 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniNFT: Modality-wise Omni Diffusion Reinforcement for Joint Audio-Video Generation
May 12, 2026Recent advances in joint audio-video generation have been remarkable, yet real-world applications demand strong per-modality fidelity, cross-modal alignment, and fine-grained synchronization. Reinforcement Learning (RL) offers a promising paradigm, but its extension to multi-objective and multi-modal joint audio-video generation remains unexplored. Notably, our in-depth analysis first reveals that the primary obstacles to applying RL in this stem from: (i) multi-objective advantages inconsistency, where the advantages of multimodal outputs are not always consistent within a group; (ii) multi-modal gradients imbalance, where video-branch gradients leak into shallow audio layers responsible for intra-modal generation; (iii) uniform credit assignment, where fine-grained cross-modal alignment regions fail to get efficient exploration. These shortcomings suggest that vanilla RL fine-tuning strategy with a single global advantage often leads to suboptimal results. To address these challenges, we propose OmniNFT, a novel modality-aware online diffusion RL framework with three key innovations: (1) Modality-wise advantage routing, which routes independent per-reward advantages to their respective modality generation branches. (2) Layer-wise gradient surgery, which selectively detaches video-branch gradients on shallow audio layers while retaining those for cross-modal interaction layers. (3) Region-wise loss reweighting, which modulates policy optimization toward critical regions related to audio-video synchronization and fine-grained alignment. Extensive experiments on JavisBench and VBench with the LTX-2 backbone demonstrate that OmniNFT achieves comprehensive improvements in audio and video perceptual quality, cross-modal alignment, and audio-video synchronization.
Thinking with Novel Views: A Systematic Analysis of Generative-Augmented Spatial Intelligence
May 11, 2026Current Large Multimodal Models (LMMs) struggle with spatial reasoning tasks requiring viewpoint-dependent understanding, largely because they are confined to a single, static observation. We propose Thinking with Novel Views (TwNV), a paradigm that integrates generative novel-view synthesis into the reasoning loop: a Reasoner LMM identifies spatial ambiguity, instructs a Painter to synthesize an alternative viewpoint, and re-examines the scene with the additional evidence. Through systematic experiments we address three research questions. (1) Instruction format: numerical camera-pose specifications yield more reliable view control than free-form language. (2) Generation fidelity: synthesized view quality is tightly coupled with downstream spatial accuracy. (3) Inference-time visual scaling: iterative multi-turn view refinement further improves performance, echoing recent scaling trends in language reasoning. Across four spatial subtask categories and four LMM architectures (both closed- and open-source), TwNV consistently improves accuracy by +1.3 to +3.9 pp, with the largest gains on viewpoint-sensitive subtasks. These results establish novel-view generation as a practical lever for advancing spatial intelligence of LMMs.
Awaking Spatial Intelligence in Unified Multimodal Understanding and Generation
May 05, 2026We present JoyAI-Image, a unified multimodal foundation model for visual understanding, text-to-image generation, and instruction-guided image editing. JoyAI-Image couples a spatially enhanced Multimodal Large Language Model (MLLM) with a Multimodal Diffusion Transformer (MMDiT), allowing perception and generation to interact through a shared multimodal interface. Around this architecture, we build a scalable training recipe that combines unified instruction tuning, long-text rendering supervision, spatially grounded data, and both general and spatial editing signals. This design gives the model broad multimodal capability while strengthening geometry-aware reasoning and controllable visual synthesis. Experiments across understanding, generation, long-text rendering, and editing benchmarks show that JoyAI-Image achieves state-of-the-art or highly competitive performance. More importantly, the bidirectional loop between enhanced understanding, controllable spatial editing, and novel-view-assisted reasoning enables the model to move beyond general visual competence toward stronger spatial intelligence. These results suggest a promising path for unified visual models in downstream applications such as vision-language-action systems and world models.
SpatialEdit: Benchmarking Fine-Grained Image Spatial Editing
Apr 06, 2026Image spatial editing performs geometry-driven transformations, allowing precise control over object layout and camera viewpoints. Current models are insufficient for fine-grained spatial manipulations, motivating a dedicated assessment suite. Our contributions are listed: (i) We introduce SpatialEdit-Bench, a complete benchmark that evaluates spatial editing by jointly measuring perceptual plausibility and geometric fidelity via viewpoint reconstruction and framing analysis. (ii) To address the data bottleneck for scalable training, we construct SpatialEdit-500k, a synthetic dataset generated with a controllable Blender pipeline that renders objects across diverse backgrounds and systematic camera trajectories, providing precise ground-truth transformations for both object- and camera-centric operations. (iii) Building on this data, we develop SpatialEdit-16B, a baseline model for fine-grained spatial editing. Our method achieves competitive performance on general editing while substantially outperforming prior methods on spatial manipulation tasks. All resources will be made public at https://github.com/EasonXiao-888/SpatialEdit.
