 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMFlow: Disordered Materials Generation by Flow Matching
Feb 04, 2026The design of materials with tailored properties is crucial for technological progress. However, most deep generative models focus exclusively on perfectly ordered crystals, neglecting the important class of disordered materials. To address this gap, we introduce DMFlow, a generative framework specifically designed for disordered crystals. Our approach introduces a unified representation for ordered, Substitutionally Disordered (SD), and Positionally Disordered (PD) crystals, and employs a flow matching model to jointly generate all structural components. A key innovation is a Riemannian flow matching framework with spherical reparameterization, which ensures physically valid disorder weights on the probability simplex. The vector field is learned by a novel Graph Neural Network (GNN) that incorporates physical symmetries and a specialized message-passing scheme. Finally, a two-stage discretization procedure converts the continuous weights into multi-hot atomic assignments. To support research in this area, we release a benchmark containing SD, PD, and mixed structures curated from the Crystallography Open Database. Experiments on Crystal Structure Prediction (CSP) and De Novo Generation (DNG) tasks demonstrate that DMFlow significantly outperforms state-of-the-art baselines adapted from ordered crystal generation. We hope our work provides a foundation for the AI-driven discovery of disordered materials.
Equivariant Diffusion for Crystal Structure Prediction
Dec 08, 2025In addressing the challenge of Crystal Structure Prediction (CSP), symmetry-aware deep learning models, particularly diffusion models, have been extensively studied, which treat CSP as a conditional generation task. However, ensuring permutation, rotation, and periodic translation equivariance during diffusion process remains incompletely addressed. In this work, we propose EquiCSP, a novel equivariant diffusion-based generative model. We not only address the overlooked issue of lattice permutation equivariance in existing models, but also develop a unique noising algorithm that rigorously maintains periodic translation equivariance throughout both training and inference processes. Our experiments indicate that EquiCSP significantly surpasses existing models in terms of generating accurate structures and demonstrates faster convergence during the training process.
Materials Generation in the Era of Artificial Intelligence: A Comprehensive Survey
May 22, 2025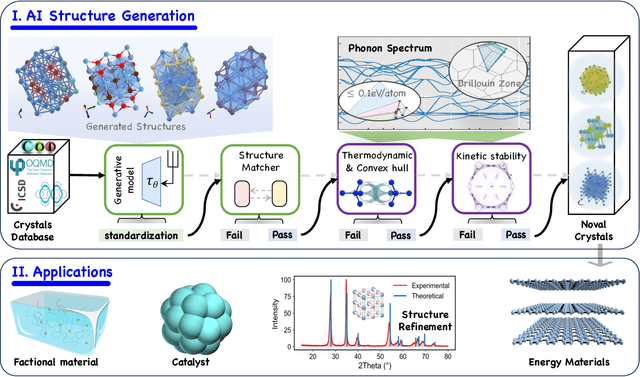

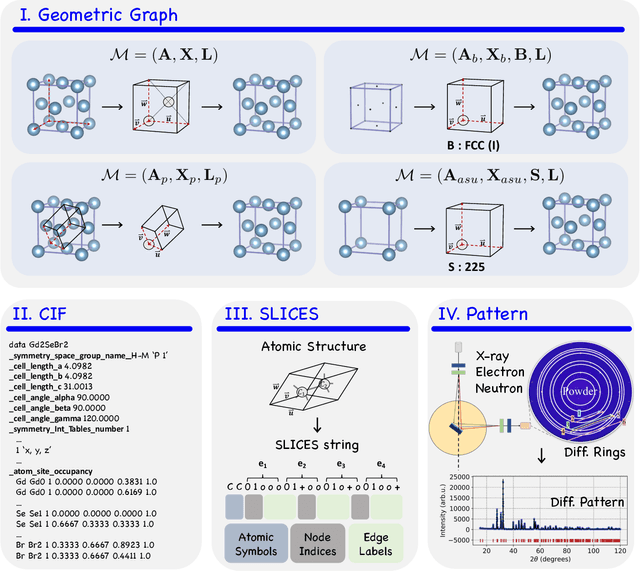
