 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEBPO: Empirical Bayes Shrinkage for Stabilizing Group-Relative Policy Optimization
Feb 05, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective for enhancing the reasoning capabilities of Large Language Models (LLMs). However, dominant approaches like Group Relative Policy Optimization (GRPO) face critical stability challenges: they suffer from high estimator variance under computational constraints (small group sizes) and vanishing gradient signals in saturated failure regimes where all responses yield identical zero rewards. To address this, we propose Empirical Bayes Policy Optimization (EBPO), a novel framework that regularizes local group-based baselines by borrowing strength from the policy's accumulated global statistics. Instead of estimating baselines in isolation, EBPO employs a shrinkage estimator that dynamically balances local group statistics with a global prior updated via Welford's online algorithm. Theoretically, we demonstrate that EBPO guarantees strictly lower Mean Squared Error (MSE), bounded entropy decay, and non-vanishing penalty signals in failure scenarios compared to GRPO. Empirically, EBPO consistently outperforms GRPO and other established baselines across diverse benchmarks, including AIME and OlympiadBench. Notably, EBPO exhibits superior training stability, achieving high-performance gains even with small group sizes, and benefits significantly from difficulty-stratified curriculum learning.
Efficient Sequential Recommendation for Long Term User Interest Via Personalization
Jan 07, 2026Recent years have witnessed success of sequential modeling, generative recommender, and large language model for recommendation. Though the scaling law has been validated for sequential models, it showed inefficiency in computational capacity when considering real-world applications like recommendation, due to the non-linear(quadratic) increasing nature of the transformer model. To improve the efficiency of the sequential model, we introduced a novel approach to sequential recommendation that leverages personalization techniques to enhance efficiency and performance. Our method compresses long user interaction histories into learnable tokens, which are then combined with recent interactions to generate recommendations. This approach significantly reduces computational costs while maintaining high recommendation accuracy. Our method could be applied to existing transformer based recommendation models, e.g., HSTU and HLLM. Extensive experiments on multiple sequential models demonstrate its versatility and effectiveness. Source code is available at \href{https://github.com/facebookresearch/PerSRec}{https://github.com/facebookresearch/PerSRec}.
Think Then Embed: Generative Context Improves Multimodal Embedding
Oct 06, 2025There is a growing interest in Universal Multimodal Embeddings (UME), where models are required to generate task-specific representations. While recent studies show that Multimodal Large Language Models (MLLMs) perform well on such tasks, they treat MLLMs solely as encoders, overlooking their generative capacity. However, such an encoding paradigm becomes less effective as instructions become more complex and require compositional reasoning. Inspired by the proven effectiveness of chain-of-thought reasoning, we propose a general Think-Then-Embed (TTE) framework for UME, composed of a reasoner and an embedder. The reasoner MLLM first generates reasoning traces that explain complex queries, followed by an embedder that produces representations conditioned on both the original query and the intermediate reasoning. This explicit reasoning step enables more nuanced understanding of complex multimodal instructions. Our contributions are threefold. First, by leveraging a powerful MLLM reasoner, we achieve state-of-the-art performance on the MMEB-V2 benchmark, surpassing proprietary models trained on massive in-house datasets. Second, to reduce the dependency on large MLLM reasoners, we finetune a smaller MLLM reasoner using high-quality embedding-centric reasoning traces, achieving the best performance among open-source models with a 7% absolute gain over recently proposed models. Third, we investigate strategies for integrating the reasoner and embedder into a unified model for improved efficiency without sacrificing performance.
Exploring System 1 and 2 communication for latent reasoning in LLMs
Oct 01, 2025Should LLM reasoning live in a separate module, or within a single model's forward pass and representational space? We study dual-architecture latent reasoning, where a fluent Base exchanges latent messages with a Coprocessor, and test two hypotheses aimed at improving latent communication over Liu et al. (2024): (H1) increase channel capacity; (H2) learn communication via joint finetuning. Under matched latent-token budgets on GPT-2 and Qwen-3, H2 is consistently strongest while H1 yields modest gains. A unified soft-embedding baseline, a single model with the same forward pass and shared representations, using the same latent-token budget, nearly matches H2 and surpasses H1, suggesting current dual designs mostly add compute rather than qualitatively improving reasoning. Across GSM8K, ProsQA, and a Countdown stress test with increasing branching factor, scaling the latent-token budget beyond small values fails to improve robustness. Latent analyses show overlapping subspaces with limited specialization, consistent with weak reasoning gains. We conclude dual-model latent reasoning remains promising in principle, but likely requires objectives and communication mechanisms that explicitly shape latent spaces for algorithmic planning.