ATM-GAD: Adaptive Temporal Motif Graph Anomaly Detection for Financial Transaction Networks
Aug 28, 2025
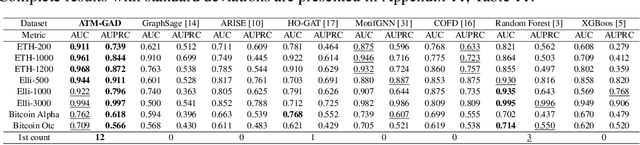
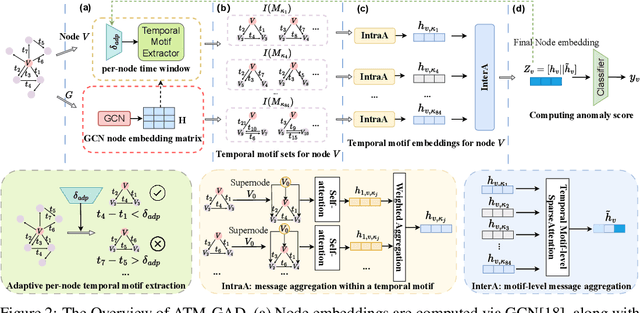
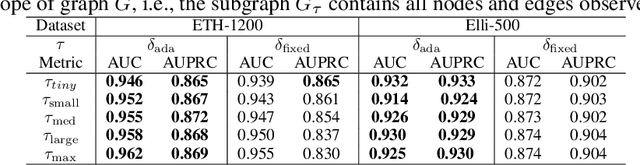
Financial fraud detection is essential to safeguard billions of dollars, yet the intertwined entities and fast-changing transaction behaviors in modern financial systems routinely defeat conventional machine learning models. Recent graph-based detectors make headway by representing transactions as networks, but they still overlook two fraud hallmarks rooted in time: (1) temporal motifs--recurring, telltale subgraphs that reveal suspicious money flows as they unfold--and (2) account-specific intervals of anomalous activity, when fraud surfaces only in short bursts unique to each entity. To exploit both signals, we introduce ATM-GAD, an adaptive graph neural network that leverages temporal motifs for financial anomaly detection. A Temporal Motif Extractor condenses each account's transaction history into the most informative motifs, preserving both topology and temporal patterns. These motifs are then analyzed by dual-attention blocks: IntraA reasons over interactions within a single motif, while InterA aggregates evidence across motifs to expose multi-step fraud schemes. In parallel, a differentiable Adaptive Time-Window Learner tailors the observation window for every node, allowing the model to focus precisely on the most revealing time slices. Experiments on four real-world datasets show that ATM-GAD consistently outperforms seven strong anomaly-detection baselines, uncovering fraud patterns missed by earlier methods.
LoRA-Gen: Specializing Large Language Model via Online LoRA Generation
Jun 13, 2025



Recent advances have highlighted the benefits of scaling language models to enhance performance across a wide range of NLP tasks. However, these approaches still face limitations in effectiveness and efficiency when applied to domain-specific tasks, particularly for small edge-side models. We propose the LoRA-Gen framework, which utilizes a large cloud-side model to generate LoRA parameters for edge-side models based on task descriptions. By employing the reparameterization technique, we merge the LoRA parameters into the edge-side model to achieve flexible specialization. Our method facilitates knowledge transfer between models while significantly improving the inference efficiency of the specialized model by reducing the input context length. Without specialized training, LoRA-Gen outperforms conventional LoRA fine-tuning, which achieves competitive accuracy and a 2.1x speedup with TinyLLaMA-1.1B in reasoning tasks. Besides, our method delivers a compression ratio of 10.1x with Gemma-2B on intelligent agent tasks.
