 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindOmni: Unleashing Reasoning Generation in Vision Language Models with RGPO
May 19, 2025



Recent text-to-image systems face limitations in handling multimodal inputs and complex reasoning tasks. We introduce MindOmni, a unified multimodal large language model that addresses these challenges by incorporating reasoning generation through reinforcement learning. MindOmni leverages a three-phase training strategy: i) design of a unified vision language model with a decoder-only diffusion module, ii) supervised fine-tuning with Chain-of-Thought (CoT) instruction data, and iii) our proposed Reasoning Generation Policy Optimization (RGPO) algorithm, utilizing multimodal feedback to effectively guide policy updates. Experimental results demonstrate that MindOmni outperforms existing models, achieving impressive performance on both understanding and generation benchmarks, meanwhile showcasing advanced fine-grained reasoning generation capabilities, especially with mathematical reasoning instruction. All codes will be made public at \href{https://github.com/EasonXiao-888/MindOmni}{https://github.com/EasonXiao-888/MindOmni}.
EA-VTR: Event-Aware Video-Text Retrieval
Jul 10, 2024



Understanding the content of events occurring in the video and their inherent temporal logic is crucial for video-text retrieval. However, web-crawled pre-training datasets often lack sufficient event information, and the widely adopted video-level cross-modal contrastive learning also struggles to capture detailed and complex video-text event alignment. To address these challenges, we make improvements from both data and model perspectives. In terms of pre-training data, we focus on supplementing the missing specific event content and event temporal transitions with the proposed event augmentation strategies. Based on the event-augmented data, we construct a novel Event-Aware Video-Text Retrieval model, ie, EA-VTR, which achieves powerful video-text retrieval ability through superior video event awareness. EA-VTR can efficiently encode frame-level and video-level visual representations simultaneously, enabling detailed event content and complex event temporal cross-modal alignment, ultimately enhancing the comprehensive understanding of video events. Our method not only significantly outperforms existing approaches on multiple datasets for Text-to-Video Retrieval and Video Action Recognition tasks, but also demonstrates superior event content perceive ability on Multi-event Video-Text Retrieval and Video Moment Retrieval tasks, as well as outstanding event temporal logic understanding ability on Test of Time task.
PosterLLaVa: Constructing a Unified Multi-modal Layout Generator with LLM
Jun 05, 2024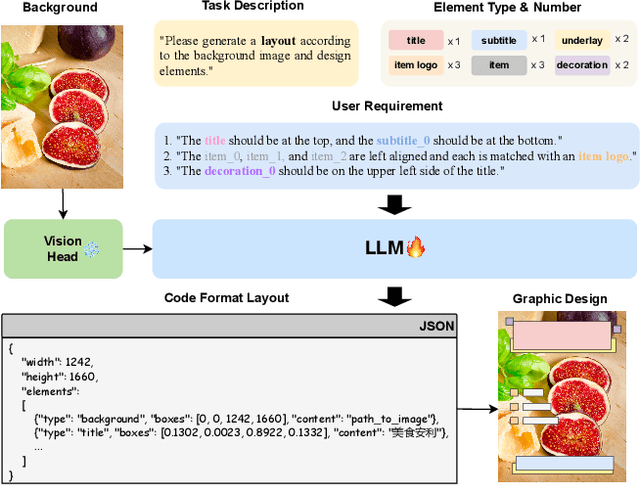



Layout generation is the keystone in achieving automated graphic design, requiring arranging the position and size of various multi-modal design elements in a visually pleasing and constraint-following manner. Previous approaches are either inefficient for large-scale applications or lack flexibility for varying design requirements. Our research introduces a unified framework for automated graphic layout generation, leveraging the multi-modal large language model (MLLM) to accommodate diverse design tasks. In contrast, our data-driven method employs structured text (JSON format) and visual instruction tuning to generate layouts under specific visual and textual constraints, including user-defined natural language specifications. We conducted extensive experiments and achieved state-of-the-art (SOTA) performance on public multi-modal layout generation benchmarks, demonstrating the effectiveness of our method. Moreover, recognizing existing datasets' limitations in capturing the complexity of real-world graphic designs, we propose two new datasets for much more challenging tasks (user-constrained generation and complicated poster), further validating our model's utility in real-life settings. Marking by its superior accessibility and adaptability, this approach further automates large-scale graphic design tasks. The code and datasets will be publicly available on https://github.com/posterllava/PosterLLaVA.