 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath-Guided Flow Matching for Dataset Distillation
Feb 05, 2026Dataset distillation compresses large datasets into compact synthetic sets with comparable performance in training models. Despite recent progress on diffusion-based distillation, this type of method typically depends on heuristic guidance or prototype assignment, which comes with time-consuming sampling and trajectory instability and thus hurts downstream generalization especially under strong control or low IPC. We propose \emph{Path-Guided Flow Matching (PGFM)}, the first flow matching-based framework for generative distillation, which enables fast deterministic synthesis by solving an ODE in a few steps. PGFM conducts flow matching in the latent space of a frozen VAE to learn class-conditional transport from Gaussian noise to data distribution. Particularly, we develop a continuous path-to-prototype guidance algorithm for ODE-consistent path control, which allows trajectories to reliably land on assigned prototypes while preserving diversity and efficiency. Extensive experiments across high-resolution benchmarks demonstrate that PGFM matches or surpasses prior diffusion-based distillation approaches with fewer steps of sampling while delivering competitive performance with remarkably improved efficiency, e.g., 7.6$\times$ more efficient than the diffusion-based counterparts with 78\% mode coverage.
Local-Curvature-Aware Knowledge Graph Embedding: An Extended Ricci Flow Approach
Dec 10, 2025Knowledge graph embedding (KGE) relies on the geometry of the embedding space to encode semantic and structural relations. Existing methods place all entities on one homogeneous manifold, Euclidean, spherical, hyperbolic, or their product/multi-curvature variants, to model linear, symmetric, or hierarchical patterns. Yet a predefined, homogeneous manifold cannot accommodate the sharply varying curvature that real-world graphs exhibit across local regions. Since this geometry is imposed a priori, any mismatch with the knowledge graph's local curvatures will distort distances between entities and hurt the expressiveness of the resulting KGE. To rectify this, we propose RicciKGE to have the KGE loss gradient coupled with local curvatures in an extended Ricci flow such that entity embeddings co-evolve dynamically with the underlying manifold geometry towards mutual adaptation. Theoretically, when the coupling coefficient is bounded and properly selected, we rigorously prove that i) all the edge-wise curvatures decay exponentially, meaning that the manifold is driven toward the Euclidean flatness; and ii) the KGE distances strictly converge to a global optimum, which indicates that geometric flattening and embedding optimization are promoting each other. Experimental improvements on link prediction and node classification benchmarks demonstrate RicciKGE's effectiveness in adapting to heterogeneous knowledge graph structures.
GeoDM: Geometry-aware Distribution Matching for Dataset Distillation
Dec 10, 2025Dataset distillation aims to synthesize a compact subset of the original data, enabling models trained on it to achieve performance comparable to those trained on the original large dataset. Existing distribution-matching methods are confined to Euclidean spaces, making them only capture linear structures and overlook the intrinsic geometry of real data, e.g., curvature. However, high-dimensional data often lie on low-dimensional manifolds, suggesting that dataset distillation should have the distilled data manifold aligned with the original data manifold. In this work, we propose a geometry-aware distribution-matching framework, called \textbf{GeoDM}, which operates in the Cartesian product of Euclidean, hyperbolic, and spherical manifolds, with flat, hierarchical, and cyclical structures all captured by a unified representation. To adapt to the underlying data geometry, we introduce learnable curvature and weight parameters for three kinds of geometries. At the same time, we design an optimal transport loss to enhance the distribution fidelity. Our theoretical analysis shows that the geometry-aware distribution matching in a product space yields a smaller generalization error bound than the Euclidean counterparts. Extensive experiments conducted on standard benchmarks demonstrate that our algorithm outperforms state-of-the-art data distillation methods and remains effective across various distribution-matching strategies for the single geometries.
KGOT: Unified Knowledge Graph and Optimal Transport Pseudo-Labeling for Molecule-Protein Interaction Prediction
Dec 10, 2025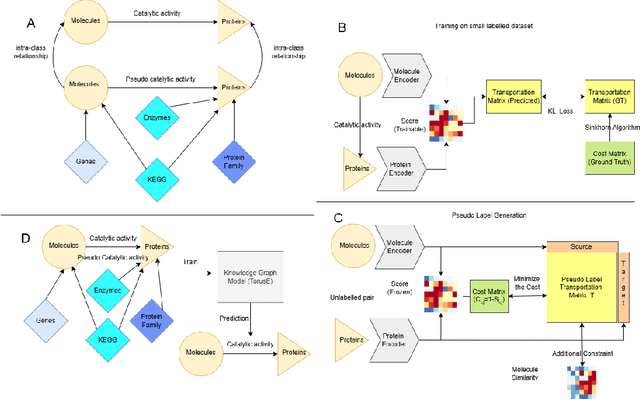
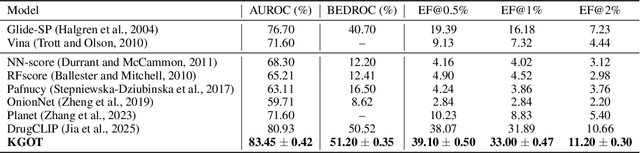
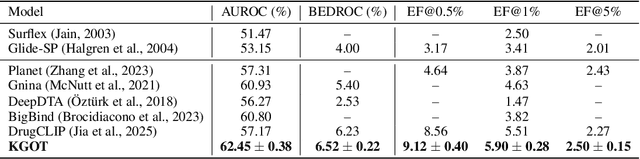
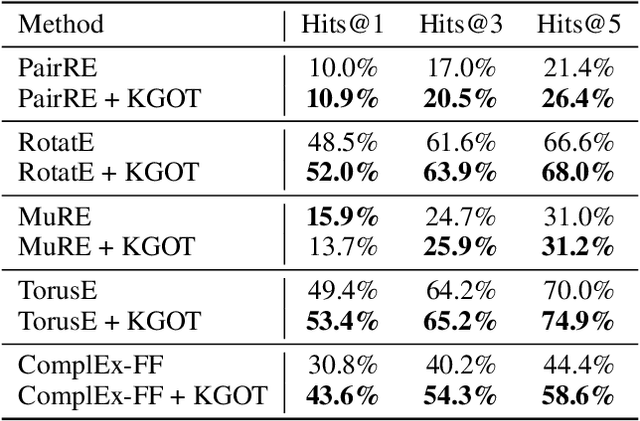
