 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Fusion of Large Atomic and Language Models to Accelerate Materials Discovery
Apr 26, 2026The discovery of novel materials is critical for global energy and quantum technology transitions. While deep learning has fundamentally reshaped this landscape, existing predictive or generative models typically operate in isolation, lacking the autonomous orchestration required to execute the full discovery process. Here we present ElementsClaw, an agentic framework for materials discovery that synergizes Large Atomic Models (LAMs) with Large Language Models (LLMs). In response to varied human requirements, ElementsClaw dynamically orchestrates a suite of LAM tools finetuned from our proposed model Elements for atomic-scale numerical computation, while leveraging LLMs for high-level semantic reasoning. This shift moves AI-driven materials science from isolated processes toward integrated and human interactive discovery. In the demanding domain of superconductors, our agentic system guides the experimental synthesis of four new superconductors, including Zr3ScRe8 with a transition temperature of 6.8 K and HfZrRe4 at 6.7 K. At scale, ElementsClaw screens more than 2.4 million stable crystals within only 28 GPU hours, identifying 68,000 high-confidence superconducting candidates and vastly expanding the known superconducting space. These results demonstrate how our agent accelerates materials discovery with high physical fidelity.
Lingshu-Cell: A generative cellular world model for transcriptome modeling toward virtual cells
Mar 26, 2026Modeling cellular states and predicting their responses to perturbations are central challenges in computational biology and the development of virtual cells. Existing foundation models for single-cell transcriptomics provide powerful static representations, but they do not explicitly model the distribution of cellular states for generative simulation. Here, we introduce Lingshu-Cell, a masked discrete diffusion model that learns transcriptomic state distributions and supports conditional simulation under perturbation. By operating directly in a discrete token space that is compatible with the sparse, non-sequential nature of single-cell transcriptomic data, Lingshu-Cell captures complex transcriptome-wide expression dependencies across approximately 18,000 genes without relying on prior gene selection, such as filtering by high variability or ranking by expression level. Across diverse tissues and species, Lingshu-Cell accurately reproduces transcriptomic distributions, marker-gene expression patterns and cell-subtype proportions, demonstrating its ability to capture complex cellular heterogeneity. Moreover, by jointly embedding cell type or donor identity with perturbation, Lingshu-Cell can predict whole-transcriptome expression changes for novel combinations of identity and perturbation. It achieves leading performance on the Virtual Cell Challenge H1 genetic perturbation benchmark and in predicting cytokine-induced responses in human PBMCs. Together, these results establish Lingshu-Cell as a flexible cellular world model for in silico simulation of cell states and perturbation responses, laying the foundation for a new paradigm in biological discovery and perturbation screening.
RynnBrain: Open Embodied Foundation Models
Feb 13, 2026Despite rapid progress in multimodal foundation models, embodied intelligence community still lacks a unified, physically grounded foundation model that integrates perception, reasoning, and planning within real-world spatial-temporal dynamics. We introduce RynnBrain, an open-source spatiotemporal foundation model for embodied intelligence. RynnBrain strengthens four core capabilities in a unified framework: comprehensive egocentric understanding, diverse spatiotemporal localization, physically grounded reasoning, and physics-aware planning. The RynnBrain family comprises three foundation model scales (2B, 8B, and 30B-A3B MoE) and four post-trained variants tailored for downstream embodied tasks (i.e., RynnBrain-Nav, RynnBrain-Plan, and RynnBrain-VLA) or complex spatial reasoning tasks (i.e., RynnBrain-CoP). In terms of extensive evaluations on 20 embodied benchmarks and 8 general vision understanding benchmarks, our RynnBrain foundation models largely outperform existing embodied foundation models by a significant margin. The post-trained model suite further substantiates two key potentials of the RynnBrain foundation model: (i) enabling physically grounded reasoning and planning, and (ii) serving as a strong pretrained backbone that can be efficiently adapted to diverse embodied tasks.
