 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUC-NeRF: Uncertainty-aware Conditional Neural Radiance Fields from Endoscopic Sparse Views
Sep 04, 2024Visualizing surgical scenes is crucial for revealing internal anatomical structures during minimally invasive procedures. Novel View Synthesis is a vital technique that offers geometry and appearance reconstruction, enhancing understanding, planning, and decision-making in surgical scenes. Despite the impressive achievements of Neural Radiance Field (NeRF), its direct application to surgical scenes produces unsatisfying results due to two challenges: endoscopic sparse views and significant photometric inconsistencies. In this paper, we propose uncertainty-aware conditional NeRF for novel view synthesis to tackle the severe shape-radiance ambiguity from sparse surgical views. The core of UC-NeRF is to incorporate the multi-view uncertainty estimation to condition the neural radiance field for modeling the severe photometric inconsistencies adaptively. Specifically, our UC-NeRF first builds a consistency learner in the form of multi-view stereo network, to establish the geometric correspondence from sparse views and generate uncertainty estimation and feature priors. In neural rendering, we design a base-adaptive NeRF network to exploit the uncertainty estimation for explicitly handling the photometric inconsistencies. Furthermore, an uncertainty-guided geometry distillation is employed to enhance geometry learning. Experiments on the SCARED and Hamlyn datasets demonstrate our superior performance in rendering appearance and geometry, consistently outperforming the current state-of-the-art approaches. Our code will be released at \url{https://github.com/wrld/UC-NeRF}.
SR-Mamba: Effective Surgical Phase Recognition with State Space Model
Jul 11, 2024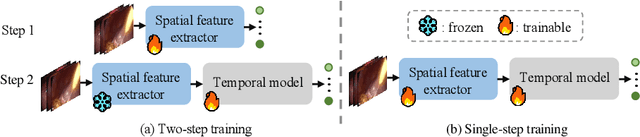
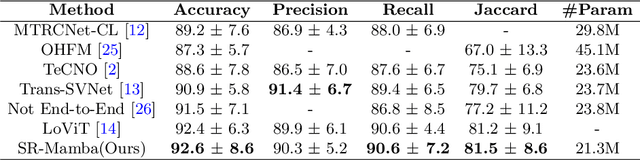


Surgical phase recognition is crucial for enhancing the efficiency and safety of computer-assisted interventions. One of the fundamental challenges involves modeling the long-distance temporal relationships present in surgical videos. Inspired by the recent success of Mamba, a state space model with linear scalability in sequence length, this paper presents SR-Mamba, a novel attention-free model specifically tailored to meet the challenges of surgical phase recognition. In SR-Mamba, we leverage a bidirectional Mamba decoder to effectively model the temporal context in overlong sequences. Moreover, the efficient optimization of the proposed Mamba decoder facilitates single-step neural network training, eliminating the need for separate training steps as in previous works. This single-step training approach not only simplifies the training process but also ensures higher accuracy, even with a lighter spatial feature extractor. Our SR-Mamba establishes a new benchmark in surgical video analysis by demonstrating state-of-the-art performance on the Cholec80 and CATARACTS Challenge datasets. The code is accessible at https://github.com/rcao-hk/SR-Mamba.
Free-SurGS: SfM-Free 3D Gaussian Splatting for Surgical Scene Reconstruction
Jul 03, 2024



Real-time 3D reconstruction of surgical scenes plays a vital role in computer-assisted surgery, holding a promise to enhance surgeons' visibility. Recent advancements in 3D Gaussian Splatting (3DGS) have shown great potential for real-time novel view synthesis of general scenes, which relies on accurate poses and point clouds generated by Structure-from-Motion (SfM) for initialization. However, 3DGS with SfM fails to recover accurate camera poses and geometry in surgical scenes due to the challenges of minimal textures and photometric inconsistencies. To tackle this problem, in this paper, we propose the first SfM-free 3DGS-based method for surgical scene reconstruction by jointly optimizing the camera poses and scene representation. Based on the video continuity, the key of our method is to exploit the immediate optical flow priors to guide the projection flow derived from 3D Gaussians. Unlike most previous methods relying on photometric loss only, we formulate the pose estimation problem as minimizing the flow loss between the projection flow and optical flow. A consistency check is further introduced to filter the flow outliers by detecting the rigid and reliable points that satisfy the epipolar geometry. During 3D Gaussian optimization, we randomly sample frames to optimize the scene representations to grow the 3D Gaussian progressively. Experiments on the SCARED dataset demonstrate our superior performance over existing methods in novel view synthesis and pose estimation with high efficiency. Code is available at https://github.com/wrld/Free-SurGS.
Simultaneous Estimation of Shape and Force along Highly Deformable Surgical Manipulators Using Sparse FBG Measurement
Apr 25, 2024