Predicting molecule-protein interactions (MPIs) is a fundamental task in computational biology, with crucial applications in drug discovery and molecular function annotation. However, existing MPI models face two major challenges. First, the scarcity of labeled molecule-protein pairs significantly limits model performance, as available datasets capture only a small fraction of biological relevant interactions. Second, most methods rely solely on molecular and protein features, ignoring broader biological context such as genes, metabolic pathways, and functional annotations that could provide essential complementary information. To address these limitations, our framework first aggregates diverse biological datasets, including molecular, protein, genes and pathway-level interactions, and then develop an optimal transport-based approach to generate high-quality pseudo-labels for unlabeled molecule-protein pairs, leveraging the underlying distribution of known interactions to guide label assignment. By treating pseudo-labeling as a mechanism for bridging disparate biological modalities, our approach enables the effective use of heterogeneous data to enhance MPI prediction. We evaluate our framework on multiple MPI datasets including virtual screening tasks and protein retrieval tasks, demonstrating substantial improvements over state-of-the-art methods in prediction accuracies and zero shot ability across unseen interactions. Beyond MPI prediction, our approach provides a new paradigm for leveraging diverse biological data sources to tackle problems traditionally constrained by single- or bi-modal learning, paving the way for future advances in computational biology and drug discovery.
Can LLMs Assist Computer Education? an Empirical Case Study of DeepSeek
Apr 01, 2025



This study presents an empirical case study to assess the efficacy and reliability of DeepSeek-V3, an emerging large language model, within the context of computer education. The evaluation employs both CCNA simulation questions and real-world inquiries concerning computer network security posed by Chinese network engineers. To ensure a thorough evaluation, diverse dimensions are considered, encompassing role dependency, cross-linguistic proficiency, and answer reproducibility, accompanied by statistical analysis. The findings demonstrate that the model performs consistently, regardless of whether prompts include a role definition or not. In addition, its adaptability across languages is confirmed by maintaining stable accuracy in both original and translated datasets. A distinct contrast emerges between its performance on lower-order factual recall tasks and higher-order reasoning exercises, which underscores its strengths in retrieving information and its limitations in complex analytical tasks. Although DeepSeek-V3 offers considerable practical value for network security education, challenges remain in its capability to process multimodal data and address highly intricate topics. These results provide valuable insights for future refinement of large language models in specialized professional environments.
Balanced Representation Learning for Long-tailed Skeleton-based Action Recognition
Aug 27, 2023Skeleton-based action recognition has recently made significant progress. However, data imbalance is still a great challenge in real-world scenarios. The performance of current action recognition algorithms declines sharply when training data suffers from heavy class imbalance. The imbalanced data actually degrades the representations learned by these methods and becomes the bottleneck for action recognition. How to learn unbiased representations from imbalanced action data is the key to long-tailed action recognition. In this paper, we propose a novel balanced representation learning method to address the long-tailed problem in action recognition. Firstly, a spatial-temporal action exploration strategy is presented to expand the sample space effectively, generating more valuable samples in a rebalanced manner. Secondly, we design a detached action-aware learning schedule to further mitigate the bias in the representation space. The schedule detaches the representation learning of tail classes from training and proposes an action-aware loss to impose more effective constraints. Additionally, a skip-modal representation is proposed to provide complementary structural information. The proposed method is validated on four skeleton datasets, NTU RGB+D 60, NTU RGB+D 120, NW-UCLA, and Kinetics. It not only achieves consistently large improvement compared to the state-of-the-art (SOTA) methods, but also demonstrates a superior generalization capacity through extensive experiments. Our code is available at https://github.com/firework8/BRL.
Disentangled Federated Learning for Tackling Attributes Skew via Invariant Aggregation and Diversity Transferring
Jun 14, 2022



Attributes skew hinders the current federated learning (FL) frameworks from consistent optimization directions among the clients, which inevitably leads to performance reduction and unstable convergence. The core problems lie in that: 1) Domain-specific attributes, which are non-causal and only locally valid, are indeliberately mixed into global aggregation. 2) The one-stage optimizations of entangled attributes cannot simultaneously satisfy two conflicting objectives, i.e., generalization and personalization. To cope with these, we proposed disentangled federated learning (DFL) to disentangle the domain-specific and cross-invariant attributes into two complementary branches, which are trained by the proposed alternating local-global optimization independently. Importantly, convergence analysis proves that the FL system can be stably converged even if incomplete client models participate in the global aggregation, which greatly expands the application scope of FL. Extensive experiments verify that DFL facilitates FL with higher performance, better interpretability, and faster convergence rate, compared with SOTA FL methods on both manually synthesized and realistic attributes skew datasets.