 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoley-Flow: Coordinated Video-to-Audio Generation with Masked Audio-Visual Alignment and Dynamic Conditional Flows
Mar 09, 2026Coordinated audio generation based on video inputs typically requires a strict audio-visual (AV) alignment, where both semantics and rhythmics of the generated audio segments shall correspond to those in the video frames. Previous studies leverage a two-stage design where the AV encoders are firstly aligned via contrastive learning, then the encoded video representations guide the audio generation process. We observe that both contrastive learning and global video guidance are effective in aligning overall AV semantics while limiting temporally rhythmic synchronization. In this work, we propose FoleyFlow to first align unimodal AV encoders via masked modeling training, where the masked audio segments are recovered under the guidance of the corresponding video segments. After training, the AV encoders which are separately pretrained using only unimodal data are aligned with semantic and rhythmic consistency. Then, we develop a dynamic conditional flow for the final audio generation. Built upon the efficient velocity flow generation framework, our dynamic conditional flow utilizes temporally varying video features as the dynamic condition to guide corresponding audio segment generations. To this end, we extract coherent semantic and rhythmic representations during masked AV alignment, and use this representation of video segments to guide audio generation temporally. Our audio results are evaluated on the standard benchmarks and largely surpass existing results under several metrics. The superior performance indicates that FoleyFlow is effective in generating coordinated audios that are both semantically and rhythmically coherent to various video sequences.
WorldVLA: Towards Autoregressive Action World Model
Jun 26, 2025We present WorldVLA, an autoregressive action world model that unifies action and image understanding and generation. Our WorldVLA intergrates Vision-Language-Action (VLA) model and world model in one single framework. The world model predicts future images by leveraging both action and image understanding, with the purpose of learning the underlying physics of the environment to improve action generation. Meanwhile, the action model generates the subsequent actions based on image observations, aiding in visual understanding and in turn helps visual generation of the world model. We demonstrate that WorldVLA outperforms standalone action and world models, highlighting the mutual enhancement between the world model and the action model. In addition, we find that the performance of the action model deteriorates when generating sequences of actions in an autoregressive manner. This phenomenon can be attributed to the model's limited generalization capability for action prediction, leading to the propagation of errors from earlier actions to subsequent ones. To address this issue, we propose an attention mask strategy that selectively masks prior actions during the generation of the current action, which shows significant performance improvement in the action chunk generation task.
AsFT: Anchoring Safety During LLM Fine-Tuning Within Narrow Safety Basin
Jun 11, 2025



Large language models (LLMs) are vulnerable to safety risks during fine-tuning, where small amounts of malicious or harmless data can compromise safeguards. In this paper, building on the concept of alignment direction -- defined by the weight difference between aligned and unaligned models -- we observe that perturbations along this direction preserve model safety. In contrast, perturbations along directions orthogonal to this alignment are strongly linked to harmful direction perturbations, rapidly degrading safety and framing the parameter space as a narrow safety basin. Based on this insight, we propose a methodology for safety fine-tuning called AsFT (Anchoring Safety in Fine-Tuning), which integrates a regularization term into the training objective. This term uses the alignment direction as an anchor to suppress updates in harmful directions, ensuring that fine-tuning is constrained within the narrow safety basin. Extensive experiments on multiple datasets show that AsFT outperforms Safe LoRA, reducing harmful behavior by 7.60 percent, improving model performance by 3.44 percent, and maintaining robust performance across various experimental settings. Code is available at https://github.com/PKU-YuanGroup/AsFT
DyDiT++: Dynamic Diffusion Transformers for Efficient Visual Generation
Apr 09, 2025Diffusion Transformer (DiT), an emerging diffusion model for visual generation, has demonstrated superior performance but suffers from substantial computational costs. Our investigations reveal that these costs primarily stem from the \emph{static} inference paradigm, which inevitably introduces redundant computation in certain \emph{diffusion timesteps} and \emph{spatial regions}. To overcome this inefficiency, we propose \textbf{Dy}namic \textbf{Di}ffusion \textbf{T}ransformer (DyDiT), an architecture that \emph{dynamically} adjusts its computation along both \emph{timestep} and \emph{spatial} dimensions. Specifically, we introduce a \emph{Timestep-wise Dynamic Width} (TDW) approach that adapts model width conditioned on the generation timesteps. In addition, we design a \emph{Spatial-wise Dynamic Token} (SDT) strategy to avoid redundant computation at unnecessary spatial locations. TDW and SDT can be seamlessly integrated into DiT and significantly accelerates the generation process. Building on these designs, we further enhance DyDiT in three key aspects. First, DyDiT is integrated seamlessly with flow matching-based generation, enhancing its versatility. Furthermore, we enhance DyDiT to tackle more complex visual generation tasks, including video generation and text-to-image generation, thereby broadening its real-world applications. Finally, to address the high cost of full fine-tuning and democratize technology access, we investigate the feasibility of training DyDiT in a parameter-efficient manner and introduce timestep-based dynamic LoRA (TD-LoRA). Extensive experiments on diverse visual generation models, including DiT, SiT, Latte, and FLUX, demonstrate the effectiveness of DyDiT.
