 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Macro to Micro: Benchmarking Microscopic Spatial Intelligence on Molecules via Vision-Language Models
Dec 12, 2025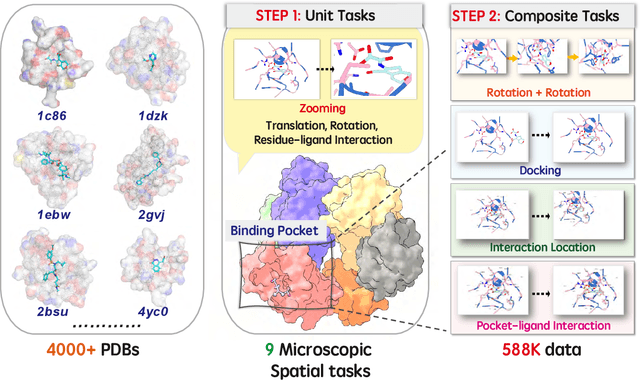
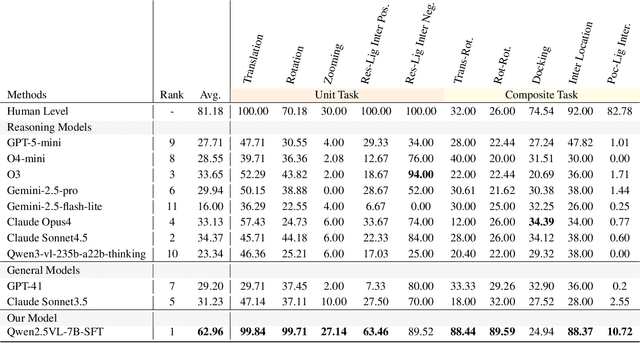
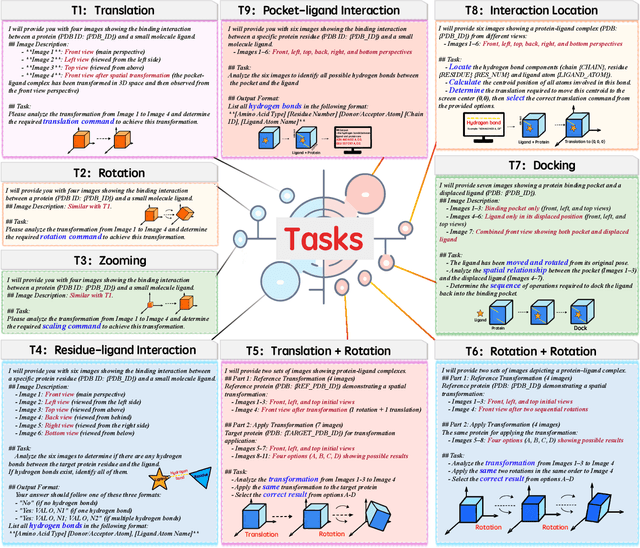
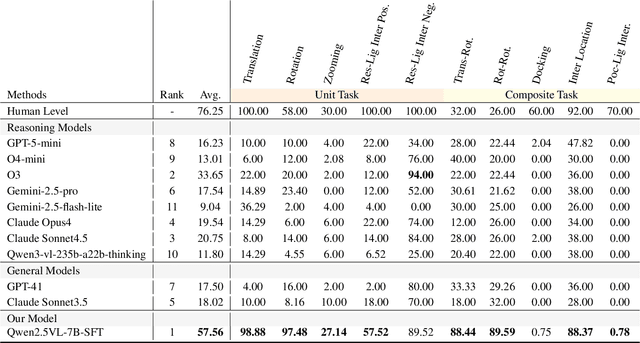
This paper introduces the concept of Microscopic Spatial Intelligence (MiSI), the capability to perceive and reason about the spatial relationships of invisible microscopic entities, which is fundamental to scientific discovery. To assess the potential of Vision-Language Models (VLMs) in this domain, we propose a systematic benchmark framework MiSI-Bench. This framework features over 163,000 question-answer pairs and 587,000 images derived from approximately 4,000 molecular structures, covering nine complementary tasks that evaluate abilities ranging from elementary spatial transformations to complex relational identifications. Experimental results reveal that current state-of-the-art VLMs perform significantly below human level on this benchmark. However, a fine-tuned 7B model demonstrates substantial potential, even surpassing humans in spatial transformation tasks, while its poor performance in scientifically-grounded tasks like hydrogen bond recognition underscores the necessity of integrating explicit domain knowledge for progress toward scientific AGI. The datasets are available at https://huggingface.co/datasets/zongzhao/MiSI-bench.