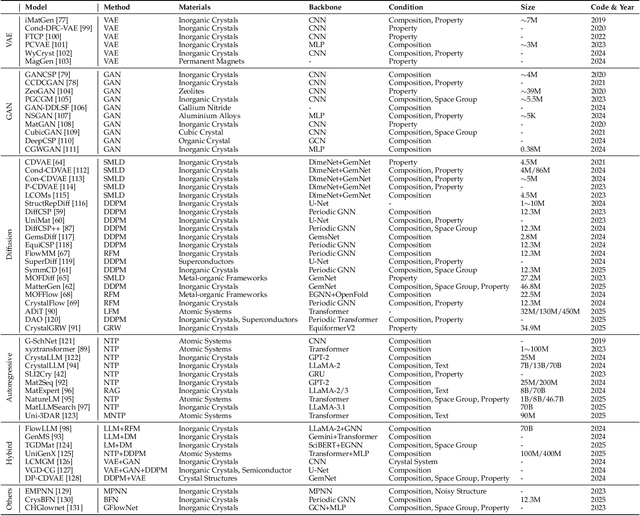
Materials are the foundation of modern society, underpinning advancements in energy, electronics, healthcare, transportation, and infrastructure. The ability to discover and design new materials with tailored properties is critical to solving some of the most pressing global challenges. In recent years, the growing availability of high-quality materials data combined with rapid advances in Artificial Intelligence (AI) has opened new opportunities for accelerating materials discovery. Data-driven generative models provide a powerful tool for materials design by directly create novel materials that satisfy predefined property requirements. Despite the proliferation of related work, there remains a notable lack of up-to-date and systematic surveys in this area. To fill this gap, this paper provides a comprehensive overview of recent progress in AI-driven materials generation. We first organize various types of materials and illustrate multiple representations of crystalline materials. We then provide a detailed summary and taxonomy of current AI-driven materials generation approaches. Furthermore, we discuss the common evaluation metrics and summarize open-source codes and benchmark datasets. Finally, we conclude with potential future directions and challenges in this fast-growing field. The related sources can be found at https://github.com/ZhixunLEE/Awesome-AI-for-Materials-Generation.
UniMoMo: Unified Generative Modeling of 3D Molecules for De Novo Binder Design
Mar 25, 2025The design of target-specific molecules such as small molecules, peptides, and antibodies is vital for biological research and drug discovery. Existing generative methods are restricted to single-domain molecules, failing to address versatile therapeutic needs or utilize cross-domain transferability to enhance model performance. In this paper, we introduce Unified generative Modeling of 3D Molecules (UniMoMo), the first framework capable of designing binders of multiple molecular domains using a single model. In particular, UniMoMo unifies the representations of different molecules as graphs of blocks, where each block corresponds to either a standard amino acid or a molecular fragment. Based on these unified representations, UniMoMo utilizes a geometric latent diffusion model for 3D molecular generation, featuring an iterative full-atom autoencoder to compress blocks into latent space points, followed by an E(3)-equivariant diffusion process. Extensive benchmarks across peptides, antibodies, and small molecules demonstrate the superiority of our unified framework over existing domain-specific models, highlighting the benefits of multi-domain training.
