 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgecoDrawAgents: A Multi-Agent Dialogue Framework for Compositional Image Generation
Mar 13, 2026Text-to-image generation has advanced rapidly, but existing models still struggle with faithfully composing multiple objects and preserving their attributes in complex scenes. We propose coDrawAgents, an interactive multi-agent dialogue framework with four specialized agents: Interpreter, Planner, Checker, and Painter that collaborate to improve compositional generation. The Interpreter adaptively decides between a direct text-to-image pathway and a layout-aware multi-agent process. In the layout-aware mode, it parses the prompt into attribute-rich object descriptors, ranks them by semantic salience, and groups objects with the same semantic priority level for joint generation. Guided by the Interpreter, the Planner adopts a divide-and-conquer strategy, incrementally proposing layouts for objects with the same semantic priority level while grounding decisions in the evolving visual context of the canvas. The Checker introduces an explicit error-correction mechanism by validating spatial consistency and attribute alignment, and refining layouts before they are rendered. Finally, the Painter synthesizes the image step by step, incorporating newly planned objects into the canvas to provide richer context for subsequent iterations. Together, these agents address three key challenges: reducing layout complexity, grounding planning in visual context, and enabling explicit error correction. Extensive experiments on benchmarks GenEval and DPG-Bench demonstrate that coDrawAgents substantially improves text-image alignment, spatial accuracy, and attribute binding compared to existing methods.
RynnBrain: Open Embodied Foundation Models
Feb 13, 2026Despite rapid progress in multimodal foundation models, embodied intelligence community still lacks a unified, physically grounded foundation model that integrates perception, reasoning, and planning within real-world spatial-temporal dynamics. We introduce RynnBrain, an open-source spatiotemporal foundation model for embodied intelligence. RynnBrain strengthens four core capabilities in a unified framework: comprehensive egocentric understanding, diverse spatiotemporal localization, physically grounded reasoning, and physics-aware planning. The RynnBrain family comprises three foundation model scales (2B, 8B, and 30B-A3B MoE) and four post-trained variants tailored for downstream embodied tasks (i.e., RynnBrain-Nav, RynnBrain-Plan, and RynnBrain-VLA) or complex spatial reasoning tasks (i.e., RynnBrain-CoP). In terms of extensive evaluations on 20 embodied benchmarks and 8 general vision understanding benchmarks, our RynnBrain foundation models largely outperform existing embodied foundation models by a significant margin. The post-trained model suite further substantiates two key potentials of the RynnBrain foundation model: (i) enabling physically grounded reasoning and planning, and (ii) serving as a strong pretrained backbone that can be efficiently adapted to diverse embodied tasks.
Harnessing Reasoning Trajectories for Hallucination Detection via Answer-agreement Representation Shaping
Jan 24, 2026Large reasoning models (LRMs) often generate long, seemingly coherent reasoning traces yet still produce incorrect answers, making hallucination detection challenging. Although trajectories contain useful signals, directly using trace text or vanilla hidden states for detection is brittle: traces vary in form and detectors can overfit to superficial patterns rather than answer validity. We introduce Answer-agreement Representation Shaping (ARS), which learns detection-friendly trace-conditioned representations by explicitly encoding answer stability. ARS generates counterfactual answers through small latent interventions, specifically, perturbing the trace-boundary embedding, and labels each perturbation by whether the resulting answer agrees with the original. It then learns representations that bring answer-agreeing states together and separate answer-disagreeing ones, exposing latent instability indicative of hallucination risk. The shaped embeddings are plug-and-play with existing embedding-based detectors and require no human annotations during training. Experiments demonstrate that ARS consistently improves detection and achieves substantial gains over strong baselines.
C-DGPA: Class-Centric Dual-Alignment Generative Prompt Adaptation
Dec 18, 2025Unsupervised Domain Adaptation transfers knowledge from a labeled source domain to an unlabeled target domain. Directly deploying Vision-Language Models (VLMs) with prompt tuning in downstream UDA tasks faces the signifi cant challenge of mitigating domain discrepancies. Existing prompt-tuning strategies primarily align marginal distribu tion, but neglect conditional distribution discrepancies, lead ing to critical issues such as class prototype misalignment and degraded semantic discriminability. To address these lim itations, the work proposes C-DGPA: Class-Centric Dual Alignment Generative Prompt Adaptation. C-DGPA syner gistically optimizes marginal distribution alignment and con ditional distribution alignment through a novel dual-branch architecture. The marginal distribution alignment branch em ploys a dynamic adversarial training framework to bridge marginal distribution discrepancies. Simultaneously, the con ditional distribution alignment branch introduces a Class Mapping Mechanism (CMM) to align conditional distribu tion discrepancies by standardizing semantic prompt under standing and preventing source domain over-reliance. This dual alignment strategy effectively integrates domain knowl edge into prompt learning via synergistic optimization, ensur ing domain-invariant and semantically discriminative repre sentations. Extensive experiments on OfficeHome, Office31, and VisDA-2017 validate the superiority of C-DGPA. It achieves new state-of-the-art results on all benchmarks.
