 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHT-Bench: Benchmarking and Learning Dexterous Full-Hand Tactile Representations with Egocentric Vision
Jun 17, 2026Establishing a universal benchmark for tactile representation learning in robotic manipulation remains challenging due to the diversity of tactile sensor designs, data formats, and robot embodiments. Rather than seeking to establish such, we explore a scalable and promising direction for future development: egocentric vision paired with full-hand tactile data. To this end, we introduce \textbf{HT-Bench}, a large-scale multi-task benchmark for dexterous full-hand tactile sensing, comprising 10M RGB frames and 7.8M tactile frames collected across 226 tasks. HT-Bench evaluates tactile representations from three key perspectives: whether they encode meaningful contact geometry, whether they can align tactile observations with visual information, and whether they generalize to unseen tasks. To assess these capabilities, HT-Bench includes four tasks: fine-grained tactile similarity retrieval, masked tactile inpainting, vision-to-tactile synthesis, and multimodal tactile frame prediction. We further propose \textbf{HandTouch}, a vector-quantized vision--tactile encoder that learns tactile representations through progressive spatial, cross-modal, and temporal training. Across HT-Bench, HandTouch consistently outperforms representative tactile encoder baselines, improving Recall@5 on fine-grained tactile similarity retrieval from 74.65\% to 85.23\%, reducing RMSE on masked tactile inpainting from 0.022 to 0.010, and increasing OOD cIoU on vision-to-tactile synthesis from 0.628 to 0.705. These results demonstrate the effectiveness of HandTouch and suggest that large-scale egocentric full-hand tactile data provides a scalable basis for evaluating and advancing tactile representation learning in dexterous manipulation.
UniDexTok: A Unified Dexterous Hand Tokenizer from Real Data
Jun 09, 2026Dexterous hands are essential for fine-grained manipulation, but their hardware designs vary substantially across embodiments. Differences in kinematics, joint definitions, and degrees of freedom make it difficult to define a shared state representation compared with parallel grippers. As a result, dexterous-hand data remains fragmented and difficult to use for joint training. In this work, we propose the Unified Dexterous Hand Model (UDHM), which maps human and robot hand states into a shared 22-DoF semantic interface. Based on UDHM, we introduce UniDexTok, a retargeting-free state tokenizer that learns embodiment-conditioned discrete tokens from standardized real joint states. UniDexTok provides a unified representation for heterogeneous dexterous hands without relying on retargeting or simulation data. Compared with the recent baseline UniHM, UniDexTok reduces MPJAE from 15.63 degrees to 0.16 degrees and MPJPE from 18.51 mm to 0.18 mm, corresponding to error reductions of 98.98% and 99.03%, respectively. These results improve reconstruction from centimeter-scale to sub-millimeter accuracy. Experiments further show that data from other embodiments improves target-embodiment reconstruction accuracy, demonstrating the benefit of cross-embodiment tokenization. UniDexTok also shows strong zero-shot and few-shot reconstruction ability when new dexterous hands are introduced.
Pareto-Enhanced Portrait Generation: Vision-Aligned Text Supervision for Alignment, Realism, and Aesthetics
May 20, 2026Text-to-image diffusion models often face a severe trilemma in human portrait generation: text-image alignment, photorealism, and human-perceived aesthetics inherently inhibit one another. Supervised Fine-Tuning (SFT) is an effective method for enhancing the photorealism of image generation. However, it often leads to overfitting to the training dataset, corrupts pre-trained image priors, and degrades alignment or aesthetics. To break this bottleneck, we propose a feature supervision paradigm for Multimodal Diffusion Transformers (MM-DiT). Specifically, we introduce a lightweight cross-modal alignment mechanism that implicitly extracts multi-granularity vision-aligned text representations from SigLIP 2 and applies supervision to the image branch of MM-DiT during the training stage, with zero extra inference overhead. Our method injects vision-aligned text guidance while preserving the base model's original generalization, avoiding degradation caused by SFT. Furthermore, our method directly mines implicit multi-granularity aesthetic signals from pre-trained vision foundation models to optimize human-perceived aesthetics. Extensive experiments on MM-DiTs show that our method pushes the Pareto frontier and achieves synergistic improvements across text-image alignment, photorealism, and human-perceived aesthetics.