Siamese Foundation Models for Crystal Structure Prediction
Mar 13, 2025



Crystal Structure Prediction (CSP), which aims to generate stable crystal structures from compositions, represents a critical pathway for discovering novel materials. While structure prediction tasks in other domains, such as proteins, have seen remarkable progress, CSP remains a relatively underexplored area due to the more complex geometries inherent in crystal structures. In this paper, we propose Siamese foundation models specifically designed to address CSP. Our pretrain-finetune framework, named DAO, comprises two complementary foundation models: DAO-G for structure generation and DAO-P for energy prediction. Experiments on CSP benchmarks (MP-20 and MPTS-52) demonstrate that our DAO-G significantly surpasses state-of-the-art (SOTA) methods across all metrics. Extensive ablation studies further confirm that DAO-G excels in generating diverse polymorphic structures, and the dataset relaxation and energy guidance provided by DAO-P are essential for enhancing DAO-G's performance. When applied to three real-world superconductors ($\text{CsV}_3\text{Sb}_5$, $ \text{Zr}_{16}\text{Rh}_8\text{O}_4$ and $\text{Zr}_{16}\text{Pd}_8\text{O}_4$) that are known to be challenging to analyze, our foundation models achieve accurate critical temperature predictions and structure generations. For instance, on $\text{CsV}_3\text{Sb}_5$, DAO-G generates a structure close to the experimental one with an RMSE of 0.0085; DAO-P predicts the $T_c$ value with high accuracy (2.26 K vs. the ground-truth value of 2.30 K). In contrast, conventional DFT calculators like Quantum Espresso only successfully derive the structure of the first superconductor within an acceptable time, while the RMSE is nearly 8 times larger, and the computation speed is more than 1000 times slower. These compelling results collectively highlight the potential of our approach for advancing materials science research and development.
A Survey of Geometric Graph Neural Networks: Data Structures, Models and Applications
Mar 01, 2024Geometric graph is a special kind of graph with geometric features, which is vital to model many scientific problems. Unlike generic graphs, geometric graphs often exhibit physical symmetries of translations, rotations, and reflections, making them ineffectively processed by current Graph Neural Networks (GNNs). To tackle this issue, researchers proposed a variety of Geometric Graph Neural Networks equipped with invariant/equivariant properties to better characterize the geometry and topology of geometric graphs. Given the current progress in this field, it is imperative to conduct a comprehensive survey of data structures, models, and applications related to geometric GNNs. In this paper, based on the necessary but concise mathematical preliminaries, we provide a unified view of existing models from the geometric message passing perspective. Additionally, we summarize the applications as well as the related datasets to facilitate later research for methodology development and experimental evaluation. We also discuss the challenges and future potential directions of Geometric GNNs at the end of this survey.
Equivariant Pretrained Transformer for Unified Geometric Learning on Multi-Domain 3D Molecules
Feb 20, 2024Pretraining on a large number of unlabeled 3D molecules has showcased superiority in various scientific applications. However, prior efforts typically focus on pretraining models on a specific domain, either proteins or small molecules, missing the opportunity to leverage the cross-domain knowledge. To mitigate this gap, we introduce Equivariant Pretrained Transformer (EPT), a novel pretraining framework designed to harmonize the geometric learning of small molecules and proteins. To be specific, EPT unifies the geometric modeling of multi-domain molecules via the block-enhanced representation that can attend a broader context of each atom. Upon transformer framework, EPT is further enhanced with E(3) equivariance to facilitate the accurate representation of 3D structures. Another key innovation of EPT is its block-level pretraining task, which allows for joint pretraining on datasets comprising both small molecules and proteins. Experimental evaluations on a diverse group of benchmarks, including ligand binding affinity prediction, molecular property prediction, and protein property prediction, show that EPT significantly outperforms previous SOTA methods for affinity prediction, and achieves the best or comparable performance with existing domain-specific pretraining models for other tasks.
