 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow Your Step: Faster and Better Alignment for Flow Matching Models via Step-aware Advantages
Feb 02, 2026Recent advances in flow matching models, particularly with reinforcement learning (RL), have significantly enhanced human preference alignment in few step text to image generators. However, existing RL based approaches for flow matching models typically rely on numerous denoising steps, while suffering from sparse and imprecise reward signals that often lead to suboptimal alignment. To address these limitations, we propose Temperature Annealed Few step Sampling with Group Relative Policy Optimization (TAFS GRPO), a novel framework for training flow matching text to image models into efficient few step generators well aligned with human preferences. Our method iteratively injects adaptive temporal noise onto the results of one step samples. By repeatedly annealing the model's sampled outputs, it introduces stochasticity into the sampling process while preserving the semantic integrity of each generated image. Moreover, its step aware advantage integration mechanism combines the GRPO to avoid the need for the differentiable of reward function and provide dense and step specific rewards for stable policy optimization. Extensive experiments demonstrate that TAFS GRPO achieves strong performance in few step text to image generation and significantly improves the alignment of generated images with human preferences. The code and models of this work will be available to facilitate further research.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Rethinking Bias in Generative Data Augmentation for Medical AI: a Frequency Recalibration Method
Nov 15, 2025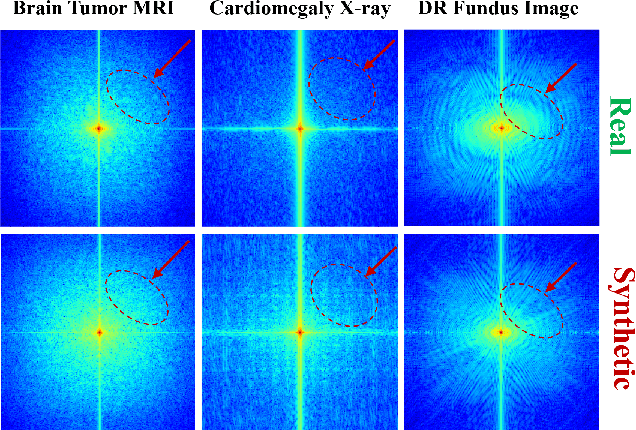

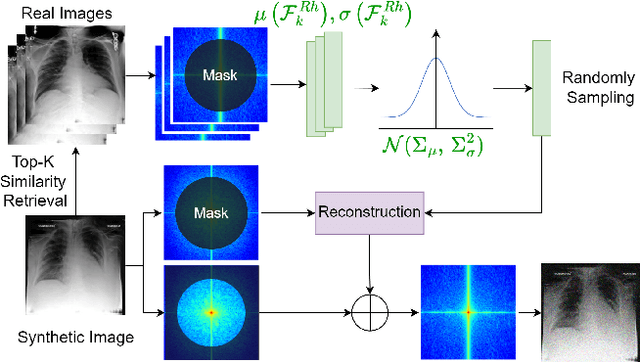
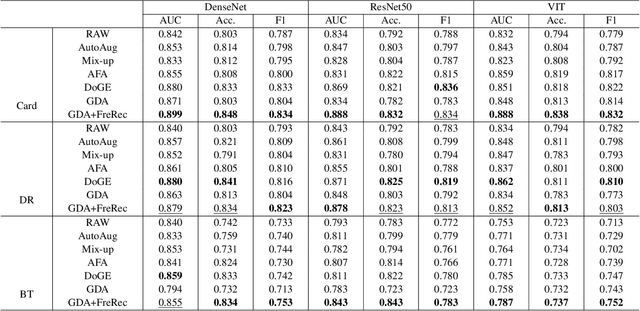
Developing Medical AI relies on large datasets and easily suffers from data scarcity. Generative data augmentation (GDA) using AI generative models offers a solution to synthesize realistic medical images. However, the bias in GDA is often underestimated in medical domains, with concerns about the risk of introducing detrimental features generated by AI and harming downstream tasks. This paper identifies the frequency misalignment between real and synthesized images as one of the key factors underlying unreliable GDA and proposes the Frequency Recalibration (FreRec) method to reduce the frequency distributional discrepancy and thus improve GDA. FreRec involves (1) Statistical High-frequency Replacement (SHR) to roughly align high-frequency components and (2) Reconstructive High-frequency Mapping (RHM) to enhance image quality and reconstruct high-frequency details. Extensive experiments were conducted in various medical datasets, including brain MRIs, chest X-rays, and fundus images. The results show that FreRec significantly improves downstream medical image classification performance compared to uncalibrated AI-synthesized samples. FreRec is a standalone post-processing step that is compatible with any generative model and can integrate seamlessly with common medical GDA pipelines.
Positional Encoding via Token-Aware Phase Attention
Sep 16, 2025We prove under practical assumptions that Rotary Positional Embedding (RoPE) introduces an intrinsic distance-dependent bias in attention scores that limits RoPE's ability to model long-context. RoPE extension methods may alleviate this issue, but they typically require post-hoc adjustments after pretraining, such as rescaling or hyperparameters retuning. This paper introduces Token-Aware Phase Attention (TAPA), a new positional encoding method that incorporates a learnable phase function into the attention mechanism. TAPA preserves token interactions over long range, extends to longer contexts with direct and light fine-tuning, extrapolates to unseen lengths, and attains significantly lower perplexity on long-context than RoPE families.
Deep learning of personalized priors from past MRI scans enables fast, quality-enhanced point-of-care MRI with low-cost systems
May 05, 2025Magnetic resonance imaging (MRI) offers superb-quality images, but its accessibility is limited by high costs, posing challenges for patients requiring longitudinal care. Low-field MRI provides affordable imaging with low-cost devices but is hindered by long scans and degraded image quality, including low signal-to-noise ratio (SNR) and tissue contrast. We propose a novel healthcare paradigm: using deep learning to extract personalized features from past standard high-field MRI scans and harnessing them to enable accelerated, enhanced-quality follow-up scans with low-cost systems. To overcome the SNR and contrast differences, we introduce ViT-Fuser, a feature-fusion vision transformer that learns features from past scans, e.g. those stored in standard DICOM CDs. We show that \textit{a single prior scan is sufficient}, and this scan can come from various MRI vendors, field strengths, and pulse sequences. Experiments with four datasets, including glioblastoma data, low-field ($50mT$), and ultra-low-field ($6.5mT$) data, demonstrate that ViT-Fuser outperforms state-of-the-art methods, providing enhanced-quality images from accelerated low-field scans, with robustness to out-of-distribution data. Our freely available framework thus enables rapid, diagnostic-quality, low-cost imaging for wide healthcare applications.
Unleashing the Power of Pre-trained Encoders for Universal Adversarial Attack Detection
Apr 01, 2025