Attacking and Securing Community Detection: A Game-Theoretic Framework
Dec 12, 2025It has been demonstrated that adversarial graphs, i.e., graphs with imperceptible perturbations, can cause deep graph models to fail on classification tasks. In this work, we extend the concept of adversarial graphs to the community detection problem, which is more challenging. We propose novel attack and defense techniques for community detection problem, with the objective of hiding targeted individuals from detection models and enhancing the robustness of community detection models, respectively. These techniques have many applications in real-world scenarios, for example, protecting personal privacy in social networks and understanding camouflage patterns in transaction networks. To simulate interactive attack and defense behaviors, we further propose a game-theoretic framework, called CD-GAME. One player is a graph attacker, while the other player is a Rayleigh Quotient defender. The CD-GAME models the mutual influence and feedback mechanisms between the attacker and the defender, revealing the dynamic evolutionary process of the game. Both players dynamically update their strategies until they reach the Nash equilibrium. Extensive experiments demonstrate the effectiveness of our proposed attack and defense methods, and both outperform existing baselines by a significant margin. Furthermore, CD-GAME provides valuable insights for understanding interactive attack and defense scenarios in community detection problems. We found that in traditional single-step attack or defense, attacker tends to employ strategies that are most effective, but are easily detected and countered by defender. When the interactive game reaches a Nash equilibrium, attacker adopts more imperceptible strategies that can still achieve satisfactory attack effectiveness even after defense.
VL-Cogito: Progressive Curriculum Reinforcement Learning for Advanced Multimodal Reasoning
Jul 30, 2025



Reinforcement learning has proven its effectiveness in enhancing the reasoning capabilities of large language models. Recent research efforts have progressively extended this paradigm to multimodal reasoning tasks. Due to the inherent complexity and diversity of multimodal tasks, especially in semantic content and problem formulations, existing models often exhibit unstable performance across various domains and difficulty levels. To address these limitations, we propose VL-Cogito, an advanced multimodal reasoning model trained via a novel multi-stage Progressive Curriculum Reinforcement Learning (PCuRL) framework. PCuRL systematically guides the model through tasks of gradually increasing difficulty, substantially improving its reasoning abilities across diverse multimodal contexts. The framework introduces two key innovations: (1) an online difficulty soft weighting mechanism, dynamically adjusting training difficulty across successive RL training stages; and (2) a dynamic length reward mechanism, which encourages the model to adaptively regulate its reasoning path length according to task complexity, thus balancing reasoning efficiency with correctness. Experimental evaluations demonstrate that VL-Cogito consistently matches or surpasses existing reasoning-oriented models across mainstream multimodal benchmarks spanning mathematics, science, logic, and general understanding, validating the effectiveness of our approach.
DiffSpectra: Molecular Structure Elucidation from Spectra using Diffusion Models
Jul 09, 2025Molecular structure elucidation from spectra is a foundational problem in chemistry, with profound implications for compound identification, synthesis, and drug development. Traditional methods rely heavily on expert interpretation and lack scalability. Pioneering machine learning methods have introduced retrieval-based strategies, but their reliance on finite libraries limits generalization to novel molecules. Generative models offer a promising alternative, yet most adopt autoregressive SMILES-based architectures that overlook 3D geometry and struggle to integrate diverse spectral modalities. In this work, we present DiffSpectra, a generative framework that directly infers both 2D and 3D molecular structures from multi-modal spectral data using diffusion models. DiffSpectra formulates structure elucidation as a conditional generation process. Its denoising network is parameterized by Diffusion Molecule Transformer, an SE(3)-equivariant architecture that integrates topological and geometric information. Conditioning is provided by SpecFormer, a transformer-based spectral encoder that captures intra- and inter-spectral dependencies from multi-modal spectra. Extensive experiments demonstrate that DiffSpectra achieves high accuracy in structure elucidation, recovering exact structures with 16.01% top-1 accuracy and 96.86% top-20 accuracy through sampling. The model benefits significantly from 3D geometric modeling, SpecFormer pre-training, and multi-modal conditioning. These results highlight the effectiveness of spectrum-conditioned diffusion modeling in addressing the challenge of molecular structure elucidation. To our knowledge, DiffSpectra is the first framework to unify multi-modal spectral reasoning and joint 2D/3D generative modeling for de novo molecular structure elucidation.