Re-Aligning Language to Visual Objects with an Agentic Workflow
Mar 30, 2025Language-based object detection (LOD) aims to align visual objects with language expressions. A large amount of paired data is utilized to improve LOD model generalizations. During the training process, recent studies leverage vision-language models (VLMs) to automatically generate human-like expressions for visual objects, facilitating training data scaling up. In this process, we observe that VLM hallucinations bring inaccurate object descriptions (e.g., object name, color, and shape) to deteriorate VL alignment quality. To reduce VLM hallucinations, we propose an agentic workflow controlled by an LLM to re-align language to visual objects via adaptively adjusting image and text prompts. We name this workflow Real-LOD, which includes planning, tool use, and reflection steps. Given an image with detected objects and VLM raw language expressions, Real-LOD reasons its state automatically and arranges action based on our neural symbolic designs (i.e., planning). The action will adaptively adjust the image and text prompts and send them to VLMs for object re-description (i.e., tool use). Then, we use another LLM to analyze these refined expressions for feedback (i.e., reflection). These steps are conducted in a cyclic form to gradually improve language descriptions for re-aligning to visual objects. We construct a dataset that contains a tiny amount of 0.18M images with re-aligned language expression and train a prevalent LOD model to surpass existing LOD methods by around 50% on the standard benchmarks. Our Real-LOD workflow, with automatic VL refinement, reveals a potential to preserve data quality along with scaling up data quantity, which further improves LOD performance from a data-alignment perspective.
AvatarArtist: Open-Domain 4D Avatarization
Mar 26, 2025This work focuses on open-domain 4D avatarization, with the purpose of creating a 4D avatar from a portrait image in an arbitrary style. We select parametric triplanes as the intermediate 4D representation and propose a practical training paradigm that takes advantage of both generative adversarial networks (GANs) and diffusion models. Our design stems from the observation that 4D GANs excel at bridging images and triplanes without supervision yet usually face challenges in handling diverse data distributions. A robust 2D diffusion prior emerges as the solution, assisting the GAN in transferring its expertise across various domains. The synergy between these experts permits the construction of a multi-domain image-triplane dataset, which drives the development of a general 4D avatar creator. Extensive experiments suggest that our model, AvatarArtist, is capable of producing high-quality 4D avatars with strong robustness to various source image domains. The code, the data, and the models will be made publicly available to facilitate future studies.
UPME: An Unsupervised Peer Review Framework for Multimodal Large Language Model Evaluation
Mar 19, 2025Multimodal Large Language Models (MLLMs) have emerged to tackle the challenges of Visual Question Answering (VQA), sparking a new research focus on conducting objective evaluations of these models. Existing evaluation methods face limitations due to the significant human workload required to design Q&A pairs for visual images, which inherently restricts the scale and scope of evaluations. Although automated MLLM-as-judge approaches attempt to reduce the human workload through automatic evaluations, they often introduce biases. To address these problems, we propose an Unsupervised Peer review MLLM Evaluation framework. It utilizes only image data, allowing models to automatically generate questions and conduct peer review assessments of answers from other models, effectively alleviating the reliance on human workload. Additionally, we introduce the vision-language scoring system to mitigate the bias issues, which focuses on three aspects: (i) response correctness; (ii) visual understanding and reasoning; and (iii) image-text correlation. Experimental results demonstrate that UPME achieves a Pearson correlation of 0.944 with human evaluations on the MMstar dataset and 0.814 on the ScienceQA dataset, indicating that our framework closely aligns with human-designed benchmarks and inherent human preferences.
