 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnpaired Cross-Domain Calibration of DMSP to VIIRS Nighttime Light Data Based on CUT Network
Mar 17, 2026Defense Meteorological Satellite Program (DMSP-OLS) and Suomi National Polar-orbiting Partnership (SNPP-VIIRS) nighttime light (NTL) data are vital for monitoring urbanization, yet sensor incompatibilities hinder long-term analysis. This study proposes a cross-sensor calibration method using Contrastive Unpaired Translation (CUT) network to transform DMSP data into VIIRS-like format, correcting DMSP defects. The method employs multilayer patch-wise contrastive learning to maximize mutual information between corresponding patches, preserving content consistency while learning cross-domain similarity. Utilizing 2012-2013 overlapping data for training, the network processes 1992-2013 DMSP imagery to generate enhanced VIIRS-style raster data. Validation results demonstrate that generated VIIRS-like data exhibits high consistency with actual VIIRS observations (R-squared greater than 0.87) and socioeconomic indicators. This approach effectively resolves cross-sensor data fusion issues and calibrates DMSP defects, providing reliable attempt for extended NTL time-series.
Contextual AD Narration with Interleaved Multimodal Sequence
Mar 19, 2024The Audio Description (AD) task aims to generate descriptions of visual elements for visually impaired individuals to help them access long-form video contents, like movie. With video feature, text, character bank and context information as inputs, the generated ADs are able to correspond to the characters by name and provide reasonable, contextual descriptions to help audience understand the storyline of movie. To achieve this goal, we propose to leverage pre-trained foundation models through a simple and unified framework to generate ADs with interleaved multimodal sequence as input, termed as Uni-AD. To enhance the alignment of features across various modalities with finer granularity, we introduce a simple and lightweight module that maps video features into the textual feature space. Moreover, we also propose a character-refinement module to provide more precise information by identifying the main characters who play more significant role in the video context. With these unique designs, we further incorporate contextual information and a contrastive loss into our architecture to generate more smooth and contextual ADs. Experiments on the MAD-eval dataset show that Uni-AD can achieve state-of-the-art performance on AD generation, which demonstrates the effectiveness of our approach. Code will be available at https://github.com/MCG-NJU/Uni-AD.
TagAlign: Improving Vision-Language Alignment with Multi-Tag Classification
Dec 26, 2023
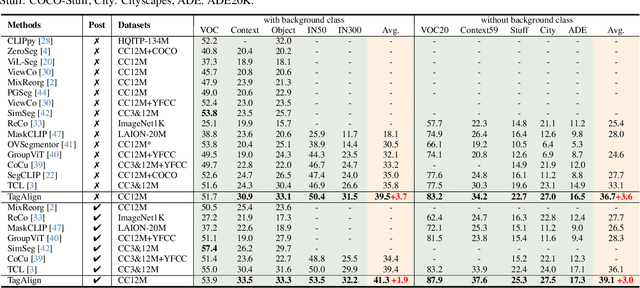
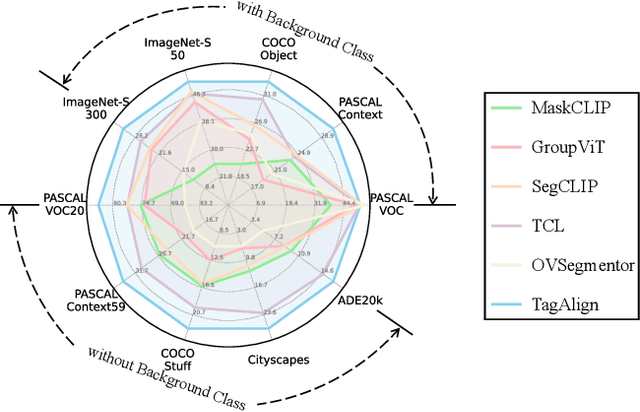
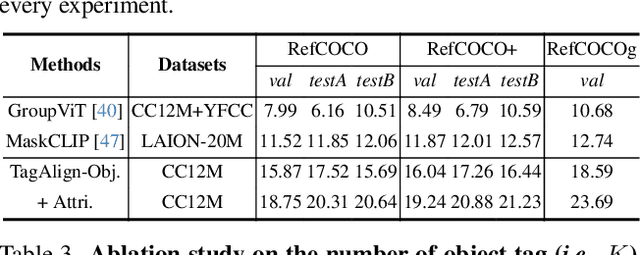
The crux of learning vision-language models is to extract semantically aligned information from visual and linguistic data. Existing attempts usually face the problem of coarse alignment, e.g., the vision encoder struggles in localizing an attribute-specified object. In this work, we propose an embarrassingly simple approach to better align image and text features with no need of additional data formats other than image-text pairs. Concretely, given an image and its paired text, we manage to parse objects (e.g., cat) and attributes (e.g., black) from the description, which are highly likely to exist in the image. It is noteworthy that the parsing pipeline is fully automatic and thus enjoys good scalability. With these parsed semantics as supervision signals, we can complement the commonly used image-text contrastive loss with the multi-tag classification loss. Extensive experimental results on a broad suite of semantic segmentation datasets substantiate the average 3.65\% improvement of our framework over existing alternatives. Furthermore, the visualization results indicate that attribute supervision makes vision-language models accurately localize attribute-specified objects. Project page and code can be found at https://qinying-liu.github.io/Tag-Align.