DetailFusion: A Dual-branch Framework with Detail Enhancement for Composed Image Retrieval
May 23, 2025Composed Image Retrieval (CIR) aims to retrieve target images from a gallery based on a reference image and modification text as a combined query. Recent approaches focus on balancing global information from two modalities and encode the query into a unified feature for retrieval. However, due to insufficient attention to fine-grained details, these coarse fusion methods often struggle with handling subtle visual alterations or intricate textual instructions. In this work, we propose DetailFusion, a novel dual-branch framework that effectively coordinates information across global and detailed granularities, thereby enabling detail-enhanced CIR. Our approach leverages atomic detail variation priors derived from an image editing dataset, supplemented by a detail-oriented optimization strategy to develop a Detail-oriented Inference Branch. Furthermore, we design an Adaptive Feature Compositor that dynamically fuses global and detailed features based on fine-grained information of each unique multimodal query. Extensive experiments and ablation analyses not only demonstrate that our method achieves state-of-the-art performance on both CIRR and FashionIQ datasets but also validate the effectiveness and cross-domain adaptability of detail enhancement for CIR.
TensorAR: Refinement is All You Need in Autoregressive Image Generation
May 22, 2025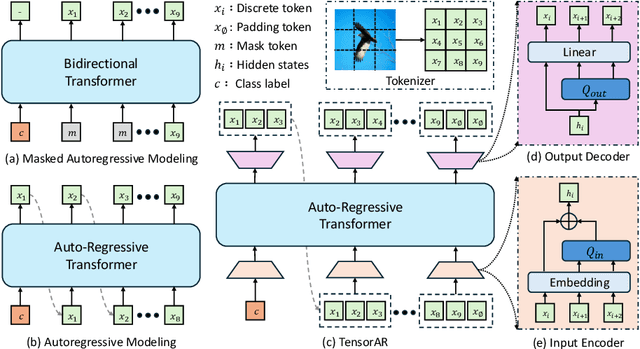

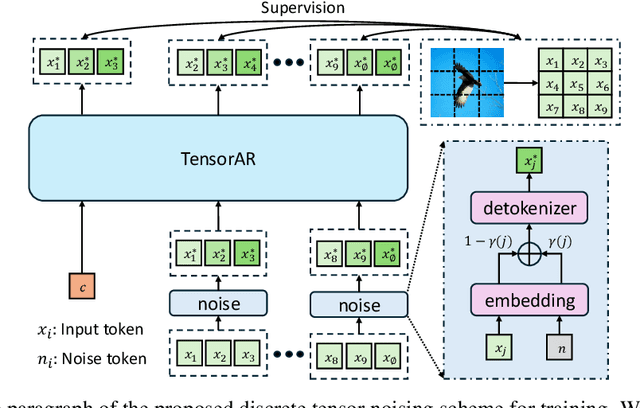

Autoregressive (AR) image generators offer a language-model-friendly approach to image generation by predicting discrete image tokens in a causal sequence. However, unlike diffusion models, AR models lack a mechanism to refine previous predictions, limiting their generation quality. In this paper, we introduce TensorAR, a new AR paradigm that reformulates image generation from next-token prediction to next-tensor prediction. By generating overlapping windows of image patches (tensors) in a sliding fashion, TensorAR enables iterative refinement of previously generated content. To prevent information leakage during training, we propose a discrete tensor noising scheme, which perturbs input tokens via codebook-indexed noise. TensorAR is implemented as a plug-and-play module compatible with existing AR models. Extensive experiments on LlamaGEN, Open-MAGVIT2, and RAR demonstrate that TensorAR significantly improves the generation performance of autoregressive models.
MindOmni: Unleashing Reasoning Generation in Vision Language Models with RGPO
May 19, 2025



Recent text-to-image systems face limitations in handling multimodal inputs and complex reasoning tasks. We introduce MindOmni, a unified multimodal large language model that addresses these challenges by incorporating reasoning generation through reinforcement learning. MindOmni leverages a three-phase training strategy: i) design of a unified vision language model with a decoder-only diffusion module, ii) supervised fine-tuning with Chain-of-Thought (CoT) instruction data, and iii) our proposed Reasoning Generation Policy Optimization (RGPO) algorithm, utilizing multimodal feedback to effectively guide policy updates. Experimental results demonstrate that MindOmni outperforms existing models, achieving impressive performance on both understanding and generation benchmarks, meanwhile showcasing advanced fine-grained reasoning generation capabilities, especially with mathematical reasoning instruction. All codes will be made public at \href{https://github.com/EasonXiao-888/MindOmni}{https://github.com/EasonXiao-888/MindOmni}.