Recently, fiber optic sensors such as fiber Bragg gratings (FBGs) have been widely investigated for shape reconstruction and force estimation of flexible surgical robots. However, most existing approaches need precise model parameters of FBGs inside the fiber and their alignments with the flexible robots for accurate sensing results. Another challenge lies in online acquiring external forces at arbitrary locations along the flexible robots, which is highly required when with large deflections in robotic surgery. In this paper, we propose a novel data-driven paradigm for simultaneous estimation of shape and force along highly deformable flexible robots by using sparse strain measurement from a single-core FBG fiber. A thin-walled soft sensing tube helically embedded with FBG sensors is designed for a robotic-assisted flexible ureteroscope with large deflection up to 270 degrees and a bend radius under 10 mm. We introduce and study three learning models by incorporating spatial strain encoders, and compare their performances in both free space and constrained environments with contact forces at different locations. The experimental results in terms of dynamic shape-force sensing accuracy demonstrate the effectiveness and superiority of the proposed methods.
Ada-Tracker: Soft Tissue Tracking via Inter-Frame and Adaptive-Template Matching
Mar 11, 2024



Soft tissue tracking is crucial for computer-assisted interventions. Existing approaches mainly rely on extracting discriminative features from the template and videos to recover corresponding matches. However, it is difficult to adopt these techniques in surgical scenes, where tissues are changing in shape and appearance throughout the surgery. To address this problem, we exploit optical flow to naturally capture the pixel-wise tissue deformations and adaptively correct the tracked template. Specifically, we first implement an inter-frame matching mechanism to extract a coarse region of interest based on optical flow from consecutive frames. To accommodate appearance change and alleviate drift, we then propose an adaptive-template matching method, which updates the tracked template based on the reliability of the estimates. Our approach, Ada-Tracker, enjoys both short-term dynamics modeling by capturing local deformations and long-term dynamics modeling by introducing global temporal compensation. We evaluate our approach on the public SurgT benchmark, which is generated from Hamlyn, SCARED, and Kidney boundary datasets. The experimental results show that Ada-Tracker achieves superior accuracy and performs more robustly against prior works. Code is available at https://github.com/wrld/Ada-Tracker.
Advancing Vision Transformers with Group-Mix Attention
Nov 26, 2023



Vision Transformers (ViTs) have been shown to enhance visual recognition through modeling long-range dependencies with multi-head self-attention (MHSA), which is typically formulated as Query-Key-Value computation. However, the attention map generated from the Query and Key captures only token-to-token correlations at one single granularity. In this paper, we argue that self-attention should have a more comprehensive mechanism to capture correlations among tokens and groups (i.e., multiple adjacent tokens) for higher representational capacity. Thereby, we propose Group-Mix Attention (GMA) as an advanced replacement for traditional self-attention, which can simultaneously capture token-to-token, token-to-group, and group-to-group correlations with various group sizes. To this end, GMA splits the Query, Key, and Value into segments uniformly and performs different group aggregations to generate group proxies. The attention map is computed based on the mixtures of tokens and group proxies and used to re-combine the tokens and groups in Value. Based on GMA, we introduce a powerful backbone, namely GroupMixFormer, which achieves state-of-the-art performance in image classification, object detection, and semantic segmentation with fewer parameters than existing models. For instance, GroupMixFormer-L (with 70.3M parameters and 384^2 input) attains 86.2% Top-1 accuracy on ImageNet-1K without external data, while GroupMixFormer-B (with 45.8M parameters) attains 51.2% mIoU on ADE20K.
Speed Co-Augmentation for Unsupervised Audio-Visual Pre-training
Sep 25, 2023This work aims to improve unsupervised audio-visual pre-training. Inspired by the efficacy of data augmentation in visual contrastive learning, we propose a novel speed co-augmentation method that randomly changes the playback speeds of both audio and video data. Despite its simplicity, the speed co-augmentation method possesses two compelling attributes: (1) it increases the diversity of audio-visual pairs and doubles the size of negative pairs, resulting in a significant enhancement in the learned representations, and (2) it changes the strict correlation between audio-visual pairs but introduces a partial relationship between the augmented pairs, which is modeled by our proposed SoftInfoNCE loss to further boost the performance. Experimental results show that the proposed method significantly improves the learned representations when compared to vanilla audio-visual contrastive learning.
Soft Neighbors are Positive Supporters in Contrastive Visual Representation Learning
Mar 30, 2023Contrastive learning methods train visual encoders by comparing views from one instance to others. Typically, the views created from one instance are set as positive, while views from other instances are negative. This binary instance discrimination is studied extensively to improve feature representations in self-supervised learning. In this paper, we rethink the instance discrimination framework and find the binary instance labeling insufficient to measure correlations between different samples. For an intuitive example, given a random image instance, there may exist other images in a mini-batch whose content meanings are the same (i.e., belonging to the same category) or partially related (i.e., belonging to a similar category). How to treat the images that correlate similarly to the current image instance leaves an unexplored problem. We thus propose to support the current image by exploring other correlated instances (i.e., soft neighbors). We first carefully cultivate a candidate neighbor set, which will be further utilized to explore the highly-correlated instances. A cross-attention module is then introduced to predict the correlation score (denoted as positiveness) of other correlated instances with respect to the current one. The positiveness score quantitatively measures the positive support from each correlated instance, and is encoded into the objective for pretext training. To this end, our proposed method benefits in discriminating uncorrelated instances while absorbing correlated instances for SSL. We evaluate our soft neighbor contrastive learning method (SNCLR) on standard visual recognition benchmarks, including image classification, object detection, and instance segmentation. The state-of-the-art recognition performance shows that SNCLR is effective in improving feature representations from both ViT and CNN encoders.
AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition
May 26, 2022

