings to explicitly control scene layout, camera motion, and human trajectories, while a learned neural renderer generates realistic appearance, lighting, and fine-scale dynamics guided by text prompts. To overcome the lack of paired training data between coarse simulations and real videos, we adopt a two-phase mixed CG-real training strategy that learns a strong generative prior from large-scale real footage and introduces controllability through shared implicit spatio-temporal features across domains. The resulting system supports coarse-to-fine control, generalizes across diverse CG and game inputs, and produces temporally consistent, controllable, and realistic urban scene videos from minimal 3D input. We will release the model and project webpage at https://gonzalognogales.github.io/coarse2real/.
Both Semantics and Reconstruction Matter: Making Representation Encoders Ready for Text-to-Image Generation and Editing
Dec 19, 2025Modern Latent Diffusion Models (LDMs) typically operate in low-level Variational Autoencoder (VAE) latent spaces that are primarily optimized for pixel-level reconstruction. To unify vision generation and understanding, a burgeoning trend is to adopt high-dimensional features from representation encoders as generative latents. However, we empirically identify two fundamental obstacles in this paradigm: (1) the discriminative feature space lacks compact regularization, making diffusion models prone to off-manifold latents that lead to inaccurate object structures; and (2) the encoder's inherently weak pixel-level reconstruction hinders the generator from learning accurate fine-grained geometry and texture. In this paper, we propose a systematic framework to adapt understanding-oriented encoder features for generative tasks. We introduce a semantic-pixel reconstruction objective to regularize the latent space, enabling the compression of both semantic information and fine-grained details into a highly compact representation (96 channels with 16x16 spatial downsampling). This design ensures that the latent space remains semantically rich and achieves state-of-the-art image reconstruction, while remaining compact enough for accurate generation. Leveraging this representation, we design a unified Text-to-Image (T2I) and image editing model. Benchmarking against various feature spaces, we demonstrate that our approach achieves state-of-the-art reconstruction, faster convergence, and substantial performance gains in both T2I and editing tasks, validating that representation encoders can be effectively adapted into robust generative components.
DiffusionBrowser: Interactive Diffusion Previews via Multi-Branch Decoders
Dec 15, 2025
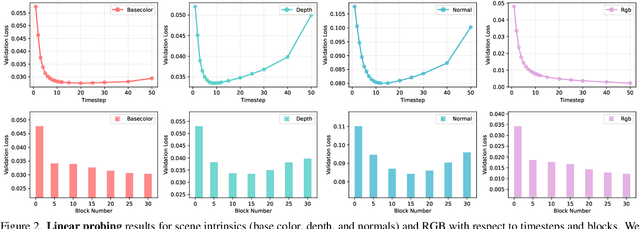


Video diffusion models have revolutionized generative video synthesis, but they are imprecise, slow, and can be opaque during generation -- keeping users in the dark for a prolonged period. In this work, we propose DiffusionBrowser, a model-agnostic, lightweight decoder framework that allows users to interactively generate previews at any point (timestep or transformer block) during the denoising process. Our model can generate multi-modal preview representations that include RGB and scene intrinsics at more than 4$\times$ real-time speed (less than 1 second for a 4-second video) that convey consistent appearance and motion to the final video. With the trained decoder, we show that it is possible to interactively guide the generation at intermediate noise steps via stochasticity reinjection and modal steering, unlocking a new control capability. Moreover, we systematically probe the model using the learned decoders, revealing how scene, object, and other details are composed and assembled during the otherwise black-box denoising process.
CreativeVR: Diffusion-Prior-Guided Approach for Structure and Motion Restoration in Generative and Real Videos
Dec 12, 2025Modern text-to-video (T2V) diffusion models can synthesize visually compelling clips, yet they remain brittle at fine-scale structure: even state-of-the-art generators often produce distorted faces and hands, warped backgrounds, and temporally inconsistent motion. Such severe structural artifacts also appear in very low-quality real-world videos. Classical video restoration and super-resolution (VR/VSR) methods, in contrast, are tuned for synthetic degradations such as blur and downsampling and tend to stabilize these artifacts rather than repair them, while diffusion-prior restorers are usually trained on photometric noise and offer little control over the trade-off between perceptual quality and fidelity. We introduce CreativeVR, a diffusion-prior-guided video restoration framework for AI-generated (AIGC) and real videos with severe structural and temporal artifacts. Our deep-adapter-based method exposes a single precision knob that controls how strongly the model follows the input, smoothly trading off between precise restoration on standard degradations and stronger structure- and motion-corrective behavior on challenging content. Our key novelty is a temporally coherent degradation module used during training, which applies carefully designed transformations that produce realistic structural failures. To evaluate AIGC-artifact restoration, we propose the AIGC54 benchmark with FIQA, semantic and perceptual metrics, and multi-aspect scoring. CreativeVR achieves state-of-the-art results on videos with severe artifacts and performs competitively on standard video restoration benchmarks, while running at practical throughput (about 13 FPS at 720p on a single 80-GB A100). Project page: https://daveishan.github.io/creativevr-webpage/.
Character Mixing for Video Generation
Oct 06, 2025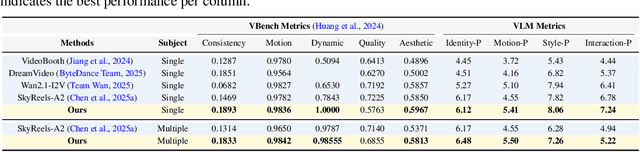