ParaFormer: A Generalized PageRank Graph Transformer for Graph Representation Learning
Dec 16, 2025Graph Transformers (GTs) have emerged as a promising graph learning tool, leveraging their all-pair connected property to effectively capture global information. To address the over-smoothing problem in deep GNNs, global attention was initially introduced, eliminating the necessity for using deep GNNs. However, through empirical and theoretical analysis, we verify that the introduced global attention exhibits severe over-smoothing, causing node representations to become indistinguishable due to its inherent low-pass filtering. This effect is even stronger than that observed in GNNs. To mitigate this, we propose PageRank Transformer (ParaFormer), which features a PageRank-enhanced attention module designed to mimic the behavior of deep Transformers. We theoretically and empirically demonstrate that ParaFormer mitigates over-smoothing by functioning as an adaptive-pass filter. Experiments show that ParaFormer achieves consistent performance improvements across both node classification and graph classification tasks on 11 datasets ranging from thousands to millions of nodes, validating its efficacy. The supplementary material, including code and appendix, can be found in https://github.com/chaohaoyuan/ParaFormer.
From Macro to Micro: Benchmarking Microscopic Spatial Intelligence on Molecules via Vision-Language Models
Dec 12, 2025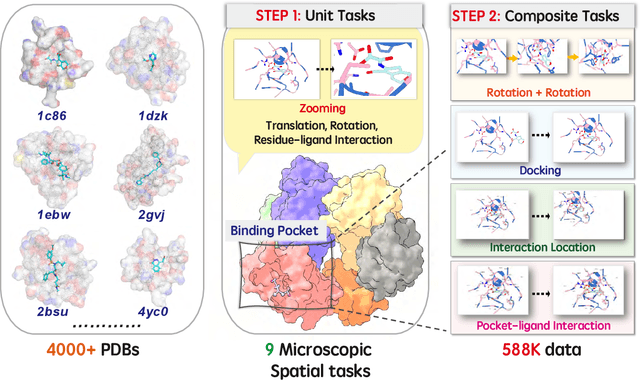
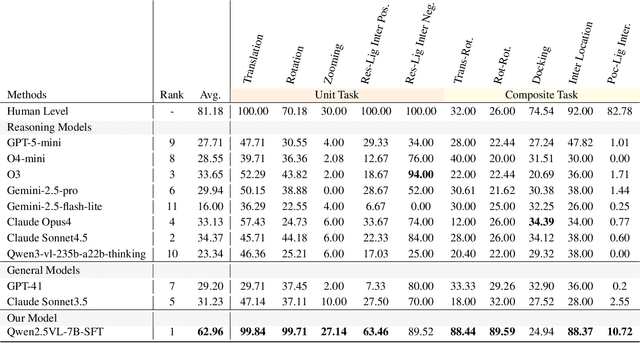
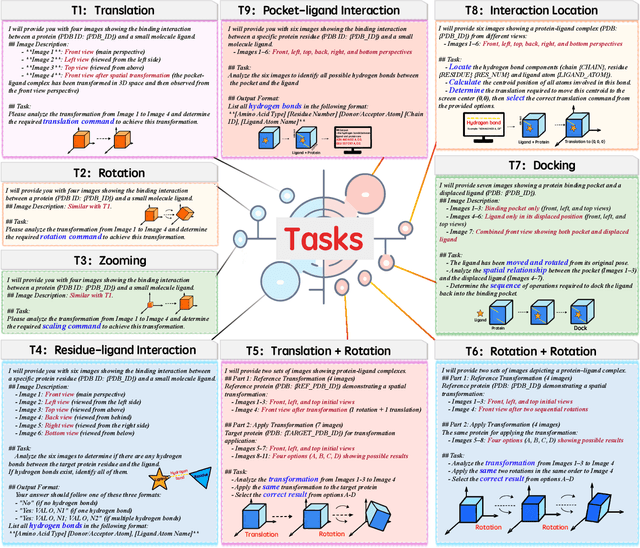
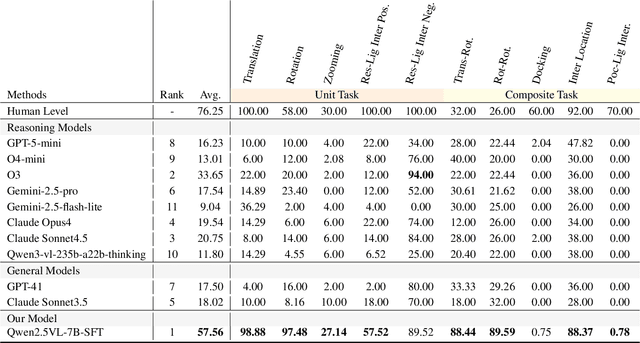
This paper introduces the concept of Microscopic Spatial Intelligence (MiSI), the capability to perceive and reason about the spatial relationships of invisible microscopic entities, which is fundamental to scientific discovery. To assess the potential of Vision-Language Models (VLMs) in this domain, we propose a systematic benchmark framework MiSI-Bench. This framework features over 163,000 question-answer pairs and 587,000 images derived from approximately 4,000 molecular structures, covering nine complementary tasks that evaluate abilities ranging from elementary spatial transformations to complex relational identifications. Experimental results reveal that current state-of-the-art VLMs perform significantly below human level on this benchmark. However, a fine-tuned 7B model demonstrates substantial potential, even surpassing humans in spatial transformation tasks, while its poor performance in scientifically-grounded tasks like hydrogen bond recognition underscores the necessity of integrating explicit domain knowledge for progress toward scientific AGI. The datasets are available at https://huggingface.co/datasets/zongzhao/MiSI-bench.