ATPrompt: Textual Prompt Learning with Embedded Attributes
Dec 12, 2024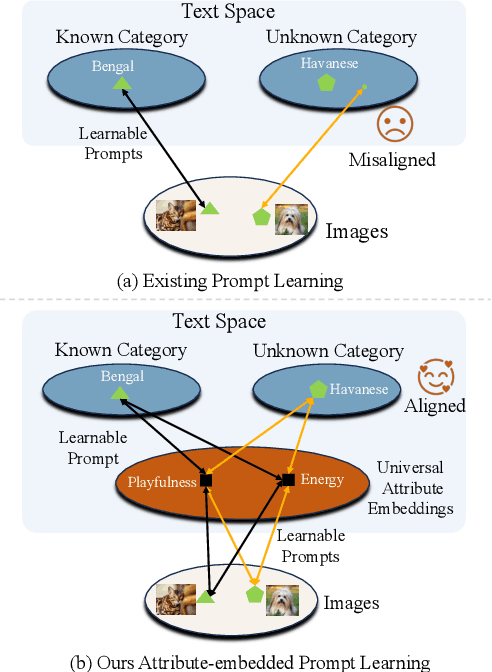
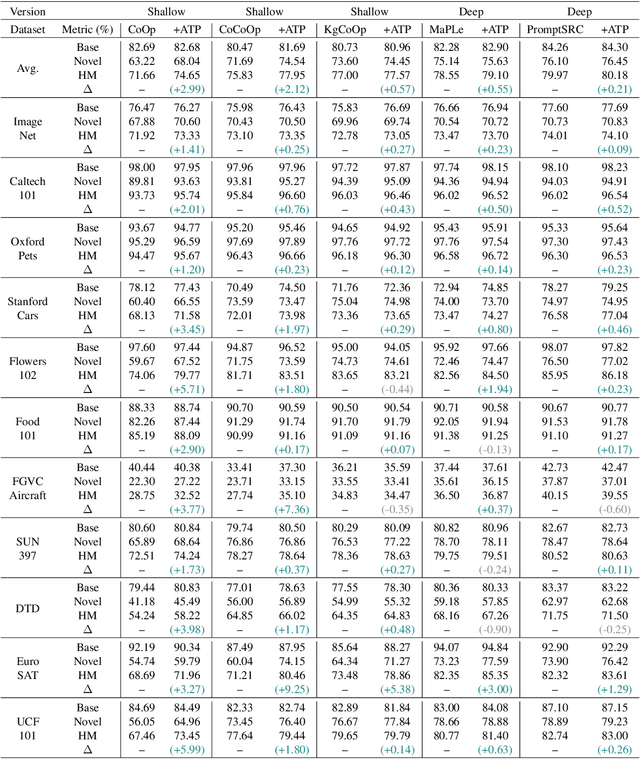
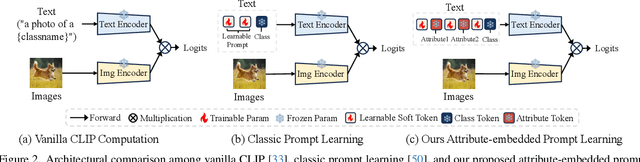
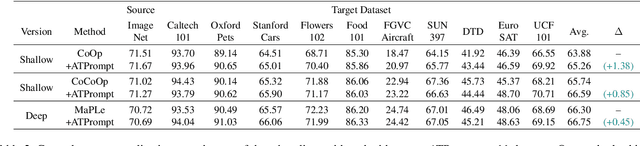
Textual-based prompt learning methods primarily employ multiple learnable soft prompts and hard class tokens in a cascading manner as text prompt inputs, aiming to align image and text (category) spaces for downstream tasks. However, current training is restricted to aligning images with predefined known categories and cannot be associated with unknown categories. In this work, we propose utilizing universal attributes as a bridge to enhance the alignment between images and unknown categories. Specifically, we introduce an Attribute-embedded Textual Prompt learning method for vision-language models, named ATPrompt. This approach expands the learning space of soft prompts from the original one-dimensional category level into the multi-dimensional attribute level by incorporating multiple universal attribute tokens into the learnable soft prompts. Through this modification, we transform the text prompt from a category-centric form to an attribute-category hybrid form. To finalize the attributes for downstream tasks, we propose a differentiable attribute search method that learns to identify representative and suitable attributes from a candidate pool summarized by a large language model. As an easy-to-use plug-in technique, ATPrompt can seamlessly replace the existing prompt format of textual-based methods, offering general improvements at a negligible computational cost. Extensive experiments on 11 datasets demonstrate the effectiveness of our method.