XEmbodied: A Foundation Model with Enhanced Geometric and Physical Cues for Large-Scale Embodied Environments
Apr 20, 2026Vision-Language-Action (VLA) models drive next-generation autonomous systems, but training them requires scalable, high-quality annotations from complex environments. Current cloud pipelines rely on generic vision-language models (VLMs) that lack geometric reasoning and domain semantics due to their 2D image-text pretraining. To address this mismatch, we propose XEmbodied, a cloud-side foundation model that endows VLMs with intrinsic 3D geometric awareness and interaction with physical cues (e.g., occupancy grids, 3D boxes). Instead of treating geometry as auxiliary input, XEmbodied integrates geometric representations via a structured 3D Adapter and distills physical signals into context tokens using an Efficient Image-Embodied Adapter. Through progressive domain curriculum and reinforcement learning post-training, XEmbodied preserves general capabilities while demonstrating robust performance across 18 public benchmarks. It significantly improves spatial reasoning, traffic semantics, embodied affordance, and out-of-distribution generalization for large-scale scenario mining and embodied VQA.
ALOE: Action-Level Off-Policy Evaluation for Vision-Language-Action Model Post-Training
Feb 13, 2026We study how to improve large foundation vision-language-action (VLA) systems through online reinforcement learning (RL) in real-world settings. Central to this process is the value function, which provides learning signals to guide VLA learning from experience. In practice, the value function is estimated from trajectory fragments collected from different data sources, including historical policies and intermittent human interventions. Estimating the value function of current behavior quality from the mixture data is inherently an off-policy evaluation problem. However, prior work often adopts conservative on-policy estimation for stability, which avoids direct evaluation of the current high-capacity policy and limits learning effectiveness. In this paper, we propose ALOE, an action-level off-policy evaluation framework for VLA post-training. ALOE applies chunking-based temporal-difference bootstrapping to evaluate individual action sequences instead of predicting final task outcomes. This design improves effective credit assignment to critical action chunks under sparse rewards and supports stable policy improvement. We evaluate our method on three real-world manipulation tasks, including smartphone packing as a high-precision task, laundry folding as a long-horizon deformable-object task, and bimanual pick-and-place involving multi-object perception. Across all tasks, ALOE improves learning efficiency without compromising execution speed, showing that off-policy RL can be reintroduced in a reliable manner for real-world VLA post-training. Videos and additional materials are available at our project website.
Affinity Contrastive Learning for Skeleton-based Human Activity Understanding
Jan 23, 2026In skeleton-based human activity understanding, existing methods often adopt the contrastive learning paradigm to construct a discriminative feature space. However, many of these approaches fail to exploit the structural inter-class similarities and overlook the impact of anomalous positive samples. In this study, we introduce ACLNet, an Affinity Contrastive Learning Network that explores the intricate clustering relationships among human activity classes to improve feature discrimination. Specifically, we propose an affinity metric to refine similarity measurements, thereby forming activity superclasses that provide more informative contrastive signals. A dynamic temperature schedule is also introduced to adaptively adjust the penalty strength for various superclasses. In addition, we employ a margin-based contrastive strategy to improve the separation of hard positive and negative samples within classes. Extensive experiments on NTU RGB+D 60, NTU RGB+D 120, Kinetics-Skeleton, PKU-MMD, FineGYM, and CASIA-B demonstrate the superiority of our method in skeleton-based action recognition, gait recognition, and person re-identification. The source code is available at https://github.com/firework8/ACLNet.