Adversarial attacks pose a critical security threat to real-world AI systems by injecting human-imperceptible perturbations into benign samples to induce misclassification in deep learning models. While existing detection methods, such as Bayesian uncertainty estimation and activation pattern analysis, have achieved progress through feature engineering, their reliance on handcrafted feature design and prior knowledge of attack patterns limits generalization capabilities and incurs high engineering costs. To address these limitations, this paper proposes a lightweight adversarial detection framework based on the large-scale pre-trained vision-language model CLIP. Departing from conventional adversarial feature characterization paradigms, we innovatively adopt an anomaly detection perspective. By jointly fine-tuning CLIP's dual visual-text encoders with trainable adapter networks and learnable prompts, we construct a compact representation space tailored for natural images. Notably, our detection architecture achieves substantial improvements in generalization capability across both known and unknown attack patterns compared to traditional methods, while significantly reducing training overhead. This study provides a novel technical pathway for establishing a parameter-efficient and attack-agnostic defense paradigm, markedly enhancing the robustness of vision systems against evolving adversarial threats.
Can LLMs Assist Computer Education? an Empirical Case Study of DeepSeek
Apr 01, 2025



This study presents an empirical case study to assess the efficacy and reliability of DeepSeek-V3, an emerging large language model, within the context of computer education. The evaluation employs both CCNA simulation questions and real-world inquiries concerning computer network security posed by Chinese network engineers. To ensure a thorough evaluation, diverse dimensions are considered, encompassing role dependency, cross-linguistic proficiency, and answer reproducibility, accompanied by statistical analysis. The findings demonstrate that the model performs consistently, regardless of whether prompts include a role definition or not. In addition, its adaptability across languages is confirmed by maintaining stable accuracy in both original and translated datasets. A distinct contrast emerges between its performance on lower-order factual recall tasks and higher-order reasoning exercises, which underscores its strengths in retrieving information and its limitations in complex analytical tasks. Although DeepSeek-V3 offers considerable practical value for network security education, challenges remain in its capability to process multimodal data and address highly intricate topics. These results provide valuable insights for future refinement of large language models in specialized professional environments.
Enhancing Fundus Image-based Glaucoma Screening via Dynamic Global-Local Feature Integration
Apr 01, 2025