Bootstrapping SparseFormers from Vision Foundation Models
Dec 04, 2023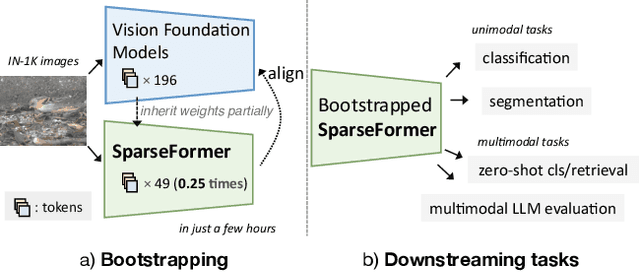
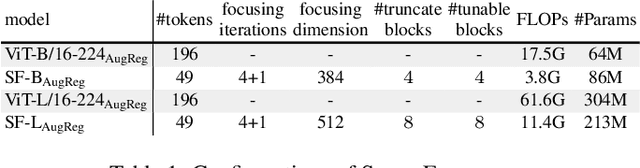
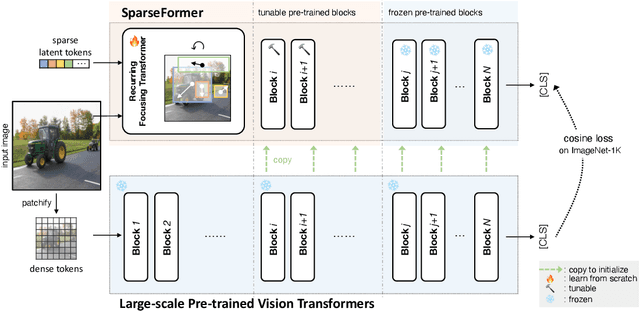
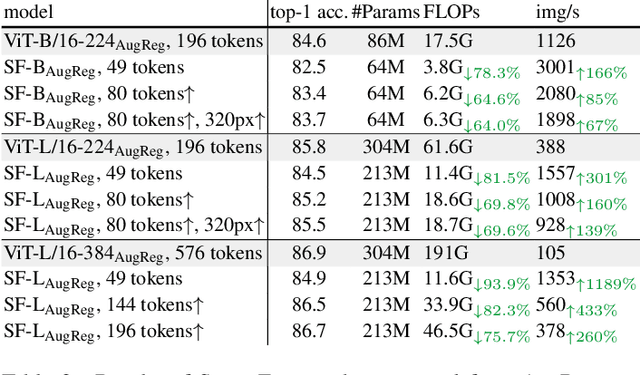
The recently proposed SparseFormer architecture provides an alternative approach to visual understanding by utilizing a significantly lower number of visual tokens via adjusting RoIs, greatly reducing computational costs while still achieving promising performance. However, training SparseFormers from scratch is still expensive, and scaling up the number of parameters can be challenging. In this paper, we propose to bootstrap SparseFormers from ViT-based vision foundation models in a simple and efficient way. Since the majority of SparseFormer blocks are the standard transformer ones, we can inherit weights from large-scale pre-trained vision transformers and freeze them as much as possible. Therefore, we only need to train the SparseFormer-specific lightweight focusing transformer to adjust token RoIs and fine-tune a few early pre-trained blocks to align the final token representation. In such a way, we can bootstrap SparseFormer architectures from various large-scale pre-trained models (e.g., IN-21K pre-trained AugRegs or CLIPs) using a rather smaller amount of training samples (e.g., IN-1K) and without labels or captions within just a few hours. As a result, the bootstrapped unimodal SparseFormer (from AugReg-ViT-L/16-384) can reach 84.9% accuracy on IN-1K with only 49 tokens, and the multimodal SparseFormer from CLIPs also demonstrates notable zero-shot performance with highly reduced computational cost without seeing any caption during the bootstrapping procedure. In addition, CLIP-bootstrapped SparseFormers, which align the output space with language without seeing a word, can serve as efficient vision encoders in multimodal large language models. Code will be publicly available at https://github.com/showlab/sparseformer
Advancing Vision Transformers with Group-Mix Attention
Nov 26, 2023



Vision Transformers (ViTs) have been shown to enhance visual recognition through modeling long-range dependencies with multi-head self-attention (MHSA), which is typically formulated as Query-Key-Value computation. However, the attention map generated from the Query and Key captures only token-to-token correlations at one single granularity. In this paper, we argue that self-attention should have a more comprehensive mechanism to capture correlations among tokens and groups (i.e., multiple adjacent tokens) for higher representational capacity. Thereby, we propose Group-Mix Attention (GMA) as an advanced replacement for traditional self-attention, which can simultaneously capture