RynnVLA-001: Using Human Demonstrations to Improve Robot Manipulation
Sep 18, 2025This paper presents RynnVLA-001, a vision-language-action(VLA) model built upon large-scale video generative pretraining from human demonstrations. We propose a novel two-stage pretraining methodology. The first stage, Ego-Centric Video Generative Pretraining, trains an Image-to-Video model on 12M ego-centric manipulation videos to predict future frames conditioned on an initial frame and a language instruction. The second stage, Human-Centric Trajectory-Aware Modeling, extends this by jointly predicting future keypoint trajectories, thereby effectively bridging visual frame prediction with action prediction. Furthermore, to enhance action representation, we propose ActionVAE, a variational autoencoder that compresses sequences of actions into compact latent embeddings, reducing the complexity of the VLA output space. When finetuned on the same downstream robotics datasets, RynnVLA-001 achieves superior performance over state-of-the-art baselines, demonstrating that the proposed pretraining strategy provides a more effective initialization for VLA models.
Towards Affordance-Aware Robotic Dexterous Grasping with Human-like Priors
Aug 12, 2025A dexterous hand capable of generalizable grasping objects is fundamental for the development of general-purpose embodied AI. However, previous methods focus narrowly on low-level grasp stability metrics, neglecting affordance-aware positioning and human-like poses which are crucial for downstream manipulation. To address these limitations, we propose AffordDex, a novel framework with two-stage training that learns a universal grasping policy with an inherent understanding of both motion priors and object affordances. In the first stage, a trajectory imitator is pre-trained on a large corpus of human hand motions to instill a strong prior for natural movement. In the second stage, a residual module is trained to adapt these general human-like motions to specific object instances. This refinement is critically guided by two components: our Negative Affordance-aware Segmentation (NAA) module, which identifies functionally inappropriate contact regions, and a privileged teacher-student distillation process that ensures the final vision-based policy is highly successful. Extensive experiments demonstrate that AffordDex not only achieves universal dexterous grasping but also remains remarkably human-like in posture and functionally appropriate in contact location. As a result, AffordDex significantly outperforms state-of-the-art baselines across seen objects, unseen instances, and even entirely novel categories.
WorldVLA: Towards Autoregressive Action World Model
Jun 26, 2025We present WorldVLA, an autoregressive action world model that unifies action and image understanding and generation. Our WorldVLA intergrates Vision-Language-Action (VLA) model and world model in one single framework. The world model predicts future images by leveraging both action and image understanding, with the purpose of learning the underlying physics of the environment to improve action generation. Meanwhile, the action model generates the subsequent actions based on image observations, aiding in visual understanding and in turn helps visual generation of the world model. We demonstrate that WorldVLA outperforms standalone action and world models, highlighting the mutual enhancement between the world model and the action model. In addition, we find that the performance of the action model deteriorates when generating sequences of actions in an autoregressive manner. This phenomenon can be attributed to the model's limited generalization capability for action prediction, leading to the propagation of errors from earlier actions to subsequent ones. To address this issue, we propose an attention mask strategy that selectively masks prior actions during the generation of the current action, which shows significant performance improvement in the action chunk generation task.