RoboSVG: A Unified Framework for Interactive SVG Generation with Multi-modal Guidance
Oct 26, 2025

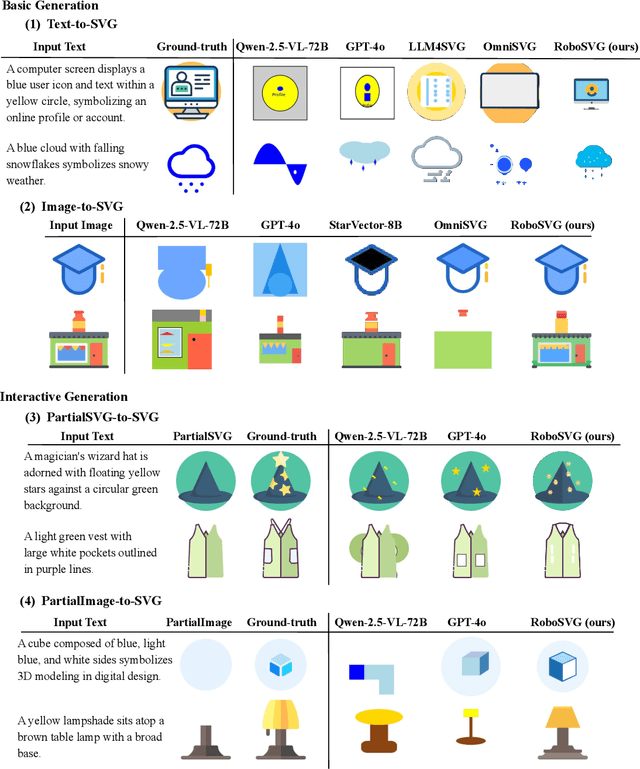

Scalable Vector Graphics (SVGs) are fundamental to digital design and robot control, encoding not only visual structure but also motion paths in interactive drawings. In this work, we introduce RoboSVG, a unified multimodal framework for generating interactive SVGs guided by textual, visual, and numerical signals. Given an input query, the RoboSVG model first produces multimodal guidance, then synthesizes candidate SVGs through dedicated generation modules, and finally refines them under numerical guidance to yield high-quality outputs. To support this framework, we construct RoboDraw, a large-scale dataset of one million examples, each pairing an SVG generation condition (e.g., text, image, and partial SVG) with its corresponding ground-truth SVG code. RoboDraw dataset enables systematic study of four tasks, including basic generation (Text-to-SVG, Image-to-SVG) and interactive generation (PartialSVG-to-SVG, PartialImage-to-SVG). Extensive experiments demonstrate that RoboSVG achieves superior query compliance and visual fidelity across tasks, establishing a new state of the art in versatile SVG generation. The dataset and source code of this project will be publicly available soon.
