 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking MLLMs Blind: Adversarial Smuggling Attacks in MLLM Content Moderation
Apr 09, 2026Multimodal Large Language Models (MLLMs) are increasingly being deployed as automated content moderators. Within this landscape, we uncover a critical threat: Adversarial Smuggling Attacks. Unlike adversarial perturbations (for misclassification) and adversarial jailbreaks (for harmful output generation), adversarial smuggling exploits the Human-AI capability gap. It encodes harmful content into human-readable visual formats that remain AI-unreadable, thereby evading automated detection and enabling the dissemination of harmful content. We classify smuggling attacks into two pathways: (1) Perceptual Blindness, disrupting text recognition; and (2) Reasoning Blockade, inhibiting semantic understanding despite successful text recognition. To evaluate this threat, we constructed SmuggleBench, the first comprehensive benchmark comprising 1,700 adversarial smuggling attack instances. Evaluations on SmuggleBench reveal that both proprietary (e.g., GPT-5) and open-source (e.g., Qwen3-VL) state-of-the-art models are vulnerable to this threat, producing Attack Success Rates (ASR) exceeding 90%. By analyzing the vulnerability through the lenses of perception and reasoning, we identify three root causes: the limited capabilities of vision encoders, the robustness gap in OCR, and the scarcity of domain-specific adversarial examples. We conduct a preliminary exploration of mitigation strategies, investigating the potential of test-time scaling (via CoT) and adversarial training (via SFT) to mitigate this threat. Our code is publicly available at https://github.com/zhihengli-casia/smugglebench.
Beyond Semantic Search: Towards Referential Anchoring in Composed Image Retrieval
Apr 07, 2026Composed Image Retrieval (CIR) has demonstrated significant potential by enabling flexible multimodal queries that combine a reference image and modification text. However, CIR inherently prioritizes semantic matching, struggling to reliably retrieve a user-specified instance across contexts. In practice, emphasizing concrete instance fidelity over broad semantics is often more consequential. In this work, we propose Object-Anchored Composed Image Retrieval (OACIR), a novel fine-grained retrieval task that mandates strict instance-level consistency. To advance research on this task, we construct OACIRR (OACIR on Real-world images), the first large-scale, multi-domain benchmark comprising over 160K quadruples and four challenging candidate galleries enriched with hard-negative instance distractors. Each quadruple augments the compositional query with a bounding box that visually anchors the object in the reference image, providing a precise and flexible way to ensure instance preservation. To address the OACIR task, we propose AdaFocal, a framework featuring a Context-Aware Attention Modulator that adaptively intensifies attention within the specified instance region, dynamically balancing focus between the anchored instance and the broader compositional context. Extensive experiments demonstrate that AdaFocal substantially outperforms existing compositional retrieval models, particularly in maintaining instance-level fidelity, thereby establishing a robust baseline for this challenging task while opening new directions for more flexible, instance-aware retrieval systems.
MMhops-R1: Multimodal Multi-hop Reasoning
Dec 16, 2025


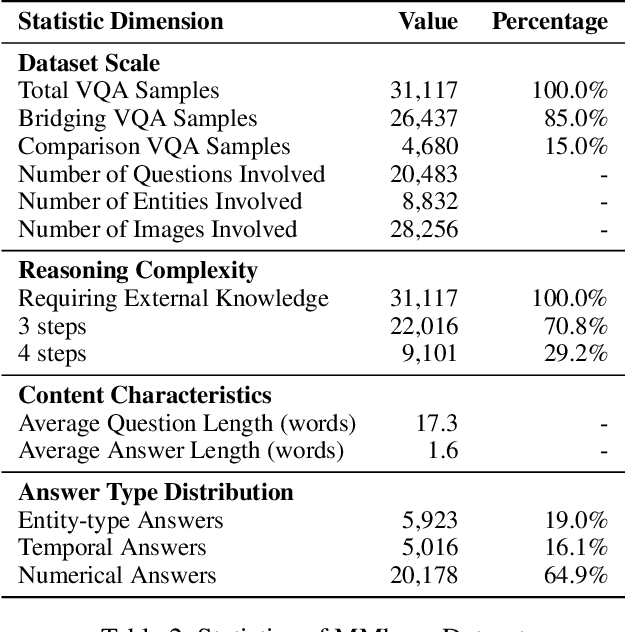
The ability to perform multi-modal multi-hop reasoning by iteratively integrating information across various modalities and external knowledge is critical for addressing complex real-world challenges. However, existing Multi-modal Large Language Models (MLLMs) are predominantly limited to single-step reasoning, as existing benchmarks lack the complexity needed to evaluate and drive multi-hop abilities. To bridge this gap, we introduce MMhops, a novel, large-scale benchmark designed to systematically evaluate and foster multi-modal multi-hop reasoning. MMhops dataset comprises two challenging task formats, Bridging and Comparison, which necessitate that models dynamically construct complex reasoning chains by integrating external knowledge. To tackle the challenges posed by MMhops, we propose MMhops-R1, a novel multi-modal Retrieval-Augmented Generation (mRAG) framework for dynamic reasoning. Our framework utilizes reinforcement learning to optimize the model for autonomously planning reasoning paths, formulating targeted queries, and synthesizing multi-level information. Comprehensive experiments demonstrate that MMhops-R1 significantly outperforms strong baselines on MMhops, highlighting that dynamic planning and multi-modal knowledge integration are crucial for complex reasoning. Moreover, MMhops-R1 demonstrates strong generalization to tasks requiring fixed-hop reasoning, underscoring the robustness of our dynamic planning approach. In conclusion, our work contributes a challenging new benchmark and a powerful baseline model, and we will release the associated code, data, and weights to catalyze future research in this critical area.