* Accepted by TBIOM
TACFN: Transformer-based Adaptive Cross-modal Fusion Network for Multimodal Emotion Recognition
May 10, 2025The fusion technique is the key to the multimodal emotion recognition task. Recently, cross-modal attention-based fusion methods have demonstrated high performance and strong robustness. However, cross-modal attention suffers from redundant features and does not capture complementary features well. We find that it is not necessary to use the entire information of one modality to reinforce the other during cross-modal interaction, and the features that can reinforce a modality may contain only a part of it. To this end, we design an innovative Transformer-based Adaptive Cross-modal Fusion Network (TACFN). Specifically, for the redundant features, we make one modality perform intra-modal feature selection through a self-attention mechanism, so that the selected features can adaptively and efficiently interact with another modality. To better capture the complementary information between the modalities, we obtain the fused weight vector by splicing and use the weight vector to achieve feature reinforcement of the modalities. We apply TCAFN to the RAVDESS and IEMOCAP datasets. For fair comparison, we use the same unimodal representations to validate the effectiveness of the proposed fusion method. The experimental results show that TACFN brings a significant performance improvement compared to other methods and reaches the state-of-the-art. All code and models could be accessed from https://github.com/shuzihuaiyu/TACFN.
Embodied Crowd Counting
Mar 11, 2025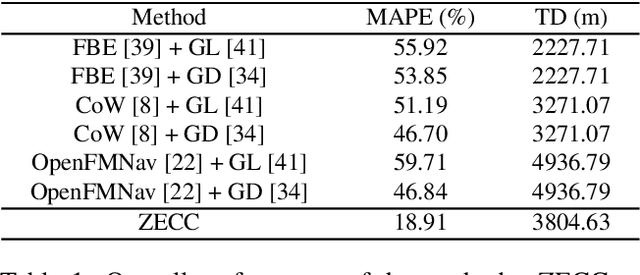
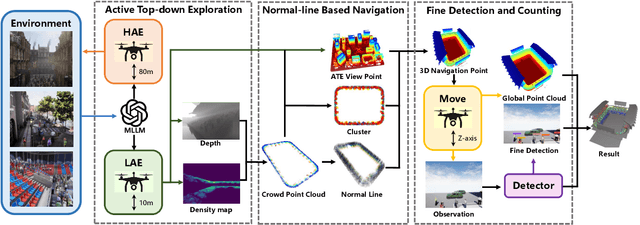


Occlusion is one of the fundamental challenges in crowd counting. In the community, various data-driven approaches have been developed to address this issue, yet their effectiveness is limited. This is mainly because most existing crowd counting datasets on which the methods are trained are based on passive cameras, restricting their ability to fully sense the environment. Recently, embodied navigation methods have shown significant potential in precise object detection in interactive scenes. These methods incorporate active camera settings, holding promise in addressing the fundamental issues in crowd counting. However, most existing methods are designed for indoor navigation, showing unknown performance in analyzing complex object distribution in large scale scenes, such as crowds. Besides, most existing embodied navigation datasets are indoor scenes with limited scale and object quantity, preventing them from being introduced into dense crowd analysis. Based on this, a novel task, Embodied Crowd Counting (ECC), is proposed. We first build up an interactive simulator, Embodied Crowd Counting Dataset (ECCD), which enables large scale scenes and large object quantity. A prior probability distribution that approximates realistic crowd distribution is introduced to generate crowds. Then, a zero-shot navigation method (ZECC) is proposed. This method contains a MLLM driven coarse-to-fine navigation mechanism, enabling active Z-axis exploration, and a normal-line-based crowd distribution analysis method for fine counting. Experimental results against baselines show that the proposed method achieves the best trade-off between counting accuracy and navigation cost.
