 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware Multi-Expert Architecture For Lifelong Deep Learning
Dec 12, 2025Lifelong deep learning (LDL) trains neural networks to learn sequentially across tasks while preserving prior knowledge. We propose Task-Aware Multi-Expert (TAME), a continual learning algorithm that leverages task similarity to guide expert selection and knowledge transfer. TAME maintains a pool of pretrained neural networks and activates the most relevant expert for each new task. A shared dense layer integrates features from the chosen expert to generate predictions. To reduce catastrophic forgetting, TAME uses a replay buffer that stores representative samples and embeddings from previous tasks and reuses them during training. An attention mechanism further prioritizes the most relevant stored information for each prediction. Together, these components allow TAME to adapt flexibly while retaining important knowledge across evolving task sequences. Experiments on binary classification tasks derived from CIFAR-100 show that TAME improves accuracy on new tasks while sustaining performance on earlier ones, highlighting its effectiveness in balancing adaptation and retention in lifelong learning settings.
RESTRAIN: From Spurious Votes to Signals -- Self-Driven RL with Self-Penalization
Oct 02, 2025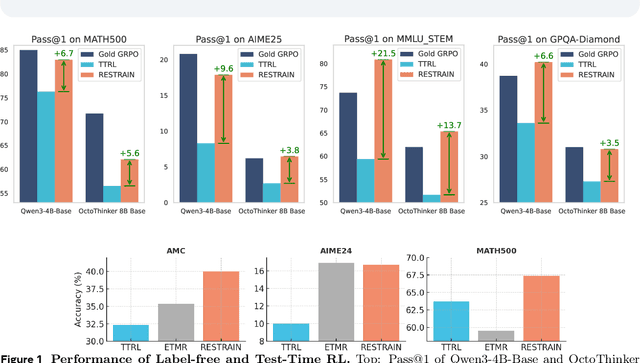
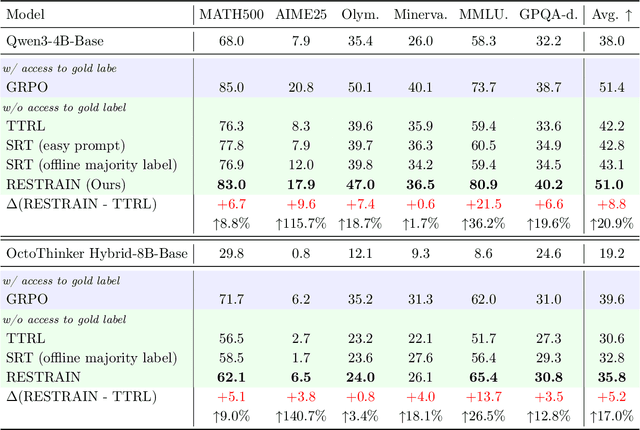
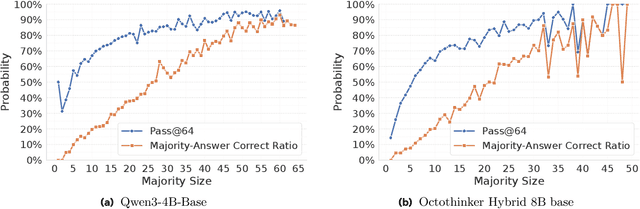
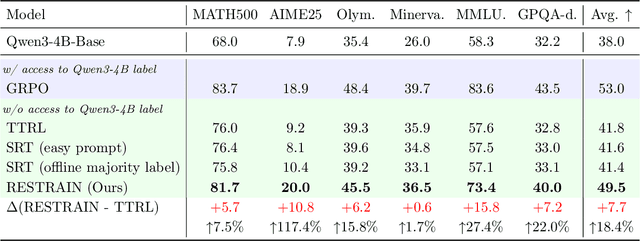
Reinforcement learning with human-annotated data has boosted chain-of-thought reasoning in large reasoning models, but these gains come at high costs in labeled data while faltering on harder tasks. A natural next step is experience-driven learning, where models improve without curated labels by adapting to unlabeled data. We introduce RESTRAIN (REinforcement learning with Self-restraint), a self-penalizing RL framework that converts the absence of gold labels into a useful learning signal. Instead of overcommitting to spurious majority votes, RESTRAIN exploits signals from the model's entire answer distribution: penalizing overconfident rollouts and low-consistency examples while preserving promising reasoning chains. The self-penalization mechanism integrates seamlessly into policy optimization methods such as GRPO, enabling continual self-improvement without supervision. On challenging reasoning benchmarks, RESTRAIN delivers large gains using only unlabeled data. With Qwen3-4B-Base and OctoThinker Hybrid-8B-Base, it improves Pass@1 by up to +140.7 percent on AIME25, +36.2 percent on MMLU_STEM, and +19.6 percent on GPQA-Diamond, nearly matching gold-label training while using no gold labels. These results demonstrate that RESTRAIN establishes a scalable path toward stronger reasoning without gold labels.