Space Group Constrained Crystal Generation
Feb 06, 2024



Crystals are the foundation of numerous scientific and industrial applications. While various learning-based approaches have been proposed for crystal generation, existing methods seldom consider the space group constraint which is crucial in describing the geometry of crystals and closely relevant to many desirable properties. However, considering space group constraint is challenging owing to its diverse and nontrivial forms. In this paper, we reduce the space group constraint into an equivalent formulation that is more tractable to be handcrafted into the generation process. In particular, we translate the space group constraint into two parts: the basis constraint of the invariant logarithmic space of the lattice matrix and the Wyckoff position constraint of the fractional coordinates. Upon the derived constraints, we then propose DiffCSP++, a novel diffusion model that has enhanced a previous work DiffCSP by further taking space group constraint into account. Experiments on several popular datasets verify the benefit of the involvement of the space group constraint, and show that our DiffCSP++ achieves promising performance on crystal structure prediction, ab initio crystal generation and controllable generation with customized space groups.
3D Equivariant Molecular Graph Pretraining
Jul 20, 2022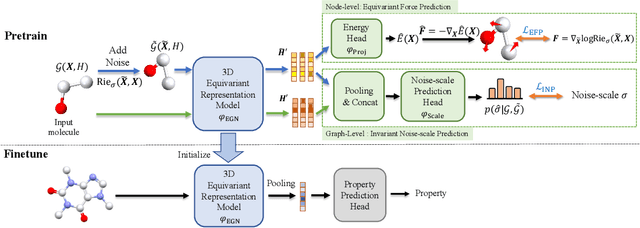
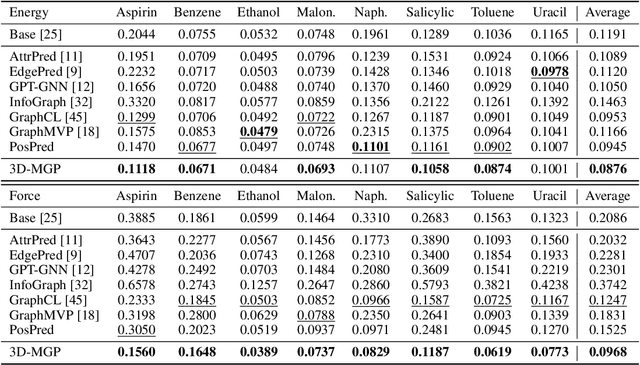
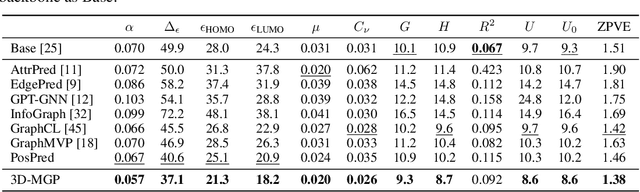
Pretraining molecular representation models without labels is fundamental to various applications. Conventional methods mainly process 2D molecular graphs and focus solely on 2D tasks, making their pretrained models incapable of characterizing 3D geometry and thus defective for downstream 3D tasks. In this work, we tackle 3D molecular pretraining in a complete and novel sense. In particular, we first propose to adopt an equivariant energy-based model as the backbone for pretraining, which enjoys the merit of fulfilling the symmetry of 3D space. Then we develop a node-level pretraining loss for force prediction, where we further exploit the Riemann-Gaussian distribution to ensure the loss to be E(3)-invariant, enabling more robustness. Moreover, a graph-level noise scale prediction task is also leveraged to further promote the eventual performance. We evaluate our model pretrained from a large-scale 3D dataset GEOM-QM9 on two challenging 3D benchmarks: MD17 and QM9. The experimental results support the better efficacy of our method against current state-of-the-art pretraining approaches, and verify the validity of our design for each proposed component.