With the advancements in medical artificial intelligence (AI), fundus image classifiers are increasingly being applied to assist in ophthalmic diagnosis. While existing classification models have achieved high accuracy on specific fundus datasets, they struggle to address real-world challenges such as variations in image quality across different imaging devices, discrepancies between training and testing images across different racial groups, and the uncertain boundaries due to the characteristics of glaucomatous cases. In this study, we aim to address the above challenges posed by image variations by highlighting the importance of incorporating comprehensive fundus image information, including the optic cup (OC) and optic disc (OD) regions, and other key image patches. Specifically, we propose a self-adaptive attention window that autonomously determines optimal boundaries for enhanced feature extraction. Additionally, we introduce a multi-head attention mechanism to effectively fuse global and local features via feature linear readout, improving the model's discriminative capability. Experimental results demonstrate that our method achieves superior accuracy and robustness in glaucoma classification.
BLIP3-KALE: Knowledge Augmented Large-Scale Dense Captions
Nov 12, 2024
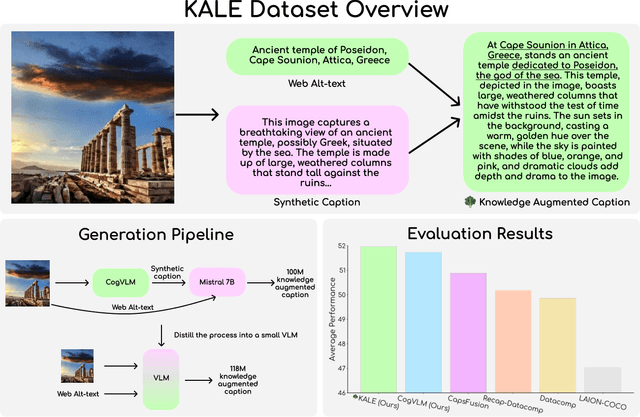
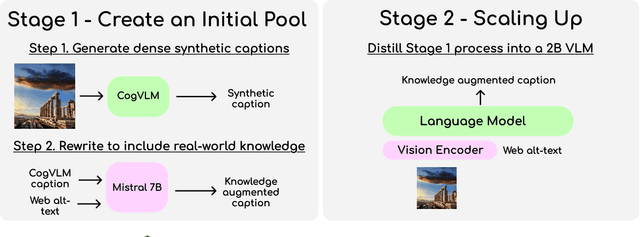

We introduce BLIP3-KALE, a dataset of 218 million image-text pairs that bridges the gap between descriptive synthetic captions and factual web-scale alt-text. KALE augments synthetic dense image captions with web-scale alt-text to generate factually grounded image captions. Our two-stage approach leverages large vision-language models and language models to create knowledge-augmented captions, which are then used to train a specialized VLM for scaling up the dataset. We train vision-language models on KALE and demonstrate improvements on vision-language tasks. Our experiments show the utility of KALE for training more capable and knowledgeable multimodal models. We release the KALE dataset at https://huggingface.co/datasets/Salesforce/blip3-kale
Reimagining Linear Probing: Kolmogorov-Arnold Networks in Transfer Learning
Sep 12, 2024
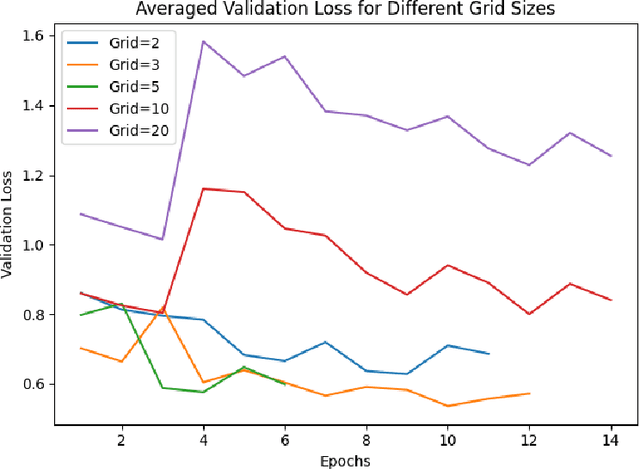


This paper introduces Kolmogorov-Arnold Networks (KAN) as an enhancement to the traditional linear probing method in transfer learning. Linear probing, often applied to the final layer of pre-trained models, is limited by its inability to model complex relationships in data. To address this, we propose substituting the linear probing layer with KAN, which leverages spline-based representations to approximate intricate functions. In this study, we integrate KAN with a ResNet-50 model pre-trained on ImageNet and evaluate its performance on the CIFAR-10 dataset. We perform a systematic hyperparameter search, focusing on grid size and spline degree (k), to optimize KAN's flexibility and accuracy. Our results demonstrate that KAN consistently outperforms traditional linear probing, achieving significant improvements in accuracy and generalization across a range of configurations. These findings indicate that KAN offers a more powerful and adaptable alternative to conventional linear probing techniques in transfer learning.