From Macro to Micro: Benchmarking Microscopic Spatial Intelligence on Molecules via Vision-Language Models
Dec 12, 2025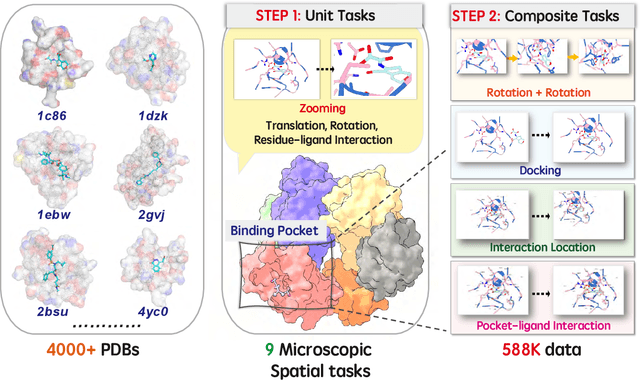
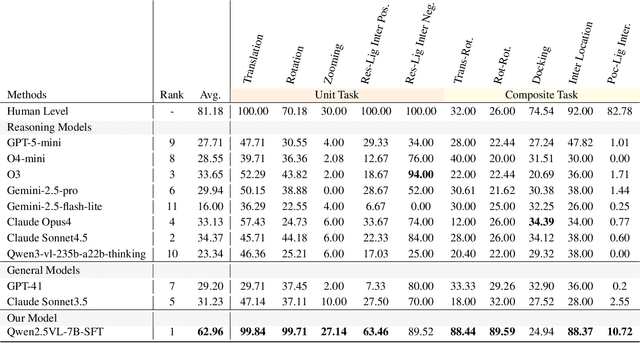
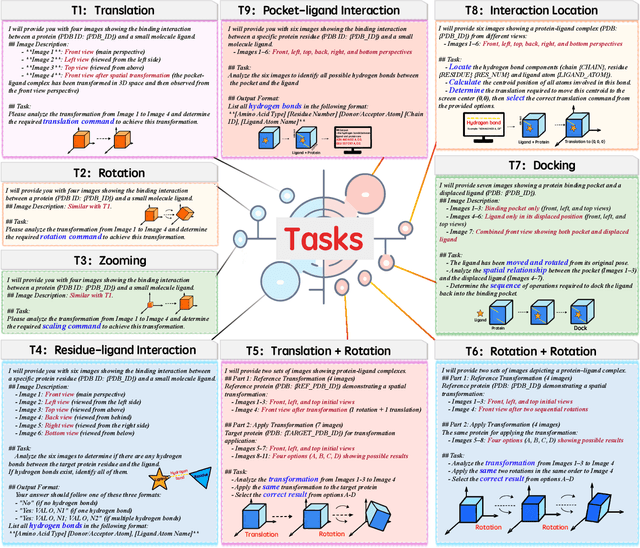
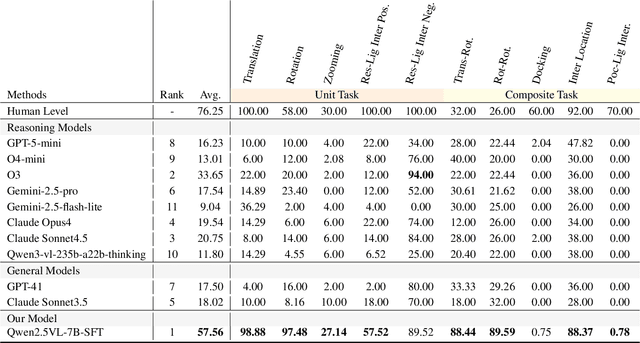
This paper introduces the concept of Microscopic Spatial Intelligence (MiSI), the capability to perceive and reason about the spatial relationships of invisible microscopic entities, which is fundamental to scientific discovery. To assess the potential of Vision-Language Models (VLMs) in this domain, we propose a systematic benchmark framework MiSI-Bench. This framework features over 163,000 question-answer pairs and 587,000 images derived from approximately 4,000 molecular structures, covering nine complementary tasks that evaluate abilities ranging from elementary spatial transformations to complex relational identifications. Experimental results reveal that current state-of-the-art VLMs perform significantly below human level on this benchmark. However, a fine-tuned 7B model demonstrates substantial potential, even surpassing humans in spatial transformation tasks, while its poor performance in scientifically-grounded tasks like hydrogen bond recognition underscores the necessity of integrating explicit domain knowledge for progress toward scientific AGI. The datasets are available at https://huggingface.co/datasets/zongzhao/MiSI-bench.
