 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
Mar 28, 2026Understanding charts requires models to jointly reason over geometric visual patterns, structured numerical data, and natural language -- a capability where current vision-language models (VLMs) remain limited. We introduce ChartNet, a high-quality, million-scale multimodal dataset designed to advance chart interpretation and reasoning. ChartNet leverages a novel code-guided synthesis pipeline to generate 1.5 million diverse chart samples spanning 24 chart types and 6 plotting libraries. Each sample consists of five aligned components: plotting code, rendered chart image, data table, natural language summary, and question-answering with reasoning, providing fine-grained cross-modal alignment. To capture the full spectrum of chart comprehension, ChartNet additionally includes specialized subsets encompassing human annotated data, real-world data, safety, and grounding. Moreover, a rigorous quality-filtering pipeline ensures visual fidelity, semantic accuracy, and diversity across chart representations. Fine-tuning on ChartNet consistently improves results across benchmarks, demonstrating its utility as large-scale supervision for multimodal models. As the largest open-source dataset of its kind, ChartNet aims to support the development of foundation models with robust and generalizable capabilities for data visualization understanding. The dataset is publicly available at https://huggingface.co/datasets/ibm-granite/ChartNet
DriveVLM-RL: Neuroscience-Inspired Reinforcement Learning with Vision-Language Models for Safe and Deployable Autonomous Driving
Mar 18, 2026Ensuring safe decision-making in autonomous vehicles remains a fundamental challenge despite rapid advances in end-to-end learning approaches. Traditional reinforcement learning (RL) methods rely on manually engineered rewards or sparse collision signals, which fail to capture the rich contextual understanding required for safe driving and make unsafe exploration unavoidable in real-world settings. Recent vision-language models (VLMs) offer promising semantic understanding capabilities; however, their high inference latency and susceptibility to hallucination hinder direct application to real-time vehicle control. To address these limitations, this paper proposes DriveVLM-RL, a neuroscience-inspired framework that integrates VLMs into RL through a dual-pathway architecture for safe and deployable autonomous driving. The framework decomposes semantic reward learning into a Static Pathway for continuous spatial safety assessment using CLIP-based contrasting language goals, and a Dynamic Pathway for attention-gated multi-frame semantic risk reasoning using a lightweight detector and a large VLM. A hierarchical reward synthesis mechanism fuses semantic signals with vehicle states, while an asynchronous training pipeline decouples expensive VLM inference from environment interaction. All VLM components are used only during offline training and are removed at deployment, ensuring real-time feasibility. Experiments in the CARLA simulator show significant improvements in collision avoidance, task success, and generalization across diverse traffic scenarios, including strong robustness under settings without explicit collision penalties. These results demonstrate that DriveVLM-RL provides a practical paradigm for integrating foundation models into autonomous driving without compromising real-time feasibility. Demo video and code are available at: https://zilin-huang.github.io/DriveVLM-RL-website/
AgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving
May 21, 2025



Vision-Language Models (VLMs) show promise for autonomous driving, yet their struggle with hallucinations, inefficient reasoning, and limited real-world validation hinders accurate perception and robust step-by-step reasoning. To overcome this, we introduce \textbf{AgentThink}, a pioneering unified framework that, for the first time, integrates Chain-of-Thought (CoT) reasoning with dynamic, agent-style tool invocation for autonomous driving tasks. AgentThink's core innovations include: \textbf{(i) Structured Data Generation}, by establishing an autonomous driving tool library to automatically construct structured, self-verified reasoning data explicitly incorporating tool usage for diverse driving scenarios; \textbf{(ii) A Two-stage Training Pipeline}, employing Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO) to equip VLMs with the capability for autonomous tool invocation; and \textbf{(iii) Agent-style Tool-Usage Evaluation}, introducing a novel multi-tool assessment protocol to rigorously evaluate the model's tool invocation and utilization. Experiments on the DriveLMM-o1 benchmark demonstrate AgentThink significantly boosts overall reasoning scores by \textbf{53.91\%} and enhances answer accuracy by \textbf{33.54\%}, while markedly improving reasoning quality and consistency. Furthermore, ablation studies and robust zero-shot/few-shot generalization experiments across various benchmarks underscore its powerful capabilities. These findings highlight a promising trajectory for developing trustworthy and tool-aware autonomous driving models.