GEM: Empowering LLM for both Embedding Generation and Language Understanding
Jun 04, 2025Large decoder-only language models (LLMs) have achieved remarkable success in generation and reasoning tasks, where they generate text responses given instructions. However, many applications, e.g., retrieval augmented generation (RAG), still rely on separate embedding models to generate text embeddings, which can complicate the system and introduce discrepancies in understanding of the query between the embedding model and LLMs. To address this limitation, we propose a simple self-supervised approach, Generative Embedding large language Model (GEM), that enables any large decoder-only LLM to generate high-quality text embeddings while maintaining its original text generation and reasoning capabilities. Our method inserts new special token(s) into a text body, and generates summarization embedding of the text by manipulating the attention mask. This method could be easily integrated into post-training or fine tuning stages of any existing LLMs. We demonstrate the effectiveness of our approach by applying it to two popular LLM families, ranging from 1B to 8B parameters, and evaluating the transformed models on both text embedding benchmarks (MTEB) and NLP benchmarks (MMLU). The results show that our proposed method significantly improves the original LLMs on MTEB while having a minimal impact on MMLU. Our strong results indicate that our approach can empower LLMs with state-of-the-art text embedding capabilities while maintaining their original NLP performance
S'MoRE: Structural Mixture of Residual Experts for LLM Fine-tuning
Apr 08, 2025Fine-tuning pre-trained large language models (LLMs) presents a dual challenge of balancing parameter efficiency and model capacity. Existing methods like low-rank adaptations (LoRA) are efficient but lack flexibility, while Mixture-of-Experts (MoE) architectures enhance model capacity at the cost of more & under-utilized parameters. To address these limitations, we propose Structural Mixture of Residual Experts (S'MoRE), a novel framework that seamlessly integrates the efficiency of LoRA with the flexibility of MoE. Specifically, S'MoRE employs hierarchical low-rank decomposition of expert weights, yielding residuals of varying orders interconnected in a multi-layer structure. By routing input tokens through sub-trees of residuals, S'MoRE emulates the capacity of many experts by instantiating and assembling just a few low-rank matrices. We craft the inter-layer propagation of S'MoRE's residuals as a special type of Graph Neural Network (GNN), and prove that under similar parameter budget, S'MoRE improves "structural flexibility" of traditional MoE (or Mixture-of-LoRA) by exponential order. Comprehensive theoretical analysis and empirical results demonstrate that S'MoRE achieves superior fine-tuning performance, offering a transformative approach for efficient LLM adaptation.
CAFe: Unifying Representation and Generation with Contrastive-Autoregressive Finetuning
Mar 25, 2025The rapid advancement of large vision-language models (LVLMs) has driven significant progress in multimodal tasks, enabling models to interpret, reason, and generate outputs across both visual and textual domains. While excelling in generative tasks, existing LVLMs often face limitations in tasks requiring high-fidelity representation learning, such as generating image or text embeddings for retrieval. Recent work has proposed finetuning LVLMs for representational learning, but the fine-tuned model often loses its generative capabilities due to the representational learning training paradigm. To address this trade-off, we introduce CAFe, a contrastive-autoregressive fine-tuning framework that enhances LVLMs for both representation and generative tasks. By integrating a contrastive objective with autoregressive language modeling, our approach unifies these traditionally separate tasks, achieving state-of-the-art results in both multimodal retrieval and multimodal generative benchmarks, including object hallucination (OH) mitigation. CAFe establishes a novel framework that synergizes embedding and generative functionalities in a single model, setting a foundation for future multimodal models that excel in both retrieval precision and coherent output generation.
Beyond Reward Hacking: Causal Rewards for Large Language Model Alignment
Jan 16, 2025



Recent advances in large language models (LLMs) have demonstrated significant progress in performing complex tasks. While Reinforcement Learning from Human Feedback (RLHF) has been effective in aligning LLMs with human preferences, it is susceptible to spurious correlations in reward modeling. Consequently, it often introduces biases-such as length bias, sycophancy, conceptual bias, and discrimination that hinder the model's ability to capture true causal relationships. To address this, we propose a novel causal reward modeling approach that integrates causal inference to mitigate these spurious correlations. Our method enforces counterfactual invariance, ensuring reward predictions remain consistent when irrelevant variables are altered. Through experiments on both synthetic and real-world datasets, we show that our approach mitigates various types of spurious correlations effectively, resulting in more reliable and fair alignment of LLMs with human preferences. As a drop-in enhancement to the existing RLHF workflow, our causal reward modeling provides a practical way to improve the trustworthiness and fairness of LLM finetuning.
