 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallE-Switch: Rethinking and Controlling Object Existence Hallucinations in Large Vision Language Models for Detailed Caption
Paper and Code
Oct 03, 2023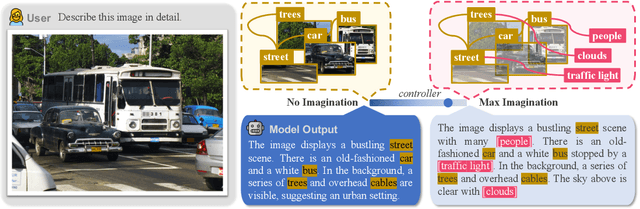
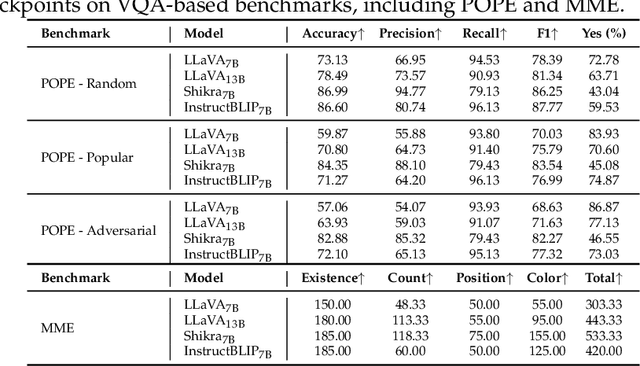

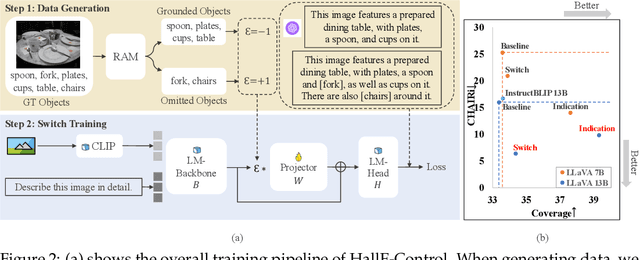
Current large vision-language models (LVLMs) achieve remarkable progress, yet there remains significant uncertainty regarding their ability to accurately apprehend visual details, that is, in performing detailed captioning. To address this, we introduce \textit{CCEval}, a GPT-4 assisted evaluation method tailored for detailed captioning. Interestingly, while LVLMs demonstrate minimal object existence hallucination in existing VQA benchmarks, our proposed evaluation reveals continued susceptibility to such hallucinations. In this paper, we make the first attempt to investigate and attribute such hallucinations, including image resolution, the language decoder size, and instruction data amount, quality, granularity. Our findings underscore the unwarranted inference when the language description includes details at a finer object granularity than what the vision module can ground or verify, thus inducing hallucination. To control such hallucinations, we further attribute the reliability of captioning to contextual knowledge (involving only contextually grounded objects) and parametric knowledge (containing inferred objects by the model). Thus, we introduce $\textit{HallE-Switch}$, a controllable LVLM in terms of $\textbf{Hall}$ucination in object $\textbf{E}$xistence. HallE-Switch can condition the captioning to shift between (i) exclusively depicting contextual knowledge for grounded objects and (ii) blending it with parametric knowledge to imagine inferred objects. Our method reduces hallucination by 44% compared to LLaVA$_{7B}$ and maintains the same object coverage.