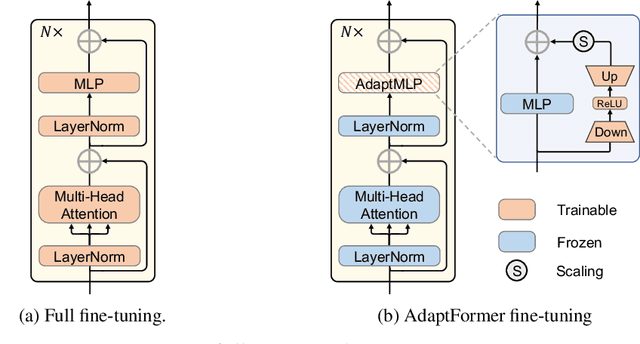

Although the pre-trained Vision Transformers (ViTs) achieved great success in computer vision, adapting a ViT to various image and video tasks is challenging because of its heavy computation and storage burdens, where each model needs to be independently and comprehensively fine-tuned to different tasks, limiting its transferability in different domains. To address this challenge, we propose an effective adaptation approach for Transformer, namely AdaptFormer, which can adapt the pre-trained ViTs into many different image and video tasks efficiently. It possesses several benefits more appealing than prior arts. Firstly, AdaptFormer introduces lightweight modules that only add less than 2% extra parameters to a ViT, while it is able to increase the ViT's transferability without updating its original pre-trained parameters, significantly outperforming the existing 100% fully fine-tuned models on action recognition benchmarks. Secondly, it can be plug-and-play in different Transformers and scalable to many visual tasks. Thirdly, extensive experiments on five image and video datasets show that AdaptFormer largely improves ViTs in the target domains. For example, when updating just 1.5% extra parameters, it achieves about 10% and 19% relative improvement compared to the fully fine-tuned models on Something-Something~v2 and HMDB51, respectively. Project page: http://www.shoufachen.com/adaptformer-page.
A Multi-Sensor Interface to Improve the Teaching and Learning Experience in Arc Welding Training Tasks
Sep 10, 2021

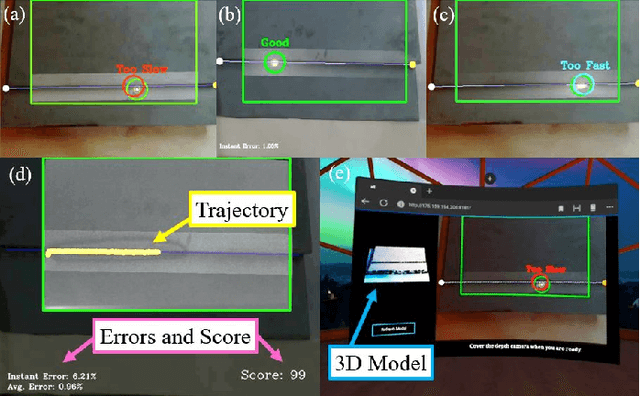

This paper presents the development of a multi-sensor extended reality platform to improve the teaching and learning experience of arc welding tasks. Traditional methods to acquire hand-eye welding coordination skills are typically conducted through one-to-one instruction where trainees/trainers must wear protective helmets and conduct several hands-on tests with metal workpieces. This approach is inefficient as the harmful light emitted from the electric arc impedes the close monitoring of the welding process (practitioners can only observe a small bright spot and most geometric information cannot be perceived). To tackle these problems, some recent training approaches have leveraged on virtual reality (VR) as a way to safely simulate the process and visualize the geometry of the workpieces. However, the synthetic nature of the virtual simulation reduces the effectiveness of the platform; It fails to comprise actual interactions with the welding environment, which may hinder the learning process of a trainee. To incorporate a real welding experience, in this work we present a new automated multi-sensor extended reality platform for arc welding training. It consists of three components: (1) An HDR camera, monitoring the real welding spot in real-time; (2) A depth sensor, capturing the 3D geometry of the scene; and (3) A head-mounted VR display, visualizing the process safely. Our innovative platform provides trainees with a "bot trainer", virtual cues of the seam geometry, automatic spot tracking, and a performance score. To validate the platform's feasibility, we conduct extensive experiments with several welding training tasks. We show that compared with the traditional training practice and recent virtual reality approaches, our automated method achieves better performances in terms of accuracy, learning curve, and effectiveness.