SeCap: Self-Calibrating and Adaptive Prompts for Cross-view Person Re-Identification in Aerial-Ground Networks
Mar 10, 2025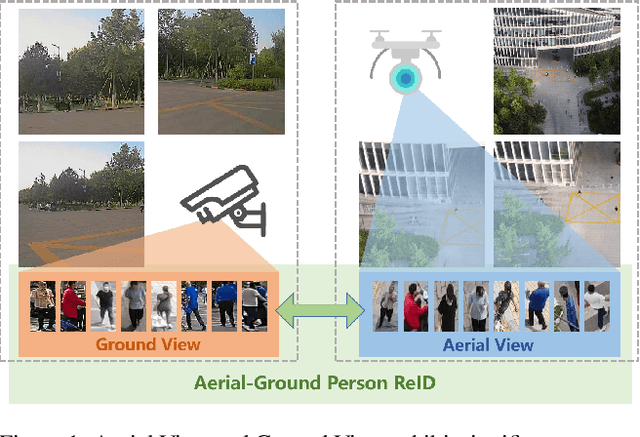
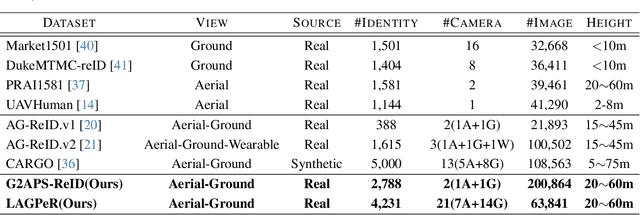
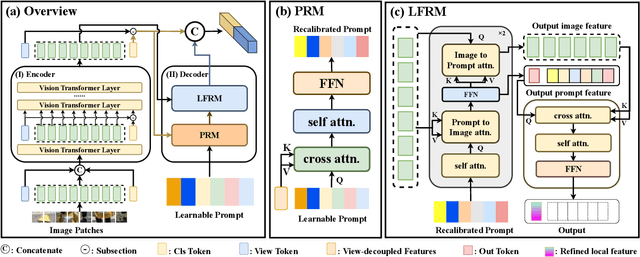
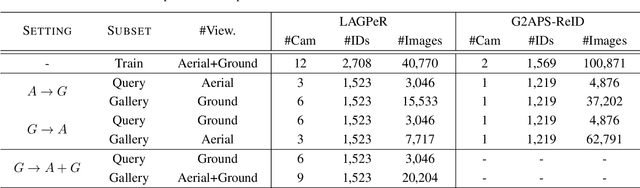
When discussing the Aerial-Ground Person Re-identification (AGPReID) task, we face the main challenge of the significant appearance variations caused by different viewpoints, making identity matching difficult. To address this issue, previous methods attempt to reduce the differences between viewpoints by critical attributes and decoupling the viewpoints. While these methods can mitigate viewpoint differences to some extent, they still face two main issues: (1) difficulty in handling viewpoint diversity and (2) neglect of the contribution of local features. To effectively address these challenges, we design and implement the Self-Calibrating and Adaptive Prompt (SeCap) method for the AGPReID task. The core of this framework relies on the Prompt Re-calibration Module (PRM), which adaptively re-calibrates prompts based on the input. Combined with the Local Feature Refinement Module (LFRM), SeCap can extract view-invariant features from local features for AGPReID. Meanwhile, given the current scarcity of datasets in the AGPReID field, we further contribute two real-world Large-scale Aerial-Ground Person Re-Identification datasets, LAGPeR and G2APS-ReID. The former is collected and annotated by us independently, covering $4,231$ unique identities and containing $63,841$ high-quality images; the latter is reconstructed from the person search dataset G2APS. Through extensive experiments on AGPReID datasets, we demonstrate that SeCap is a feasible and effective solution for the AGPReID task. The datasets and source code available on https://github.com/wangshining681/SeCap-AGPReID.
LEGO-Motion: Learning-Enhanced Grids with Occupancy Instance Modeling for Class-Agnostic Motion Prediction
Mar 10, 2025



Accurate and reliable spatial and motion information plays a pivotal role in autonomous driving systems. However, object-level perception models struggle with handling open scenario categories and lack precise intrinsic geometry. On the other hand, occupancy-based class-agnostic methods excel in representing scenes but fail to ensure physics consistency and ignore the importance of interactions between traffic participants, hindering the model's ability to learn accurate and reliable motion. In this paper, we introduce a novel occupancy-instance modeling framework for class-agnostic motion prediction tasks, named LEGO-Motion, which incorporates instance features into Bird's Eye View (BEV) space. Our model comprises (1) a BEV encoder, (2) an Interaction-Augmented Instance Encoder, and (3) an Instance-Enhanced BEV Encoder, improving both interaction relationships and physics consistency within the model, thereby ensuring a more accurate and robust understanding of the environment. Extensive experiments on the nuScenes dataset demonstrate that our method achieves state-of-the-art performance, outperforming existing approaches. Furthermore, the effectiveness of our framework is validated on the advanced FMCW LiDAR benchmark, showcasing its practical applicability and generalization capabilities. The code will be made publicly available to facilitate further research.