Omni-LIVO: Robust RGB-Colored Multi-Camera Visual-Inertial-LiDAR Odometry via Photometric Migration and ESIKF Fusion
Sep 19, 2025



Wide field-of-view (FoV) LiDAR sensors provide dense geometry across large environments, but most existing LiDAR-inertial-visual odometry (LIVO) systems rely on a single camera, leading to limited spatial coverage and degraded robustness. We present Omni-LIVO, the first tightly coupled multi-camera LIVO system that bridges the FoV mismatch between wide-angle LiDAR and conventional cameras. Omni-LIVO introduces a Cross-View direct tracking strategy that maintains photometric consistency across non-overlapping views, and extends the Error-State Iterated Kalman Filter (ESIKF) with multi-view updates and adaptive covariance weighting. The system is evaluated on public benchmarks and our custom dataset, showing improved accuracy and robustness over state-of-the-art LIVO, LIO, and visual-inertial baselines. Code and dataset will be released upon publication.
VL-Cogito: Progressive Curriculum Reinforcement Learning for Advanced Multimodal Reasoning
Jul 30, 2025



Reinforcement learning has proven its effectiveness in enhancing the reasoning capabilities of large language models. Recent research efforts have progressively extended this paradigm to multimodal reasoning tasks. Due to the inherent complexity and diversity of multimodal tasks, especially in semantic content and problem formulations, existing models often exhibit unstable performance across various domains and difficulty levels. To address these limitations, we propose VL-Cogito, an advanced multimodal reasoning model trained via a novel multi-stage Progressive Curriculum Reinforcement Learning (PCuRL) framework. PCuRL systematically guides the model through tasks of gradually increasing difficulty, substantially improving its reasoning abilities across diverse multimodal contexts. The framework introduces two key innovations: (1) an online difficulty soft weighting mechanism, dynamically adjusting training difficulty across successive RL training stages; and (2) a dynamic length reward mechanism, which encourages the model to adaptively regulate its reasoning path length according to task complexity, thus balancing reasoning efficiency with correctness. Experimental evaluations demonstrate that VL-Cogito consistently matches or surpasses existing reasoning-oriented models across mainstream multimodal benchmarks spanning mathematics, science, logic, and general understanding, validating the effectiveness of our approach.