token-to-token, token-to-group, and group-to-group correlations with various group sizes. To this end, GMA splits the Query, Key, and Value into segments uniformly and performs different group aggregations to generate group proxies. The attention map is computed based on the mixtures of tokens and group proxies and used to re-combine the tokens and groups in Value. Based on GMA, we introduce a powerful backbone, namely GroupMixFormer, which achieves state-of-the-art performance in image classification, object detection, and semantic segmentation with fewer parameters than existing models. For instance, GroupMixFormer-L (with 70.3M parameters and 384^2 input) attains 86.2% Top-1 accuracy on ImageNet-1K without external data, while GroupMixFormer-B (with 45.8M parameters) attains 51.2% mIoU on ADE20K.
Speed Co-Augmentation for Unsupervised Audio-Visual Pre-training
Sep 25, 2023This work aims to improve unsupervised audio-visual pre-training. Inspired by the efficacy of data augmentation in visual contrastive learning, we propose a novel speed co-augmentation method that randomly changes the playback speeds of both audio and video data. Despite its simplicity, the speed co-augmentation method possesses two compelling attributes: (1) it increases the diversity of audio-visual pairs and doubles the size of negative pairs, resulting in a significant enhancement in the learned representations, and (2) it changes the strict correlation between audio-visual pairs but introduces a partial relationship between the augmented pairs, which is modeled by our proposed SoftInfoNCE loss to further boost the performance. Experimental results show that the proposed method significantly improves the learned representations when compared to vanilla audio-visual contrastive learning.
TVTSv2: Learning Out-of-the-box Spatiotemporal Visual Representations at Scale
May 23, 2023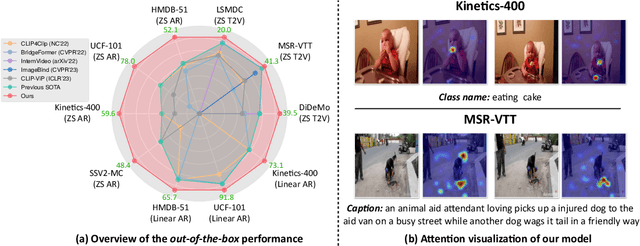
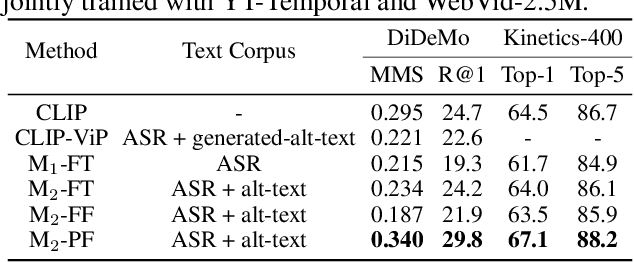
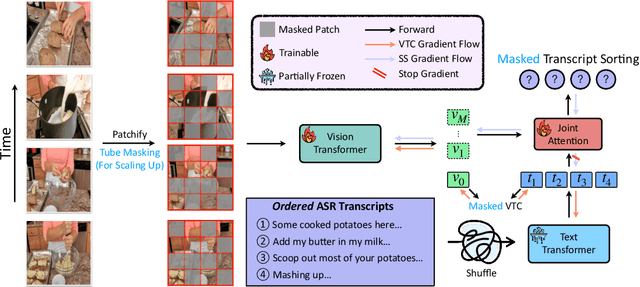
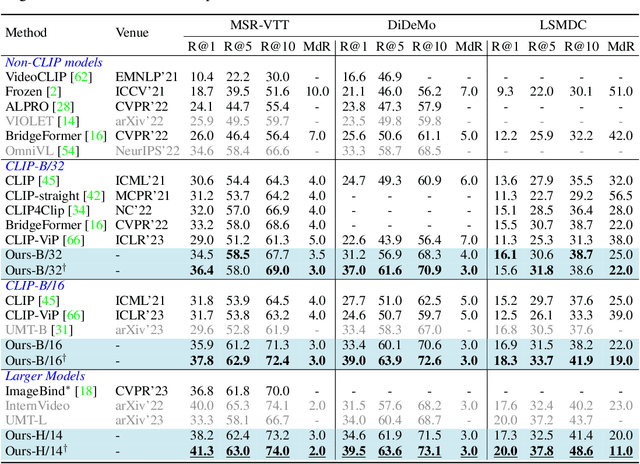
The ultimate goal for foundation models is realizing task-agnostic, i.e., supporting out-of-the-box usage without task-specific fine-tuning. Although breakthroughs have been made in natural language processing and image representation learning, it is still challenging for video models to reach it due to the increasing uncertainty of spatiotemporal signals. To ease training, existing works leverage image foundation models' prior knowledge and equip them with efficient temporal modules. Despite the satisfactory fine-tuning performance, we empirically find they fall short of out-of-the-box usage, given the even degraded performance in zero-shot/linear protocols compared to their baseline counterparts. In this work, we analyze