 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving
May 21, 2025



Vision-Language Models (VLMs) show promise for autonomous driving, yet their struggle with hallucinations, inefficient reasoning, and limited real-world validation hinders accurate perception and robust step-by-step reasoning. To overcome this, we introduce \textbf{AgentThink}, a pioneering unified framework that, for the first time, integrates Chain-of-Thought (CoT) reasoning with dynamic, agent-style tool invocation for autonomous driving tasks. AgentThink's core innovations include: \textbf{(i) Structured Data Generation}, by establishing an autonomous driving tool library to automatically construct structured, self-verified reasoning data explicitly incorporating tool usage for diverse driving scenarios; \textbf{(ii) A Two-stage Training Pipeline}, employing Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO) to equip VLMs with the capability for autonomous tool invocation; and \textbf{(iii) Agent-style Tool-Usage Evaluation}, introducing a novel multi-tool assessment protocol to rigorously evaluate the model's tool invocation and utilization. Experiments on the DriveLMM-o1 benchmark demonstrate AgentThink significantly boosts overall reasoning scores by \textbf{53.91\%} and enhances answer accuracy by \textbf{33.54\%}, while markedly improving reasoning quality and consistency. Furthermore, ablation studies and robust zero-shot/few-shot generalization experiments across various benchmarks underscore its powerful capabilities. These findings highlight a promising trajectory for developing trustworthy and tool-aware autonomous driving models.
FASIONAD++ : Integrating High-Level Instruction and Information Bottleneck in FAt-Slow fusION Systems for Enhanced Safety in Autonomous Driving with Adaptive Feedback
Mar 11, 2025



Ensuring safe, comfortable, and efficient planning is crucial for autonomous driving systems. While end-to-end models trained on large datasets perform well in standard driving scenarios, they struggle with complex low-frequency events. Recent Large Language Models (LLMs) and Vision Language Models (VLMs) advancements offer enhanced reasoning but suffer from computational inefficiency. Inspired by the dual-process cognitive model "Thinking, Fast and Slow", we propose $\textbf{FASIONAD}$ -- a novel dual-system framework that synergizes a fast end-to-end planner with a VLM-based reasoning module. The fast system leverages end-to-end learning to achieve real-time trajectory generation in common scenarios, while the slow system activates through uncertainty estimation to perform contextual analysis and complex scenario resolution. Our architecture introduces three key innovations: (1) A dynamic switching mechanism enabling slow system intervention based on real-time uncertainty assessment; (2) An information bottleneck with high-level plan feedback that optimizes the slow system's guidance capability; (3) A bidirectional knowledge exchange where visual prompts enhance the slow system's reasoning while its feedback refines the fast planner's decision-making. To strengthen VLM reasoning, we develop a question-answering mechanism coupled with reward-instruct training strategy. In open-loop experiments, FASIONAD achieves a $6.7\%$ reduction in average $L2$ trajectory error and $28.1\%$ lower collision rate.
LEGO-Motion: Learning-Enhanced Grids with Occupancy Instance Modeling for Class-Agnostic Motion Prediction
Mar 10, 2025



Accurate and reliable spatial and motion information plays a pivotal role in autonomous driving systems. However, object-level perception models struggle with handling open scenario categories and lack precise intrinsic geometry. On the other hand, occupancy-based class-agnostic methods excel in representing scenes but fail to ensure physics consistency and ignore the importance of interactions between traffic participants, hindering the model's ability to learn accurate and reliable motion. In this paper, we introduce a novel occupancy-instance modeling framework for class-agnostic motion prediction tasks, named LEGO-Motion, which incorporates instance features into Bird's Eye View (BEV) space. Our model comprises (1) a BEV encoder, (2) an Interaction-Augmented Instance Encoder, and (3) an Instance-Enhanced BEV Encoder, improving both interaction relationships and physics consistency within the model, thereby ensuring a more accurate and robust understanding of the environment. Extensive experiments on the nuScenes dataset demonstrate that our method achieves state-of-the-art performance, outperforming existing approaches. Furthermore, the effectiveness of our framework is validated on the advanced FMCW LiDAR benchmark, showcasing its practical applicability and generalization capabilities. The code will be made publicly available to facilitate further research.
PriorMotion: Generative Class-Agnostic Motion Prediction with Raster-Vector Motion Field Priors
Dec 05, 2024Reliable perception of spatial and motion information is crucial for safe autonomous navigation. Traditional approaches typically fall into two categories: object-centric and class-agnostic methods. While object-centric methods often struggle with missed detections, leading to inaccuracies in motion prediction, many class-agnostic methods focus heavily on encoder design, often overlooking important priors like rigidity and temporal consistency, leading to suboptimal performance, particularly with sparse LiDAR data at distant region. To address these issues, we propose $\textbf{PriorMotion}$, a generative framework that extracts rasterized and vectorized scene representations to model spatio-temporal priors. Our model comprises a BEV encoder, an Raster-Vector prior Encoder, and a Spatio-Temporal prior Generator, improving both spatial and temporal consistency in motion prediction. Additionally, we introduce a standardized evaluation protocol for class-agnostic motion prediction. Experiments on the nuScenes dataset show that PriorMotion achieves state-of-the-art performance, with further validation on advanced FMCW LiDAR confirming its robustness.
FASIONAD : FAst and Slow FusION Thinking Systems for Human-Like Autonomous Driving with Adaptive Feedback
Nov 27, 2024