Are Large Language Models Chronically Online Surfers? A Dataset for Chinese Internet Meme Explanation
Oct 01, 2025Large language models (LLMs) are trained on vast amounts of text from the Internet, but do they truly understand the viral content that rapidly spreads online -- commonly known as memes? In this paper, we introduce CHIME, a dataset for CHinese Internet Meme Explanation. The dataset comprises popular phrase-based memes from the Chinese Internet, annotated with detailed information on their meaning, origin, example sentences, types, etc. To evaluate whether LLMs understand these memes, we designed two tasks. In the first task, we assessed the models' ability to explain a given meme, identify its origin, and generate appropriate example sentences. The results show that while LLMs can explain the meanings of some memes, their performance declines significantly for culturally and linguistically nuanced meme types. Additionally, they consistently struggle to provide accurate origins for the memes. In the second task, we created a set of multiple-choice questions (MCQs) requiring LLMs to select the most appropriate meme to fill in a blank within a contextual sentence. While the evaluated models were able to provide correct answers, their performance remains noticeably below human levels. We have made CHIME public and hope it will facilitate future research on computational meme understanding.
STAR-R1: Spatial TrAnsformation Reasoning by Reinforcing Multimodal LLMs
May 26, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities across diverse tasks, yet they lag significantly behind humans in spatial reasoning. We investigate this gap through Transformation-Driven Visual Reasoning (TVR), a challenging task requiring identification of object transformations across images under varying viewpoints. While traditional Supervised Fine-Tuning (SFT) fails to generate coherent reasoning paths in cross-view settings, sparse-reward Reinforcement Learning (RL) suffers from inefficient exploration and slow convergence. To address these limitations, we propose STAR-R1, a novel framework that integrates a single-stage RL paradigm with a fine-grained reward mechanism tailored for TVR. Specifically, STAR-R1 rewards partial correctness while penalizing excessive enumeration and passive inaction, enabling efficient exploration and precise reasoning. Comprehensive evaluations demonstrate that STAR-R1 achieves state-of-the-art performance across all 11 metrics, outperforming SFT by 23% in cross-view scenarios. Further analysis reveals STAR-R1's anthropomorphic behavior and highlights its unique ability to compare all objects for improving spatial reasoning. Our work provides critical insights in advancing the research of MLLMs and reasoning models. The codes, model weights, and data will be publicly available at https://github.com/zongzhao23/STAR-R1.
DetailFusion: A Dual-branch Framework with Detail Enhancement for Composed Image Retrieval
May 23, 2025Composed Image Retrieval (CIR) aims to retrieve target images from a gallery based on a reference image and modification text as a combined query. Recent approaches focus on balancing global information from two modalities and encode the query into a unified feature for retrieval. However, due to insufficient attention to fine-grained details, these coarse fusion methods often struggle with handling subtle visual alterations or intricate textual instructions. In this work, we propose DetailFusion, a novel dual-branch framework that effectively coordinates information across global and detailed granularities, thereby enabling detail-enhanced CIR. Our approach leverages atomic detail variation priors derived from an image editing dataset, supplemented by a detail-oriented optimization strategy to develop a Detail-oriented Inference Branch. Furthermore, we design an Adaptive Feature Compositor that dynamically fuses global and detailed features based on fine-grained information of each unique multimodal query. Extensive experiments and ablation analyses not only demonstrate that our method achieves state-of-the-art performance on both CIRR and FashionIQ datasets but also validate the effectiveness and cross-domain adaptability of detail enhancement for CIR.
