 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRynnBrain: Open Embodied Foundation Models
Feb 13, 2026Despite rapid progress in multimodal foundation models, embodied intelligence community still lacks a unified, physically grounded foundation model that integrates perception, reasoning, and planning within real-world spatial-temporal dynamics. We introduce RynnBrain, an open-source spatiotemporal foundation model for embodied intelligence. RynnBrain strengthens four core capabilities in a unified framework: comprehensive egocentric understanding, diverse spatiotemporal localization, physically grounded reasoning, and physics-aware planning. The RynnBrain family comprises three foundation model scales (2B, 8B, and 30B-A3B MoE) and four post-trained variants tailored for downstream embodied tasks (i.e., RynnBrain-Nav, RynnBrain-Plan, and RynnBrain-VLA) or complex spatial reasoning tasks (i.e., RynnBrain-CoP). In terms of extensive evaluations on 20 embodied benchmarks and 8 general vision understanding benchmarks, our RynnBrain foundation models largely outperform existing embodied foundation models by a significant margin. The post-trained model suite further substantiates two key potentials of the RynnBrain foundation model: (i) enabling physically grounded reasoning and planning, and (ii) serving as a strong pretrained backbone that can be efficiently adapted to diverse embodied tasks.
RynnEC: Bringing MLLMs into Embodied World
Aug 19, 2025We introduce RynnEC, a video multimodal large language model designed for embodied cognition. Built upon a general-purpose vision-language foundation model, RynnEC incorporates a region encoder and a mask decoder, enabling flexible region-level video interaction. Despite its compact architecture, RynnEC achieves state-of-the-art performance in object property understanding, object segmentation, and spatial reasoning. Conceptually, it offers a region-centric video paradigm for the brain of embodied agents, providing fine-grained perception of the physical world and enabling more precise interactions. To mitigate the scarcity of annotated 3D datasets, we propose an egocentric video based pipeline for generating embodied cognition data. Furthermore, we introduce RynnEC-Bench, a region-centered benchmark for evaluating embodied cognitive capabilities. We anticipate that RynnEC will advance the development of general-purpose cognitive cores for embodied agents and facilitate generalization across diverse embodied tasks. The code, model checkpoints, and benchmark are available at: https://github.com/alibaba-damo-academy/RynnEC
EOC-Bench: Can MLLMs Identify, Recall, and Forecast Objects in an Egocentric World?
Jun 05, 2025



The emergence of multimodal large language models (MLLMs) has driven breakthroughs in egocentric vision applications. These applications necessitate persistent, context-aware understanding of objects, as users interact with tools in dynamic and cluttered environments. However, existing embodied benchmarks primarily focus on static scene exploration, emphasizing object's appearance and spatial attributes while neglecting the assessment of dynamic changes arising from users' interactions. To address this gap, we introduce EOC-Bench, an innovative benchmark designed to systematically evaluate object-centric embodied cognition in dynamic egocentric scenarios. Specially, EOC-Bench features 3,277 meticulously annotated QA pairs categorized into three temporal categories: Past, Present, and Future, covering 11 fine-grained evaluation dimensions and 3 visual object referencing types. To ensure thorough assessment, we develop a mixed-format human-in-the-loop annotation framework with four types of questions and design a novel multi-scale temporal accuracy metric for open-ended temporal evaluation. Based on EOC-Bench, we conduct comprehensive evaluations of various proprietary, open-source, and object-level MLLMs. EOC-Bench serves as a crucial tool for advancing the embodied object cognitive capabilities of MLLMs, establishing a robust foundation for developing reliable core models for embodied systems.
ECBench: Can Multi-modal Foundation Models Understand the Egocentric World? A Holistic Embodied Cognition Benchmark
Jan 09, 2025



The enhancement of generalization in robots by large vision-language models (LVLMs) is increasingly evident. Therefore, the embodied cognitive abilities of LVLMs based on egocentric videos are of great interest. However, current datasets for embodied video question answering lack comprehensive and systematic evaluation frameworks. Critical embodied cognitive issues, such as robotic self-cognition, dynamic scene perception, and hallucination, are rarely addressed. To tackle these challenges, we propose ECBench, a high-quality benchmark designed to systematically evaluate the embodied cognitive abilities of LVLMs. ECBench features a diverse range of scene video sources, open and varied question formats, and 30 dimensions of embodied cognition. To ensure quality, balance, and high visual dependence, ECBench uses class-independent meticulous human annotation and multi-round question screening strategies. Additionally, we introduce ECEval, a comprehensive evaluation system that ensures the fairness and rationality of the indicators. Utilizing ECBench, we conduct extensive evaluations of proprietary, open-source, and task-specific LVLMs. ECBench is pivotal in advancing the embodied cognitive capabilities of LVLMs, laying a solid foundation for developing reliable core models for embodied agents. All data and code are available at https://github.com/Rh-Dang/ECBench.