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Jun 08, 2025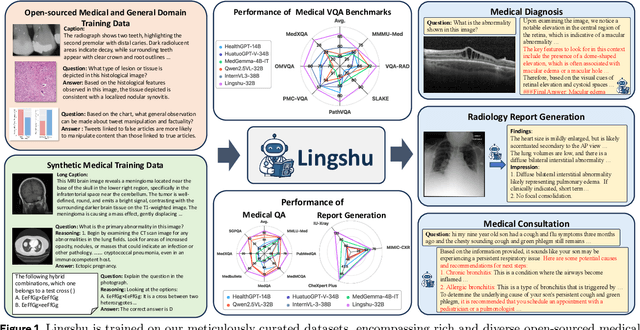
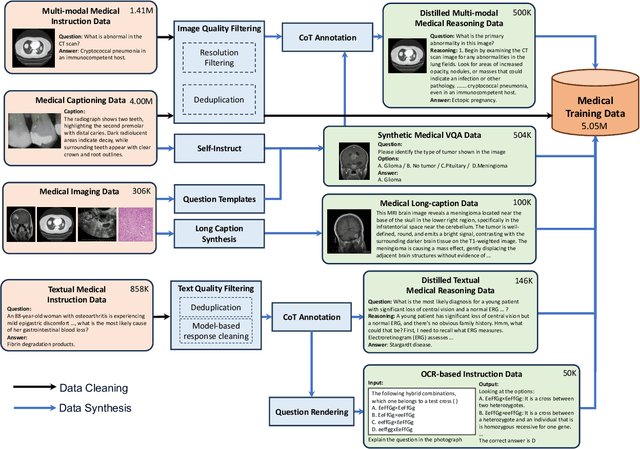

Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities in understanding common visual elements, largely due to their large-scale datasets and advanced training strategies. However, their effectiveness in medical applications remains limited due to the inherent discrepancies between data and tasks in medical scenarios and those in the general domain. Concretely, existing medical MLLMs face the following critical limitations: (1) limited coverage of medical knowledge beyond imaging, (2) heightened susceptibility to hallucinations due to suboptimal data curation processes, (3) lack of reasoning capabilities tailored for complex medical scenarios. To address these challenges, we first propose a comprehensive data curation procedure that (1) efficiently acquires rich medical knowledge data not only from medical imaging but also from extensive medical texts and general-domain data; and (2) synthesizes accurate medical captions, visual question answering (VQA), and reasoning samples. As a result, we build a multimodal dataset enriched with extensive medical knowledge. Building on the curated data, we introduce our medical-specialized MLLM: Lingshu. Lingshu undergoes multi-stage training to embed medical expertise and enhance its task-solving capabilities progressively. Besides, we preliminarily explore the potential of applying reinforcement learning with verifiable rewards paradigm to enhance Lingshu's medical reasoning ability. Additionally, we develop MedEvalKit, a unified evaluation framework that consolidates leading multimodal and textual medical benchmarks for standardized, fair, and efficient model assessment. We evaluate the performance of Lingshu on three fundamental medical tasks, multimodal QA, text-based QA, and medical report generation. The results show that Lingshu consistently outperforms the existing open-source multimodal models on most tasks ...
Joint Transmit and Receive Beamforming for Tri-directional Coil-Based Magnetic Induction Communications
May 30, 2025In this paper, we enhance the omnidirectional coverage performance of tri-directional coil-based magnetic induction communication (TC-MIC) and reduce the pathloss with a joint transmit and receive magnetic beamforming method. An iterative optimization algorithm incorporating the transmit current vector and receive weight matrix is developed to minimize the pathloss under constant transmit power constraints. We formulate the mathematical models for the mutual inductance of tri-directional coils, receive power, and pathloss. The optimization problem is decomposed into Rayleigh quotient extremum optimization for transmit currents and Cauchy-Schwarz inequality-constrained optimization for receive weights, with an alternating iterative algorithm to approach the global optimum. Numerical results demonstrate that the proposed algorithm converges within an average of 13.6 iterations, achieving up to 54% pathloss reduction compared with equal power allocation schemes. The joint optimization approach exhibits superior angular robustness, maintaining pathloss fluctuation smaller than 2 dB, and reducing fluctuation of pathloss by approximately 45% compared with single-parameter optimization methods.
Finding Fantastic Experts in MoEs: A Unified Study for Expert Dropping Strategies and Observations
Apr 10, 2025Sparsely activated Mixture-of-Experts (SMoE) has shown promise in scaling up the learning capacity of neural networks. However, vanilla SMoEs have issues such as expert redundancy and heavy memory requirements, making them inefficient and non-scalable, especially for resource-constrained scenarios. Expert-level sparsification of SMoEs involves pruning the least important experts to address these limitations. In this work, we aim to address three questions: (1) What is the best recipe to identify the least knowledgeable subset of experts that can be dropped with minimal impact on performance? (2) How should we perform expert dropping (one-shot or iterative), and what correction measures can we undertake to minimize its drastic impact on SMoE subnetwork capabilities? (3) What capabilities of full-SMoEs are severely impacted by the removal of the least dominant experts, and how can we recover them? Firstly, we propose MoE Experts Compression Suite (MC-Suite), which is a collection of some previously explored and multiple novel recipes to provide a comprehensive benchmark for estimating expert importance from diverse perspectives, as well as unveil numerous valuable insights for SMoE experts. Secondly, unlike prior works with a one-shot expert pruning approach, we explore the benefits of iterative pruning with the re-estimation of the MC-Suite criterion. Moreover, we introduce the benefits of task-agnostic fine-tuning as a correction mechanism during iterative expert dropping, which we term MoE Lottery Subnetworks. Lastly, we present an experimentally validated conjecture that, during expert dropping, SMoEs' instruction-following capabilities are predominantly hurt, which can be restored to a robust level subject to external augmentation of instruction-following capabilities using k-shot examples and supervised fine-tuning.