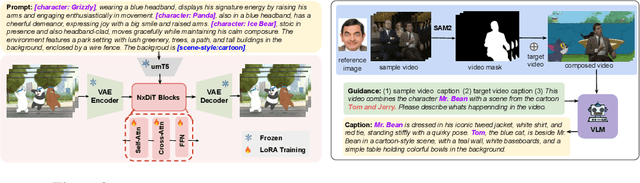
Imagine Mr. Bean stepping into Tom and Jerry--can we generate videos where characters interact naturally across different worlds? We study inter-character interaction in text-to-video generation, where the key challenge is to preserve each character's identity and behaviors while enabling coherent cross-context interaction. This is difficult because characters may never have coexisted and because mixing styles often causes style delusion, where realistic characters appear cartoonish or vice versa. We introduce a framework that tackles these issues with Cross-Character Embedding (CCE), which learns identity and behavioral logic across multimodal sources, and Cross-Character Augmentation (CCA), which enriches training with synthetic co-existence and mixed-style data. Together, these techniques allow natural interactions between previously uncoexistent characters without losing stylistic fidelity. Experiments on a curated benchmark of cartoons and live-action series with 10 characters show clear improvements in identity preservation, interaction quality, and robustness to style delusion, enabling new forms of generative storytelling.Additional results and videos are available on our project page: https://tingtingliao.github.io/mimix/.
A Generative Foundation Model for Chest Radiography
Sep 04, 2025The scarcity of well-annotated diverse medical images is a major hurdle for developing reliable AI models in healthcare. Substantial technical advances have been made in generative foundation models for natural images. Here we develop `ChexGen', a generative vision-language foundation model that introduces a unified framework for text-, mask-, and bounding box-guided synthesis of chest radiographs. Built upon the latent diffusion transformer architecture, ChexGen was pretrained on the largest curated chest X-ray dataset to date, consisting of 960,000 radiograph-report pairs. ChexGen achieves accurate synthesis of radiographs through expert evaluations and quantitative metrics. We demonstrate the utility of ChexGen for training data augmentation and supervised pretraining, which led to performance improvements across disease classification, detection, and segmentation tasks using a small fraction of training data. Further, our model enables the creation of diverse patient cohorts that enhance model fairness by detecting and mitigating demographic biases. Our study supports the transformative role of generative foundation models in building more accurate, data-efficient, and equitable medical AI systems.
PixelFlow: Pixel-Space Generative Models with Flow
Apr 10, 2025



We present PixelFlow, a family of image generation models that operate directly in the raw pixel space, in contrast to the predominant latent-space models. This approach simplifies the image generation process by eliminating the need for a pre-trained Variational Autoencoder (VAE) and enabling the whole model end-to-end trainable. Through efficient cascade flow modeling, PixelFlow achieves affordable computation cost in pixel space. It achieves an FID of 1.98 on 256$\times$256 ImageNet class-conditional image generation benchmark. The qualitative text-to-image results demonstrate that PixelFlow excels in image quality, artistry, and semantic control. We hope this new paradigm will inspire and open up new opportunities for next-generation visual generation models. Code and models are available at https://github.com/ShoufaChen/PixelFlow.
Goku: Flow Based Video Generative Foundation Models
Feb 10, 2025



This paper introduces Goku, a state-of-the-art family of joint image-and-video generation models leveraging rectified flow Transformers to achieve industry-leading performance. We detail the foundational elements enabling high-quality visual generation, including the data curation pipeline, model architecture design, flow formulation, and advanced infrastructure for efficient and robust large-scale training. The Goku models demonstrate superior performance in both qualitative and quantitative evaluations, setting new benchmarks across major tasks. Specifically, Goku achieves 0.76 on GenEval and 83.65 on DPG-Bench for text-to-image generation, and 84.85 on VBench for text-to-video tasks. We believe that this work provides valuable insights and practical advancements for the research community in developing joint image-and-video generation models.
FlashVideo:Flowing Fidelity to Detail for Efficient High-Resolution Video Generation
Feb 07, 2025DiT diffusion models have achieved great success in text-to-video generation, leveraging their scalability in model capacity and data scale. High content and motion fidelity aligned with text prompts, however, often require large model parameters and a substantial number of function evaluations (NFEs). Realistic and visually appealing details are typically reflected in high resolution outputs, further amplifying computational demands especially for single stage DiT models. To address these challenges, we propose a novel two stage framework, FlashVideo, which strategically allocates model capacity and NFEs across stages to balance generation fidelity and quality. In the first stage, prompt fidelity is prioritized through a low resolution generation process utilizing large parameters and sufficient NFEs to enhance computational efficiency. The second stage establishes flow matching between low and high resolutions, effectively generating fine details with minimal NFEs. Quantitative and visual results demonstrate that FlashVideo achieves state-of-the-art high resolution video generation with superior computational efficiency. Additionally, the two-stage design enables users to preview the initial output before committing to full resolution generation, thereby significantly reducing computational costs and wait times as well as enhancing commercial viability .