ReasonMed: A 370K Multi-Agent Generated Dataset for Advancing Medical Reasoning
Jun 11, 2025Though reasoning-based large language models (LLMs) have excelled in mathematics and programming, their capabilities in knowledge-intensive medical question answering remain underexplored. To address this, we introduce ReasonMed, the largest medical reasoning dataset, comprising 370k high-quality examples distilled from 1.7 million initial reasoning paths generated by various LLMs. ReasonMed is constructed through a \textit{multi-agent verification and refinement process}, where we design an \textit{Error Refiner} to enhance the reasoning paths by identifying and correcting error-prone steps flagged by a verifier. Leveraging ReasonMed, we systematically investigate best practices for training medical reasoning models and find that combining detailed Chain-of-Thought (CoT) reasoning with concise answer summaries yields the most effective fine-tuning strategy. Based on this strategy, we train ReasonMed-7B, which sets a new benchmark for sub-10B models, outperforming the prior best by 4.17\% and even exceeding LLaMA3.1-70B on PubMedQA by 4.60\%.
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Jun 08, 2025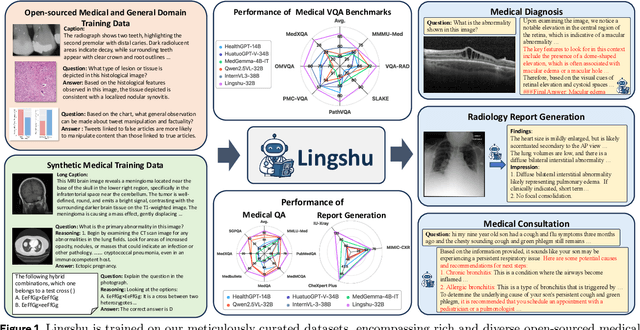
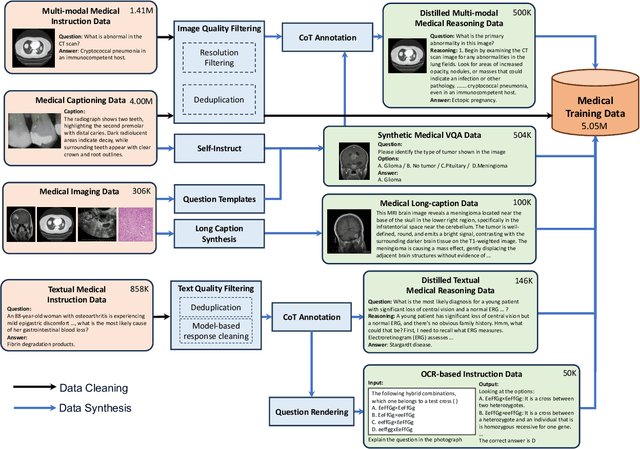

Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities in understanding common visual elements, largely due to their large-scale datasets and advanced training strategies. However, their effectiveness in medical applications remains limited due to the inherent discrepancies between data and tasks in medical scenarios and those in the general domain. Concretely, existing medical MLLMs face the following critical limitations: (1) limited coverage of medical knowledge beyond imaging, (2) heightened susceptibility to hallucinations due to suboptimal data curation processes, (3) lack of reasoning capabilities tailored for complex medical scenarios. To address these challenges, we first propose a comprehensive data curation procedure that (1) efficiently acquires rich medical knowledge data not only from medical imaging but also from extensive medical texts and general-domain data; and (2) synthesizes accurate medical captions, visual question answering (VQA), and reasoning samples. As a result, we build a multimodal dataset enriched with extensive medical knowledge. Building on the curated data, we introduce our medical-specialized MLLM: Lingshu. Lingshu undergoes multi-stage training to embed medical expertise and enhance its task-solving capabilities progressively. Besides, we preliminarily explore the potential of applying reinforcement learning with verifiable rewards paradigm to enhance Lingshu's medical reasoning ability. Additionally, we develop MedEvalKit, a unified evaluation framework that consolidates leading multimodal and textual medical benchmarks for standardized, fair, and efficient model assessment. We evaluate the performance of Lingshu on three fundamental medical tasks, multimodal QA, text-based QA, and medical report generation. The results show that Lingshu consistently outperforms the existing open-source multimodal models on most tasks ...