the factor that leads to degradation from the perspective of language supervision distortion. We argue that tuning a text encoder end-to-end, as done in previous work, is suboptimal since it may overfit in terms of styles, thereby losing its original generalization ability to capture the semantics of various language registers. The overfitted text encoder, in turn, provides a harmful supervision signal, degrading the video representation. To tackle this issue, we propose a degradation-free pre-training strategy to retain the generalization ability of the text encoder via freezing shallow layers while enabling the task-related semantics capturing in tunable deep layers. As for the training objective, we adopted the transcript sorting task in TVTS incorporated with masking techniques to enable scalable training. As a result, we produce a series of models, dubbed TVTSv2, with up to one billion parameters. We achieve new state-of-the-arts on various video benchmarks with a frozen backbone, surpassing the recent ImageBind, InternVideo, etc. Code is available at https://github.com/TencentARC/TVTS.
VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking
Apr 18, 2023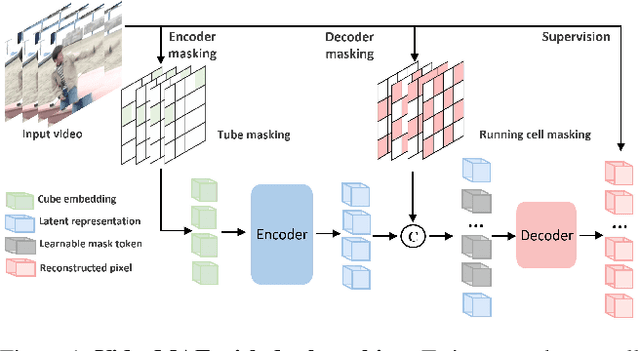



Scale is the primary factor for building a powerful foundation model that could well generalize to a variety of downstream tasks. However, it is still challenging to train video foundation models with billions of parameters. This paper shows that video masked autoencoder (VideoMAE) is a scalable and general self-supervised pre-trainer for building video foundation models. We scale the VideoMAE in both model and data with a core design. Specifically, we present a dual masking strategy for efficient pre-training, with an encoder operating on a subset of video tokens and a decoder processing another subset of video tokens. Although VideoMAE is very efficient due to high masking ratio in encoder, masking decoder can still further reduce the overall computational cost. This enables the efficient pre-training of billion-level models in video. We also use a progressive training paradigm that involves an initial pre-training on a diverse multi-sourced unlabeled dataset, followed by a post-pre-training on a mixed labeled dataset. Finally, we successfully train a video ViT model with a billion parameters, which achieves a new state-of-the-art performance on the datasets of Kinetics (90.0% on K400 and 89.9% on K600) and Something-Something (68.7% on V1 and 77.0% on V2). In addition, we extensively verify the pre-trained video ViT models on a variety of downstream tasks, demonstrating its effectiveness as a general video representation learner. The code and model is available at \url{https://github.com/OpenGVLab/VideoMAEv2}.