YOLO-UniOW: Efficient Universal Open-World Object Detection
Dec 30, 2024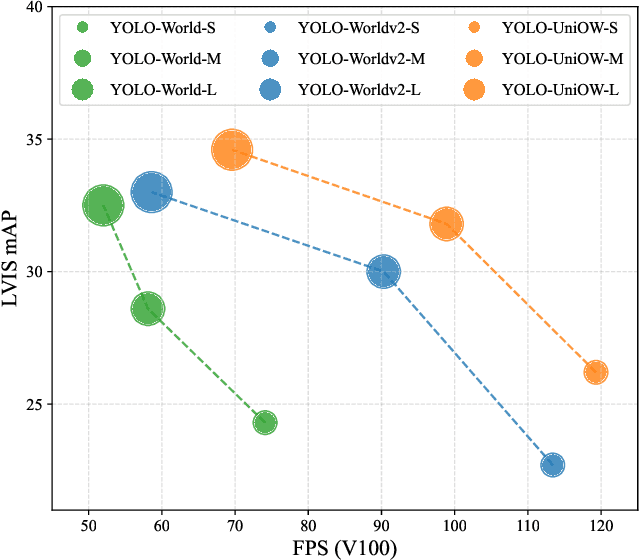
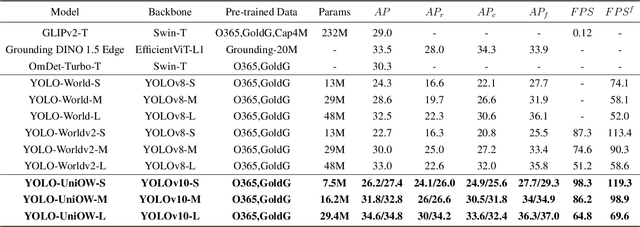
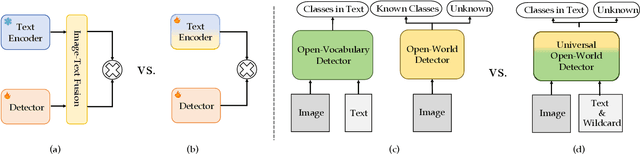
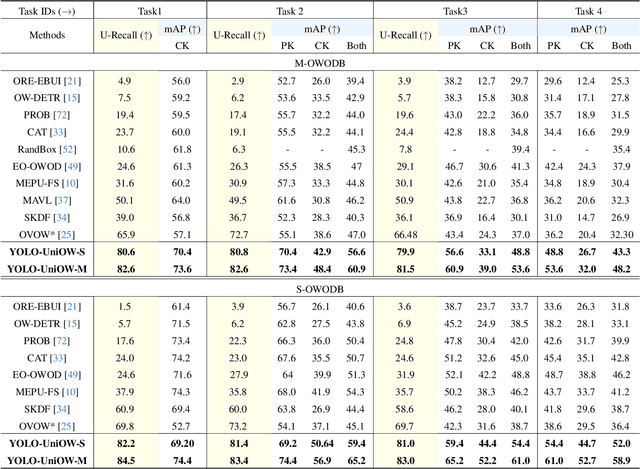
Traditional object detection models are constrained by the limitations of closed-set datasets, detecting only categories encountered during training. While multimodal models have extended category recognition by aligning text and image modalities, they introduce significant inference overhead due to cross-modality fusion and still remain restricted by predefined vocabulary, leaving them ineffective at handling unknown objects in open-world scenarios. In this work, we introduce Universal Open-World Object Detection (Uni-OWD), a new paradigm that unifies open-vocabulary and open-world object detection tasks. To address the challenges of this setting, we propose YOLO-UniOW, a novel model that advances the boundaries of efficiency, versatility, and performance. YOLO-UniOW incorporates Adaptive Decision Learning to replace computationally expensive cross-modality fusion with lightweight alignment in the CLIP latent space, achieving efficient detection without compromising generalization. Additionally, we design a Wildcard Learning strategy that detects out-of-distribution objects as "unknown" while enabling dynamic vocabulary expansion without the need for incremental learning. This design empowers YOLO-UniOW to seamlessly adapt to new categories in open-world environments. Extensive experiments validate the superiority of YOLO-UniOW, achieving achieving 34.6 AP and 30.0 APr on LVIS with an inference speed of 69.6 FPS. The model also sets benchmarks on M-OWODB, S-OWODB, and nuScenes datasets, showcasing its unmatched performance in open-world object detection. Code and models are available at https://github.com/THU-MIG/YOLO-UniOW.