STAR-R1: Spacial TrAnsformation Reasoning by Reinforcing Multimodal LLMs
May 21, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities across diverse tasks, yet they lag significantly behind humans in spatial reasoning. We investigate this gap through Transformation-Driven Visual Reasoning (TVR), a challenging task requiring identification of object transformations across images under varying viewpoints. While traditional Supervised Fine-Tuning (SFT) fails to generate coherent reasoning paths in cross-view settings, sparse-reward Reinforcement Learning (RL) suffers from inefficient exploration and slow convergence. To address these limitations, we propose STAR-R1, a novel framework that integrates a single-stage RL paradigm with a fine-grained reward mechanism tailored for TVR. Specifically, STAR-R1 rewards partial correctness while penalizing excessive enumeration and passive inaction, enabling efficient exploration and precise reasoning. Comprehensive evaluations demonstrate that STAR-R1 achieves state-of-the-art performance across all 11 metrics, outperforming SFT by 23% in cross-view scenarios. Further analysis reveals STAR-R1's anthropomorphic behavior and highlights its unique ability to compare all objects for improving spatial reasoning. Our work provides critical insights in advancing the research of MLLMs and reasoning models. The codes, model weights, and data will be publicly available at https://github.com/zongzhao23/STAR-R1.
iMOVE: Instance-Motion-Aware Video Understanding
Feb 18, 2025



Enhancing the fine-grained instance spatiotemporal motion perception capabilities of Video Large Language Models is crucial for improving their temporal and general video understanding. However, current models struggle to perceive detailed and complex instance motions. To address these challenges, we have made improvements from both data and model perspectives. In terms of data, we have meticulously curated iMOVE-IT, the first large-scale instance-motion-aware video instruction-tuning dataset. This dataset is enriched with comprehensive instance motion annotations and spatiotemporal mutual-supervision tasks, providing extensive training for the model's instance-motion-awareness. Building on this foundation, we introduce iMOVE, an instance-motion-aware video foundation model that utilizes Event-aware Spatiotemporal Efficient Modeling to retain informative instance spatiotemporal motion details while maintaining computational efficiency. It also incorporates Relative Spatiotemporal Position Tokens to ensure awareness of instance spatiotemporal positions. Evaluations indicate that iMOVE excels not only in video temporal understanding and general video understanding but also demonstrates significant advantages in long-term video understanding.
mR$^2$AG: Multimodal Retrieval-Reflection-Augmented Generation for Knowledge-Based VQA
Nov 22, 2024



Advanced Multimodal Large Language Models (MLLMs) struggle with recent Knowledge-based VQA tasks, such as INFOSEEK and Encyclopedic-VQA, due to their limited and frozen knowledge scope, often leading to ambiguous and inaccurate responses. Thus, multimodal Retrieval-Augmented Generation (mRAG) is naturally introduced to provide MLLMs with comprehensive and up-to-date knowledge, effectively expanding the knowledge scope. However, current mRAG methods have inherent drawbacks, including: 1) Performing retrieval even when external knowledge is not needed. 2) Lacking of identification of evidence that supports the query. 3) Increasing model complexity due to additional information filtering modules or rules. To address these shortcomings, we propose a novel generalized framework called \textbf{m}ultimodal \textbf{R}etrieval-\textbf{R}eflection-\textbf{A}ugmented \textbf{G}eneration (mR$^2$AG), which achieves adaptive retrieval and useful information localization to enable answers through two easy-to-implement reflection operations, preventing high model complexity. In mR$^2$AG, Retrieval-Reflection is designed to distinguish different user queries and avoids redundant retrieval calls, and Relevance-Reflection is introduced to guide the MLLM in locating beneficial evidence of the retrieved content and generating answers accordingly. In addition, mR$^2$AG can be integrated into any well-trained MLLM with efficient fine-tuning on the proposed mR$^2$AG Instruction-Tuning dataset (mR$^2$AG-IT). mR$^2$AG significantly outperforms state-of-the-art MLLMs (e.g., GPT-4v/o) and RAG-based MLLMs on INFOSEEK and Encyclopedic-VQA, while maintaining the exceptional capabilities of base MLLMs across a wide range of Visual-dependent tasks.