Chain of Ideas: Revolutionizing Research Via Novel Idea Development with LLM Agents
Oct 25, 2024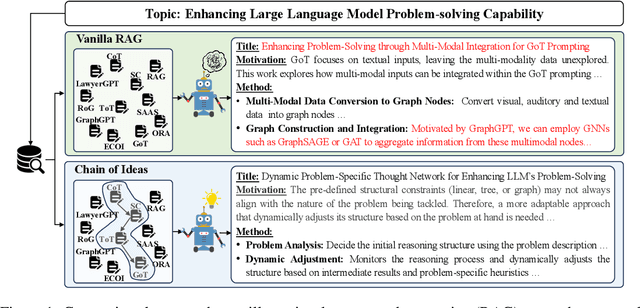

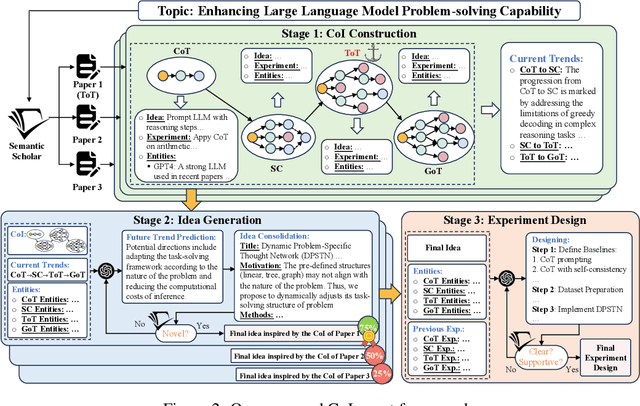
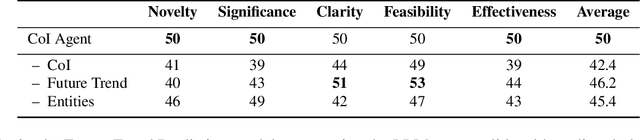
Effective research ideation is a critical step for scientific research. However, the exponential increase in scientific literature makes it challenging for researchers to stay current with recent advances and identify meaningful research directions. Recent developments in large language models~(LLMs) suggest a promising avenue for automating the generation of novel research ideas. However, existing methods for idea generation either trivially prompt LLMs or directly expose LLMs to extensive literature without indicating useful information. Inspired by the research process of human researchers, we propose a Chain-of-Ideas~(CoI) agent, an LLM-based agent that organizes relevant literature in a chain structure to effectively mirror the progressive development in a research domain. This organization facilitates LLMs to capture the current advancements in research, thereby enhancing their ideation capabilities. Furthermore, we propose Idea Arena, an evaluation protocol that can comprehensively evaluate idea generation methods from different perspectives, aligning closely with the preferences of human researchers. Experimental results indicate that the CoI agent consistently outperforms other methods and shows comparable quality as humans in research idea generation. Moreover, our CoI agent is budget-friendly, with a minimum cost of \$0.50 to generate a candidate idea and its corresponding experimental design.
Chain of Ideas: Revolutionizing Research in Novel Idea Development with LLM Agents
Oct 17, 2024Effective research ideation is a critical step for scientific research. However, the exponential increase in scientific literature makes it challenging for researchers to stay current with recent advances and identify meaningful research directions. Recent developments in large language models~(LLMs) suggest a promising avenue for automating the generation of novel research ideas. However, existing methods for idea generation either trivially prompt LLMs or directly expose LLMs to extensive literature without indicating useful information. Inspired by the research process of human researchers, we propose a Chain-of-Ideas~(CoI) agent, an LLM-based agent that organizes relevant literature in a chain structure to effectively mirror the progressive development in a research domain. This organization facilitates LLMs to capture the current advancements in research, thereby enhancing their ideation capabilities. Furthermore, we propose Idea Arena, an evaluation protocol that can comprehensively evaluate idea generation methods from different perspectives, aligning closely with the preferences of human researchers. Experimental results indicate that the CoI agent consistently outperforms other methods and shows comparable quality as humans in research idea generation. Moreover, our CoI agent is budget-friendly, with a minimum cost of \$0.50 to generate a candidate idea and its corresponding experimental design.