GP3: A 3D Geometry-Aware Policy with Multi-View Images for Robotic Manipulation
Sep 19, 2025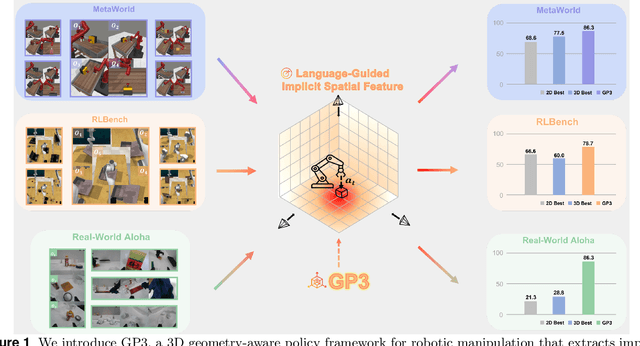



Effective robotic manipulation relies on a precise understanding of 3D scene geometry, and one of the most straightforward ways to acquire such geometry is through multi-view observations. Motivated by this, we present GP3 -- a 3D geometry-aware robotic manipulation policy that leverages multi-view input. GP3 employs a spatial encoder to infer dense spatial features from RGB observations, which enable the estimation of depth and camera parameters, leading to a compact yet expressive 3D scene representation tailored for manipulation. This representation is fused with language instructions and translated into continuous actions via a lightweight policy head. Comprehensive experiments demonstrate that GP3 consistently outperforms state-of-the-art methods on simulated benchmarks. Furthermore, GP3 transfers effectively to real-world robots without depth sensors or pre-mapped environments, requiring only minimal fine-tuning. These results highlight GP3 as a practical, sensor-agnostic solution for geometry-aware robotic manipulation.
RynnVLA-001: Using Human Demonstrations to Improve Robot Manipulation
Sep 18, 2025This paper presents RynnVLA-001, a vision-language-action(VLA) model built upon large-scale video generative pretraining from human demonstrations. We propose a novel two-stage pretraining methodology. The first stage, Ego-Centric Video Generative Pretraining, trains an Image-to-Video model on 12M ego-centric manipulation videos to predict future frames conditioned on an initial frame and a language instruction. The second stage, Human-Centric Trajectory-Aware Modeling, extends this by jointly predicting future keypoint trajectories, thereby effectively bridging visual frame prediction with action prediction. Furthermore, to enhance action representation, we propose ActionVAE, a variational autoencoder that compresses sequences of actions into compact latent embeddings, reducing the complexity of the VLA output space. When finetuned on the same downstream robotics datasets, RynnVLA-001 achieves superior performance over state-of-the-art baselines, demonstrating that the proposed pretraining strategy provides a more effective initialization for VLA models.
RynnEC: Bringing MLLMs into Embodied World
Aug 19, 2025We introduce RynnEC, a video multimodal large language model designed for embodied cognition. Built upon a general-purpose vision-language foundation model, RynnEC incorporates a region encoder and a mask decoder, enabling flexible region-level video interaction. Despite its compact architecture, RynnEC achieves state-of-the-art performance in object property understanding, object segmentation, and spatial reasoning. Conceptually, it offers a region-centric video paradigm for the brain of embodied agents, providing fine-grained perception of the physical world and enabling more precise interactions. To mitigate the scarcity of annotated 3D datasets, we propose an egocentric video based pipeline for generating embodied cognition data. Furthermore, we introduce RynnEC-Bench, a region-centered benchmark for evaluating embodied cognitive capabilities. We anticipate that RynnEC will advance the development of general-purpose cognitive cores for embodied agents and facilitate generalization across diverse embodied tasks. The code, model checkpoints, and benchmark are available at: https://github.com/alibaba-damo-academy/RynnEC
Towards Affordance-Aware Robotic Dexterous Grasping with Human-like Priors
Aug 12, 2025A dexterous hand capable of generalizable grasping objects is fundamental for the development of general-purpose embodied AI. However, previous methods focus narrowly on low-level grasp stability metrics, neglecting affordance-aware positioning and human-like poses which are crucial for downstream manipulation. To address these limitations, we propose AffordDex, a novel framework with two-stage training that learns a universal grasping policy with an inherent understanding of both motion priors and object affordances. In the first stage, a trajectory imitator is pre-trained on a large corpus of human hand motions to instill a strong prior for natural movement. In the second stage, a residual module is trained to adapt these general human-like motions to specific object instances. This refinement is critically guided by two components: our Negative Affordance-aware Segmentation (NAA) module, which identifies functionally inappropriate contact regions, and a privileged teacher-student distillation process that ensures the final vision-based policy is highly successful. Extensive experiments demonstrate that AffordDex not only achieves universal dexterous grasping but also remains remarkably human-like in posture and functionally appropriate in contact location. As a result, AffordDex significantly outperforms state-of-the-art baselines across seen objects, unseen instances, and even entirely novel categories.