Quantifying Generalization Complexity for Large Language Models
Oct 02, 2024While large language models (LLMs) have shown exceptional capabilities in understanding complex queries and performing sophisticated tasks, their generalization abilities are often deeply entangled with memorization, necessitating more precise evaluation. To address this challenge, we introduce Scylla, a dynamic evaluation framework that quantitatively measures the generalization abilities of LLMs. Scylla disentangles generalization from memorization via assessing model performance on both in-distribution (ID) and out-of-distribution (OOD) data through 20 tasks across 5 levels of complexity. Through extensive experiments, we uncover a non-monotonic relationship between task complexity and the performance gap between ID and OOD data, which we term the generalization valley. Specifically, this phenomenon reveals a critical threshold - referred to as critical complexity - where reliance on non-generalizable behavior peaks, indicating the upper bound of LLMs' generalization capabilities. As model size increases, the critical complexity shifts toward higher levels of task complexity, suggesting that larger models can handle more complex reasoning tasks before over-relying on memorization. Leveraging Scylla and the concept of critical complexity, we benchmark 28LLMs including both open-sourced models such as LLaMA and Qwen families, and close-sourced models like Claude and GPT, providing a more robust evaluation and establishing a clearer understanding of LLMs' generalization capabilities.
HallE-Switch: Rethinking and Controlling Object Existence Hallucinations in Large Vision Language Models for Detailed Caption
Oct 03, 2023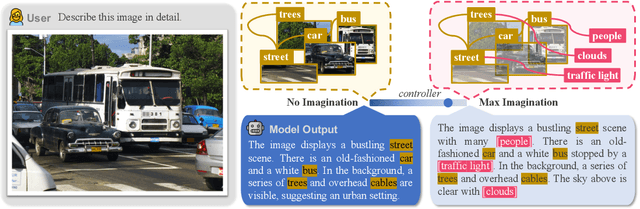
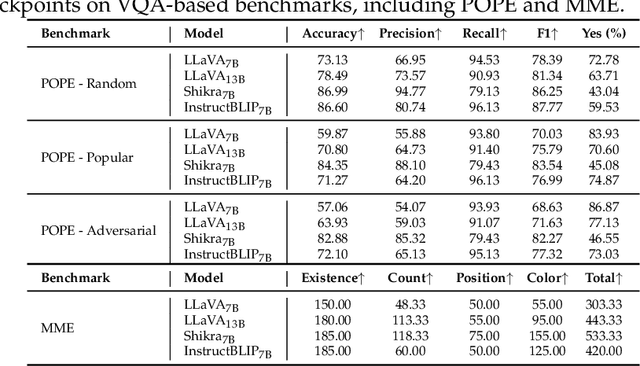

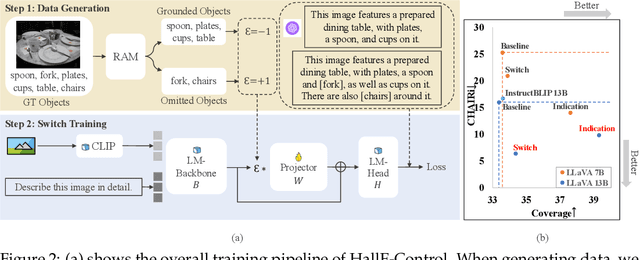
Current large vision-language models (LVLMs) achieve remarkable progress, yet there remains significant uncertainty regarding their ability to accurately apprehend visual details, that is, in performing detailed captioning. To address this, we introduce \textit{CCEval}, a GPT-4 assisted evaluation method tailored for detailed captioning. Interestingly, while LVLMs demonstrate minimal object existence hallucination in existing VQA benchmarks, our proposed evaluation reveals continued susceptibility to such hallucinations. In this paper, we make the first attempt to investigate and attribute such hallucinations, including image resolution, the language decoder size, and instruction data amount, quality, granularity. Our findings underscore the unwarranted inference when the language description includes details at a finer object granularity than what the vision module can ground or verify, thus inducing hallucination. To control such hallucinations, we further attribute the reliability of captioning to contextual knowledge (involving only contextually grounded objects) and parametric knowledge (containing inferred objects by the model). Thus, we introduce $\textit{HallE-Switch}$, a controllable LVLM in terms of $\textbf{Hall}$ucination in object $\textbf{E}$xistence. HallE-Switch can condition the captioning to shift between (i) exclusively depicting contextual knowledge for grounded objects and (ii) blending it with parametric knowledge to imagine inferred objects. Our method reduces hallucination by 44% compared to LLaVA$_{7B}$ and maintains the same object coverage.