MoTE: Reconciling Generalization with Specialization for Visual-Language to Video Knowledge Transfer
Oct 14, 2024Transferring visual-language knowledge from large-scale foundation models for video recognition has proved to be effective. To bridge the domain gap, additional parametric modules are added to capture the temporal information. However, zero-shot generalization diminishes with the increase in the number of specialized parameters, making existing works a trade-off between zero-shot and close-set performance. In this paper, we present MoTE, a novel framework that enables generalization and specialization to be balanced in one unified model. Our approach tunes a mixture of temporal experts to learn multiple task views with various degrees of data fitting. To maximally preserve the knowledge of each expert, we propose \emph{Weight Merging Regularization}, which regularizes the merging process of experts in weight space. Additionally with temporal feature modulation to regularize the contribution of temporal feature during test. We achieve a sound balance between zero-shot and close-set video recognition tasks and obtain state-of-the-art or competitive results on various datasets, including Kinetics-400 \& 600, UCF, and HMDB. Code is available at \url{https://github.com/ZMHH-H/MoTE}.
Vision-and-Language Navigation via Causal Learning
Apr 16, 2024In the pursuit of robust and generalizable environment perception and language understanding, the ubiquitous challenge of dataset bias continues to plague vision-and-language navigation (VLN) agents, hindering their performance in unseen environments. This paper introduces the generalized cross-modal causal transformer (GOAT), a pioneering solution rooted in the paradigm of causal inference. By delving into both observable and unobservable confounders within vision, language, and history, we propose the back-door and front-door adjustment causal learning (BACL and FACL) modules to promote unbiased learning by comprehensively mitigating potential spurious correlations. Additionally, to capture global confounder features, we propose a cross-modal feature pooling (CFP) module supervised by contrastive learning, which is also shown to be effective in improving cross-modal representations during pre-training. Extensive experiments across multiple VLN datasets (R2R, REVERIE, RxR, and SOON) underscore the superiority of our proposed method over previous state-of-the-art approaches. Code is available at https://github.com/CrystalSixone/VLN-GOAT.
Causality-based Cross-Modal Representation Learning for Vision-and-Language Navigation
Mar 06, 2024Vision-and-Language Navigation (VLN) has gained significant research interest in recent years due to its potential applications in real-world scenarios. However, existing VLN methods struggle with the issue of spurious associations, resulting in poor generalization with a significant performance gap between seen and unseen environments. In this paper, we tackle this challenge by proposing a unified framework CausalVLN based on the causal learning paradigm to train a robust navigator capable of learning unbiased feature representations. Specifically, we establish reasonable assumptions about confounders for vision and language in VLN using the structured causal model (SCM). Building upon this, we propose an iterative backdoor-based representation learning (IBRL) method that allows for the adaptive and effective intervention on confounders. Furthermore, we introduce the visual and linguistic backdoor causal encoders to enable unbiased feature expression for multi-modalities during training and validation, enhancing the agent's capability to generalize across different environments. Experiments on three VLN datasets (R2R, RxR, and REVERIE) showcase the superiority of our proposed method over previous state-of-the-art approaches. Moreover, detailed visualization analysis demonstrates the effectiveness of CausalVLN in significantly narrowing down the performance gap between seen and unseen environments, underscoring its strong generalization capability.
CLIPose: Category-Level Object Pose Estimation with Pre-trained Vision-Language Knowledge
Feb 24, 2024



Most of existing category-level object pose estimation methods devote to learning the object category information from point cloud modality. However, the scale of 3D datasets is limited due to the high cost of 3D data collection and annotation. Consequently, the category features extracted from these limited point cloud samples may not be comprehensive. This motivates us to investigate whether we can draw on knowledge of other modalities to obtain category information. Inspired by this motivation, we propose CLIPose, a novel 6D pose framework that employs the pre-trained vision-language model to develop better learning of object category information, which can fully leverage abundant semantic knowledge in image and text modalities. To make the 3D encoder learn category-specific features more efficiently, we align representations of three modalities in feature space via multi-modal contrastive learning. In addition to exploiting the pre-trained knowledge of the CLIP's model, we also expect it to be more sensitive with pose parameters. Therefore, we introduce a prompt tuning approach to fine-tune image encoder while we incorporate rotations and translations information in the text descriptions. CLIPose achieves state-of-the-art performance on two mainstream benchmark datasets, REAL275 and CAMERA25, and runs in real-time during inference (40FPS).