STAR-R1: Spatial TrAnsformation Reasoning by Reinforcing Multimodal LLMs
May 26, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities across diverse tasks, yet they lag significantly behind humans in spatial reasoning. We investigate this gap through Transformation-Driven Visual Reasoning (TVR), a challenging task requiring identification of object transformations across images under varying viewpoints. While traditional Supervised Fine-Tuning (SFT) fails to generate coherent reasoning paths in cross-view settings, sparse-reward Reinforcement Learning (RL) suffers from inefficient exploration and slow convergence. To address these limitations, we propose STAR-R1, a novel framework that integrates a single-stage RL paradigm with a fine-grained reward mechanism tailored for TVR. Specifically, STAR-R1 rewards partial correctness while penalizing excessive enumeration and passive inaction, enabling efficient exploration and precise reasoning. Comprehensive evaluations demonstrate that STAR-R1 achieves state-of-the-art performance across all 11 metrics, outperforming SFT by 23% in cross-view scenarios. Further analysis reveals STAR-R1's anthropomorphic behavior and highlights its unique ability to compare all objects for improving spatial reasoning. Our work provides critical insights in advancing the research of MLLMs and reasoning models. The codes, model weights, and data will be publicly available at https://github.com/zongzhao23/STAR-R1.
STAR-R1: Spacial TrAnsformation Reasoning by Reinforcing Multimodal LLMs
May 21, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities across diverse tasks, yet they lag significantly behind humans in spatial reasoning. We investigate this gap through Transformation-Driven Visual Reasoning (TVR), a challenging task requiring identification of object transformations across images under varying viewpoints. While traditional Supervised Fine-Tuning (SFT) fails to generate coherent reasoning paths in cross-view settings, sparse-reward Reinforcement Learning (RL) suffers from inefficient exploration and slow convergence. To address these limitations, we propose STAR-R1, a novel framework that integrates a single-stage RL paradigm with a fine-grained reward mechanism tailored for TVR. Specifically, STAR-R1 rewards partial correctness while penalizing excessive enumeration and passive inaction, enabling efficient exploration and precise reasoning. Comprehensive evaluations demonstrate that STAR-R1 achieves state-of-the-art performance across all 11 metrics, outperforming SFT by 23% in cross-view scenarios. Further analysis reveals STAR-R1's anthropomorphic behavior and highlights its unique ability to compare all objects for improving spatial reasoning. Our work provides critical insights in advancing the research of MLLMs and reasoning models. The codes, model weights, and data will be publicly available at https://github.com/zongzhao23/STAR-R1.
InversionGNN: A Dual Path Network for Multi-Property Molecular Optimization
Mar 03, 2025



Exploring chemical space to find novel molecules that simultaneously satisfy multiple properties is crucial in drug discovery. However, existing methods often struggle with trading off multiple properties due to the conflicting or correlated nature of chemical properties. To tackle this issue, we introduce InversionGNN framework, an effective yet sample-efficient dual-path graph neural network (GNN) for multi-objective drug discovery. In the direct prediction path of InversionGNN, we train the model for multi-property prediction to acquire knowledge of the optimal combination of functional groups. Then the learned chemical knowledge helps the inversion generation path to generate molecules with required properties. In order to decode the complex knowledge of multiple properties in the inversion path, we propose a gradient-based Pareto search method to balance conflicting properties and generate Pareto optimal molecules. Additionally, InversionGNN is able to search the full Pareto front approximately in discrete chemical space. Comprehensive experimental evaluations show that InversionGNN is both effective and sample-efficient in various discrete multi-objective settings including drug discovery.
A Survey of Graph Transformers: Architectures, Theories and Applications
Feb 23, 2025



Graph Transformers (GTs) have demonstrated a strong capability in modeling graph structures by addressing the intrinsic limitations of graph neural networks (GNNs), such as over-smoothing and over-squashing. Recent studies have proposed diverse architectures, enhanced explainability, and practical applications for Graph Transformers. In light of these rapid developments, we conduct a comprehensive review of Graph Transformers, covering aspects such as their architectures, theoretical foundations, and applications within this survey. We categorize the architecture of Graph Transformers according to their strategies for processing structural information, including graph tokenization, positional encoding, structure-aware attention and model ensemble. Furthermore, from the theoretical perspective, we examine the expressivity of Graph Transformers in various discussed architectures and contrast them with other advanced graph learning algorithms to discover the connections. Furthermore, we provide a summary of the practical applications where Graph Transformers have been utilized, such as molecule, protein, language, vision traffic, brain and material data. At the end of this survey, we will discuss the current challenges and prospective directions in Graph Transformers for potential future research.