Vchitect-2.0: Parallel Transformer for Scaling Up Video Diffusion Models
Jan 14, 2025
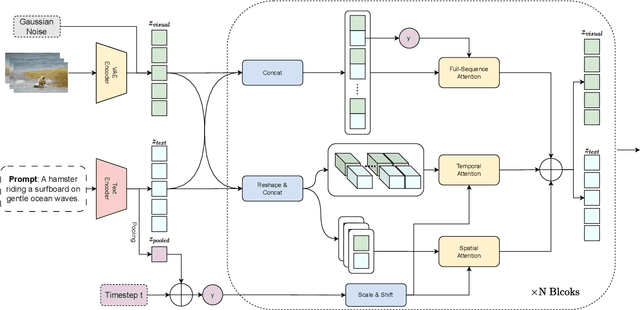
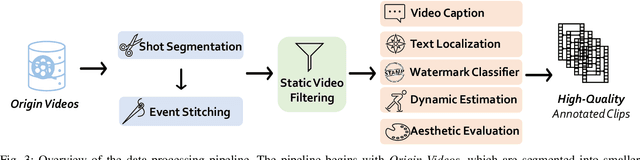
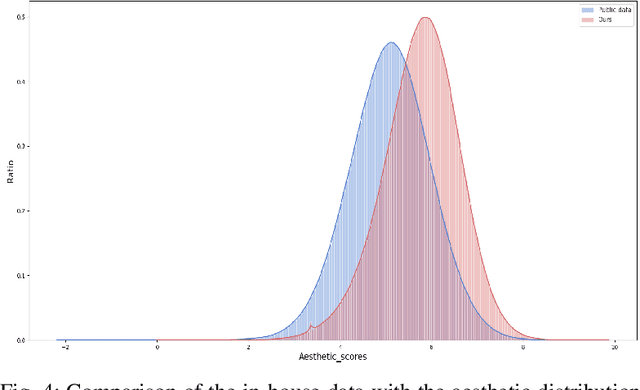
We present Vchitect-2.0, a parallel transformer architecture designed to scale up video diffusion models for large-scale text-to-video generation. The overall Vchitect-2.0 system has several key designs. (1) By introducing a novel Multimodal Diffusion Block, our approach achieves consistent alignment between text descriptions and generated video frames, while maintaining temporal coherence across sequences. (2) To overcome memory and computational bottlenecks, we propose a Memory-efficient Training framework that incorporates hybrid parallelism and other memory reduction techniques, enabling efficient training of long video sequences on distributed systems. (3) Additionally, our enhanced data processing pipeline ensures the creation of Vchitect T2V DataVerse, a high-quality million-scale training dataset through rigorous annotation and aesthetic evaluation. Extensive benchmarking demonstrates that Vchitect-2.0 outperforms existing methods in video quality, training efficiency, and scalability, serving as a suitable base for high-fidelity video generation.
Aligning Knowledge Concepts to Whole Slide Images for Precise Histopathology Image Analysis
Nov 27, 2024Due to the large size and lack of fine-grained annotation, Whole Slide Images (WSIs) analysis is commonly approached as a Multiple Instance Learning (MIL) problem. However, previous studies only learn from training data, posing a stark contrast to how human clinicians teach each other and reason about histopathologic entities and factors. Here we present a novel knowledge concept-based MIL framework, named ConcepPath to fill this gap. Specifically, ConcepPath utilizes GPT-4 to induce reliable diseasespecific human expert concepts from medical literature, and incorporate them with a group of purely learnable concepts to extract complementary knowledge from training data. In ConcepPath, WSIs are aligned to these linguistic knowledge concepts by utilizing pathology vision-language model as the basic building component. In the application of lung cancer subtyping, breast cancer HER2 scoring, and gastric cancer immunotherapy-sensitive subtyping task, ConcepPath significantly outperformed previous SOTA methods which lack the guidance of human expert knowledge.
VBench++: Comprehensive and Versatile Benchmark Suite for Video Generative Models
Nov 20, 2024



Video generation has witnessed significant advancements, yet evaluating these models remains a challenge. A comprehensive evaluation benchmark for video generation is indispensable for two reasons: 1) Existing metrics do not fully align with human perceptions; 2) An ideal evaluation system should provide insights to inform future developments of video generation. To this end, we present VBench, a comprehensive benchmark suite that dissects "video generation quality" into specific, hierarchical, and disentangled dimensions, each with tailored prompts and evaluation methods. VBench has several appealing properties: 1) Comprehensive Dimensions: VBench comprises 16 dimensions in video generation (e.g., subject identity inconsistency, motion smoothness, temporal flickering, and spatial relationship, etc). The evaluation metrics with fine-grained levels reveal individual models' strengths and weaknesses. 2) Human Alignment: We also provide a dataset of human preference annotations to validate our benchmarks' alignment with human perception, for each evaluation dimension respectively. 3) Valuable Insights: We look into current models' ability across various evaluation dimensions, and various content types. We also investigate the gaps between video and image generation models. 4) Versatile Benchmarking: VBench++ supports evaluating text-to-video and image-to-video. We introduce a high-quality Image Suite with an adaptive aspect ratio to enable fair evaluations across different image-to-video generation settings. Beyond assessing technical quality, VBench++ evaluates the trustworthiness of video generative models, providing a more holistic view of model performance. 5) Full Open-Sourcing: We fully open-source VBench++ and continually add new video generation models to our leaderboard to drive forward the field of video generation.