Alternated Training with Synthetic and Authentic Data for Neural Machine Translation
Jun 16, 2021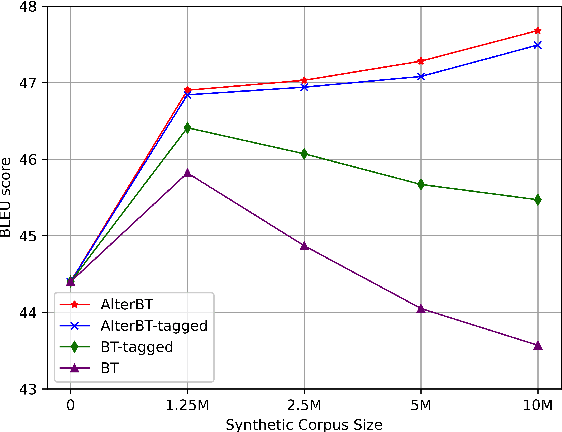
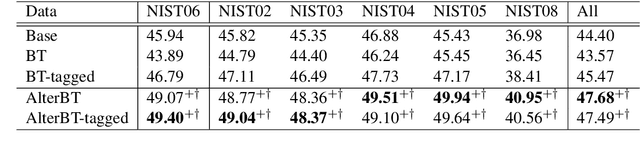
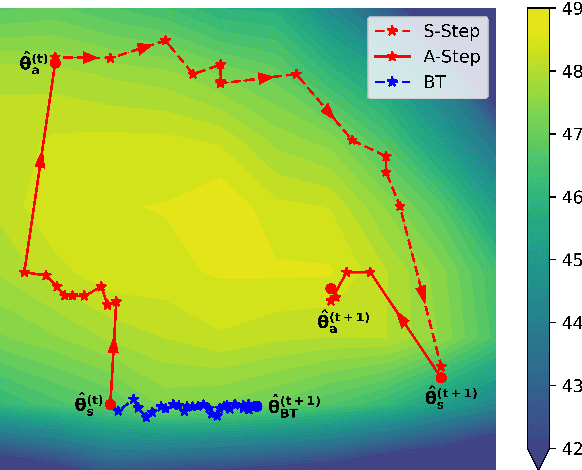
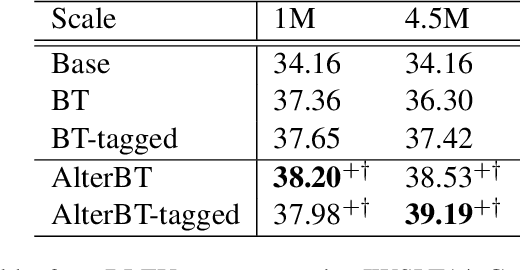
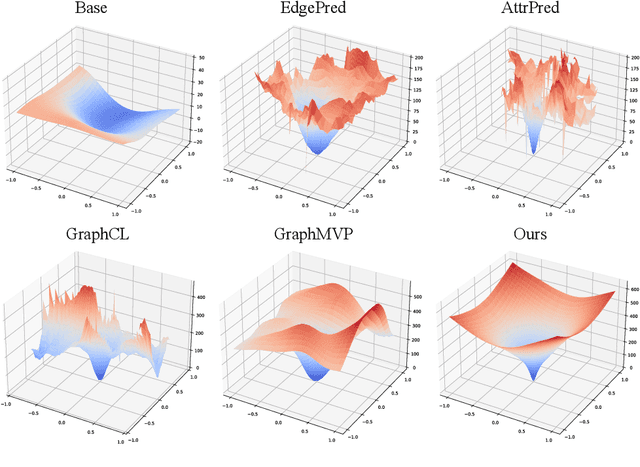
While synthetic bilingual corpora have demonstrated their effectiveness in low-resource neural machine translation (NMT), adding more synthetic data often deteriorates translation performance. In this work, we propose alternated training with synthetic and authentic data for NMT. The basic idea is to alternate synthetic and authentic corpora iteratively during training. Compared with previous work, we introduce authentic data as guidance to prevent the training of NMT models from being disturbed by noisy synthetic data. Experiments on Chinese-English and German-English translation tasks show that our approach improves the performance over several strong baselines. We visualize the BLEU landscape to further investigate the role of authentic and synthetic data during alternated training. From the visualization, we find that authentic data helps to direct the NMT model parameters towards points with higher BLEU scores and leads to consistent translation performance improvement.