Determined blind source separation via modeling adjacent frequency band correlations in speech signals
Apr 05, 2025Multichannel blind source separation (MBSS), which focuses on separating signals of interest from mixed observations, has been extensively studied in acoustic and speech processing. Existing MBSS algorithms, such as independent low-rank matrix analysis (ILRMA) and multichannel nonnegative matrix factorization (MNMF), utilize the low-rank structure of source models but assume that frequency bins are independent. In contrast, independent vector analysis (IVA) does not rely on a low-rank source model but rather captures frequency dependencies based on a uniform correlation assumption. In this work, we demonstrate that dependencies between adjacent frequency bins are significantly stronger than those between bins that are farther apart in typical speech signals. To address this, we introduce a weighted Sinkhorn divergence-based ILRMA (wsILRMA) that simultaneously captures these inter-frequency dependencies and models joint probability distributions. Our approach incorporates an inter-frequency correlation constraint, leading to improved source separation performance compared to existing methods, as evidenced by higher Signal-to-Distortion Ratios (SDRs) and Source-to-Interference Ratios (SIRs).
CAFe: Unifying Representation and Generation with Contrastive-Autoregressive Finetuning
Mar 25, 2025The rapid advancement of large vision-language models (LVLMs) has driven significant progress in multimodal tasks, enabling models to interpret, reason, and generate outputs across both visual and textual domains. While excelling in generative tasks, existing LVLMs often face limitations in tasks requiring high-fidelity representation learning, such as generating image or text embeddings for retrieval. Recent work has proposed finetuning LVLMs for representational learning, but the fine-tuned model often loses its generative capabilities due to the representational learning training paradigm. To address this trade-off, we introduce CAFe, a contrastive-autoregressive fine-tuning framework that enhances LVLMs for both representation and generative tasks. By integrating a contrastive objective with autoregressive language modeling, our approach unifies these traditionally separate tasks, achieving state-of-the-art results in both multimodal retrieval and multimodal generative benchmarks, including object hallucination (OH) mitigation. CAFe establishes a novel framework that synergizes embedding and generative functionalities in a single model, setting a foundation for future multimodal models that excel in both retrieval precision and coherent output generation.
IDEA Prune: An Integrated Enlarge-and-Prune Pipeline in Generative Language Model Pretraining
Mar 07, 2025Recent advancements in large language models have intensified the need for efficient and deployable models within limited inference budgets. Structured pruning pipelines have shown promise in token efficiency compared to training target-size models from scratch. In this paper, we advocate incorporating enlarged model pretraining, which is often ignored in previous works, into pruning. We study the enlarge-and-prune pipeline as an integrated system to address two critical questions: whether it is worth pretraining an enlarged model even when the model is never deployed, and how to optimize the entire pipeline for better pruned models. We propose an integrated enlarge-and-prune pipeline, which combines enlarge model training, pruning, and recovery under a single cosine annealing learning rate schedule. This approach is further complemented by a novel iterative structured pruning method for gradual parameter removal. The proposed method helps to mitigate the knowledge loss caused by the rising learning rate in naive enlarge-and-prune pipelines and enable effective redistribution of model capacity among surviving neurons, facilitating smooth compression and enhanced performance. We conduct comprehensive experiments on compressing 2.8B models to 1.3B with up to 2T tokens in pretraining. It demonstrates the integrated approach not only provides insights into the token efficiency of enlarged model pretraining but also achieves superior performance of pruned models.