Ensuring safe, comfortable, and efficient navigation is a critical goal for autonomous driving systems. While end-to-end models trained on large-scale datasets excel in common driving scenarios, they often struggle with rare, long-tail events. Recent progress in large language models (LLMs) has introduced enhanced reasoning capabilities, but their computational demands pose challenges for real-time decision-making and precise planning. This paper presents FASIONAD, a novel dual-system framework inspired by the cognitive model "Thinking, Fast and Slow." The fast system handles routine navigation tasks using rapid, data-driven path planning, while the slow system focuses on complex reasoning and decision-making in challenging or unfamiliar situations. A dynamic switching mechanism based on score distribution and feedback allows seamless transitions between the two systems. Visual prompts generated by the fast system enable human-like reasoning in the slow system, which provides high-quality feedback to enhance the fast system's decision-making. To evaluate FASIONAD, we introduce a new benchmark derived from the nuScenes dataset, specifically designed to differentiate fast and slow scenarios. FASIONAD achieves state-of-the-art performance on this benchmark, establishing a new standard for frameworks integrating fast and slow cognitive processes in autonomous driving. This approach paves the way for more adaptive, human-like autonomous driving systems.
Enhancing Lane Segment Perception and Topology Reasoning with Crowdsourcing Trajectory Priors
Nov 26, 2024In autonomous driving, recent advances in lane segment perception provide autonomous vehicles with a comprehensive understanding of driving scenarios. Moreover, incorporating prior information input into such perception model represents an effective approach to ensure the robustness and accuracy. However, utilizing diverse sources of prior information still faces three key challenges: the acquisition of high-quality prior information, alignment between prior and online perception, efficient integration. To address these issues, we investigate prior augmentation from a novel perspective of trajectory priors. In this paper, we initially extract crowdsourcing trajectory data from Argoverse2 motion forecasting dataset and encode trajectory data into rasterized heatmap and vectorized instance tokens, then we incorporate such prior information into the online mapping model through different ways. Besides, with the purpose of mitigating the misalignment between prior and online perception, we design a confidence-based fusion module that takes alignment into account during the fusion process. We conduct extensive experiments on OpenLane-V2 dataset. The results indicate that our method's performance significantly outperforms the current state-of-the-art methods.
DiffMap: Enhancing Map Segmentation with Map Prior Using Diffusion Model
May 03, 2024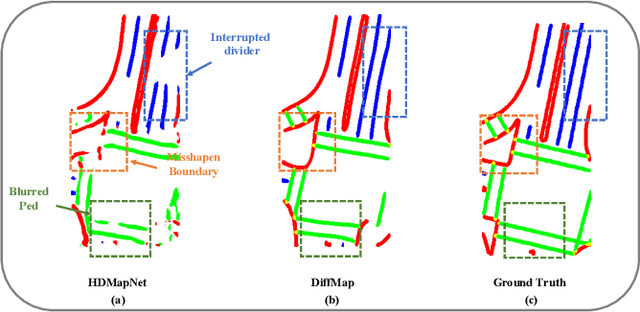
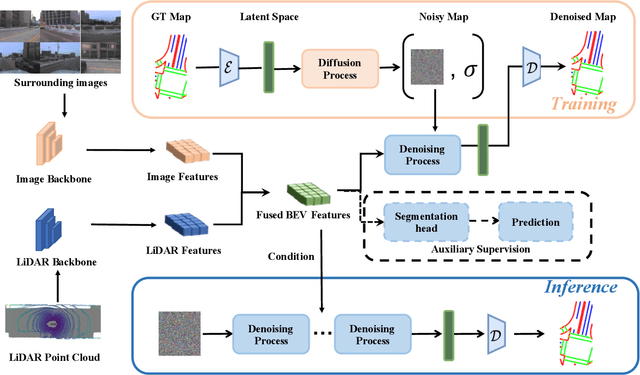
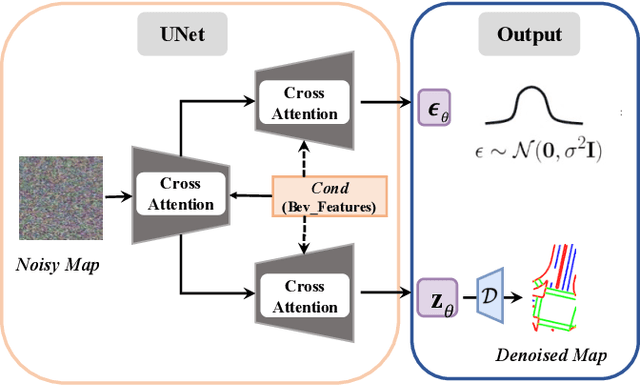

Constructing high-definition (HD) maps is a crucial requirement for enabling autonomous driving. In recent years, several map segmentation algorithms have been developed to address this need, leveraging advancements in Bird's-Eye View (BEV) perception. However, existing models still encounter challenges in producing realistic and consistent semantic map layouts. One prominent issue is the limited utilization of structured priors inherent in map segmentation masks. In light of this, we propose DiffMap, a novel approach specifically designed to model the structured priors of map segmentation masks using latent diffusion model. By incorporating this technique, the performance of existing semantic segmentation methods can be significantly enhanced and certain structural errors present in the segmentation outputs can be effectively rectified. Notably, the proposed module can be seamlessly integrated into any map segmentation model, thereby augmenting its capability to accurately delineate semantic information. Furthermore, through extensive visualization analysis, our model demonstrates superior proficiency in generating results that more accurately reflect real-world map layouts, further validating its efficacy in improving the quality of the generated maps.