Efficient Video Action Detection with Token Dropout and Context Refinement
Apr 17, 2023
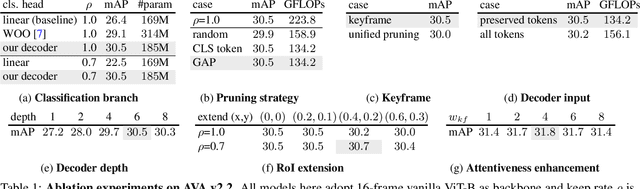
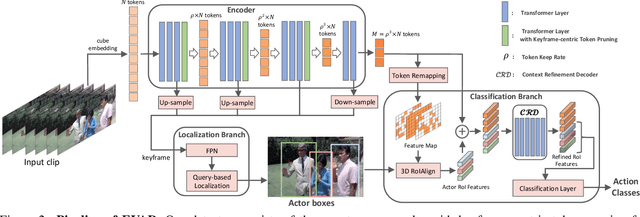
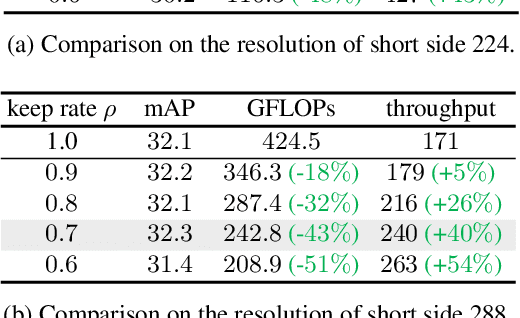
Streaming video clips with large-scale video tokens impede vision transformers (ViTs) for efficient recognition, especially in video action detection where sufficient spatiotemporal representations are required for precise actor identification. In this work, we propose an end-to-end framework for efficient video action detection (EVAD) based on vanilla ViTs. Our EVAD consists of two specialized designs for video action detection. First, we propose a spatiotemporal token dropout from a keyframe-centric perspective. In a video clip, we maintain all tokens from its keyframe, preserve tokens relevant to actor motions from other frames, and drop out the remaining tokens in this clip. Second, we refine scene context by leveraging remaining tokens for better recognizing actor identities. The region of interest (RoI) in our action detector is expanded into temporal domain. The captured spatiotemporal actor identity representations are refined via scene context in a decoder with the attention mechanism. These two designs make our EVAD efficient while maintaining accuracy, which is validated on three benchmark datasets (i.e., AVA, UCF101-24, JHMDB). Compared to the vanilla ViT backbone, our EVAD reduces the overall GFLOPs by 43% and improves real-time inference speed by 40% with no performance degradation. Moreover, even at similar computational costs, our EVAD can improve the performance by 1.0 mAP with higher resolution inputs. Code is available at https://github.com/MCG-NJU/EVAD.
SparseFormer: Sparse Visual Recognition via Limited Latent Tokens
Apr 07, 2023



Human visual recognition is a sparse process, where only a few salient visual cues are attended to rather than traversing every detail uniformly. However, most current vision networks follow a dense paradigm, processing every single visual unit (e.g,, pixel or patch) in a uniform manner. In this paper, we challenge this dense paradigm and present a new method, coined SparseFormer, to imitate human's sparse visual recognition in an end-to-end manner. SparseFormer learns to represent images using a highly limited number of tokens (down to 49) in the latent space with sparse feature sampling procedure instead of processing dense units in the original pixel space. Therefore, SparseFormer circumvents most of dense operations on the image space and has much lower computational costs. Experiments on the ImageNet classification benchmark dataset show that SparseFormer achieves performance on par with canonical or well-established models while offering better accuracy-throughput tradeoff. Moreover, the design of our network can be easily extended to the video classification with promising performance at lower computational costs. We hope that our work can provide an alternative way for visual modeling and inspire further research on sparse neural architectures. The code will be publicly available at https://github.com/showlab/sparseformer