A Stitch in Time Saves Nine: Small VLM is a Precise Guidance for Accelerating Large VLMs
Dec 05, 2024



Vision-language models (VLMs) have shown remarkable success across various multi-modal tasks, yet large VLMs encounter significant efficiency challenges due to processing numerous visual tokens. A promising approach to accelerating large VLM inference is using partial information, such as attention maps from specific layers, to assess token importance and prune less essential tokens. However, our study reveals three key insights: (i) Partial attention information is insufficient for accurately identifying critical visual tokens, resulting in suboptimal performance, especially at low token retention ratios; (ii) Global attention information, such as the attention map aggregated across all layers, more effectively preserves essential tokens and maintains comparable performance under aggressive pruning. However, the attention maps from all layers requires a full inference pass, which increases computational load and is therefore impractical in existing methods; and (iii) The global attention map aggregated from a small VLM closely resembles that of a large VLM, suggesting an efficient alternative. Based on these findings, we introduce a \textbf{training-free} method, \underline{\textbf{S}}mall VLM \underline{\textbf{G}}uidance for accelerating \underline{\textbf{L}}arge VLMs (\textbf{SGL}). Specifically, we employ the attention map aggregated from a small VLM to guide visual token pruning in a large VLM. Additionally, an early exiting mechanism is developed to fully use the small VLM's predictions, dynamically invoking the larger VLM only when necessary, yielding a superior trade-off between accuracy and computation. Extensive evaluations across 11 benchmarks demonstrate the effectiveness and generalizability of SGL, achieving up to 91\% pruning ratio for visual tokens while retaining competitive performance.
LLaVA-CoT: Let Vision Language Models Reason Step-by-Step
Nov 25, 2024



Large language models have demonstrated substantial advancements in reasoning capabilities, particularly through inference-time scaling, as illustrated by models such as OpenAI's o1. However, current Vision-Language Models (VLMs) often struggle to perform systematic and structured reasoning, especially when handling complex visual question-answering tasks. In this work, we introduce LLaVA-CoT, a novel VLM designed to conduct autonomous multistage reasoning. Unlike chain-of-thought prompting, LLaVA-CoT independently engages in sequential stages of summarization, visual interpretation, logical reasoning, and conclusion generation. This structured approach enables LLaVA-CoT to achieve marked improvements in precision on reasoning-intensive tasks. To accomplish this, we compile the LLaVA-CoT-100k dataset, integrating samples from various visual question answering sources and providing structured reasoning annotations. Besides, we propose an inference-time stage-level beam search method, which enables effective inference-time scaling. Remarkably, with only 100k training samples and a simple yet effective inference time scaling method, LLaVA-CoT not only outperforms its base model by 8.9% on a wide range of multimodal reasoning benchmarks, but also surpasses the performance of larger and even closed-source models, such as Gemini-1.5-pro, GPT-4o-mini, and Llama-3.2-90B-Vision-Instruct.