FASIONAD++ : Integrating High-Level Instruction and Information Bottleneck in FAt-Slow fusION Systems for Enhanced Safety in Autonomous Driving with Adaptive Feedback
Mar 11, 2025



Ensuring safe, comfortable, and efficient planning is crucial for autonomous driving systems. While end-to-end models trained on large datasets perform well in standard driving scenarios, they struggle with complex low-frequency events. Recent Large Language Models (LLMs) and Vision Language Models (VLMs) advancements offer enhanced reasoning but suffer from computational inefficiency. Inspired by the dual-process cognitive model "Thinking, Fast and Slow", we propose $\textbf{FASIONAD}$ -- a novel dual-system framework that synergizes a fast end-to-end planner with a VLM-based reasoning module. The fast system leverages end-to-end learning to achieve real-time trajectory generation in common scenarios, while the slow system activates through uncertainty estimation to perform contextual analysis and complex scenario resolution. Our architecture introduces three key innovations: (1) A dynamic switching mechanism enabling slow system intervention based on real-time uncertainty assessment; (2) An information bottleneck with high-level plan feedback that optimizes the slow system's guidance capability; (3) A bidirectional knowledge exchange where visual prompts enhance the slow system's reasoning while its feedback refines the fast planner's decision-making. To strengthen VLM reasoning, we develop a question-answering mechanism coupled with reward-instruct training strategy. In open-loop experiments, FASIONAD achieves a $6.7\%$ reduction in average $L2$ trajectory error and $28.1\%$ lower collision rate.
Adversarial Vulnerabilities in Large Language Models for Time Series Forecasting
Dec 11, 2024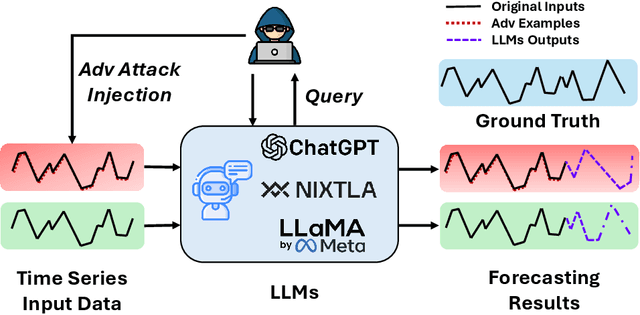
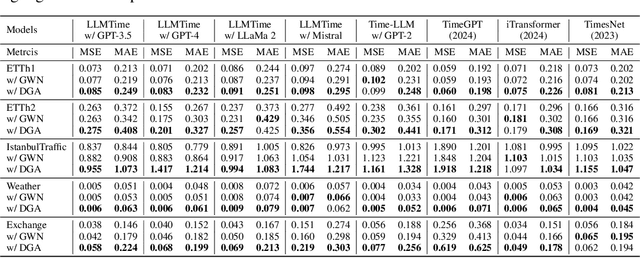
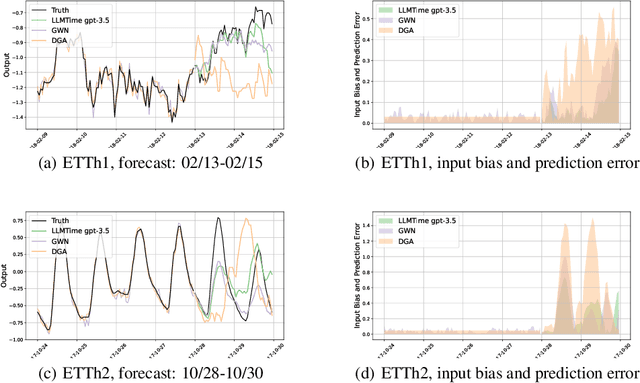
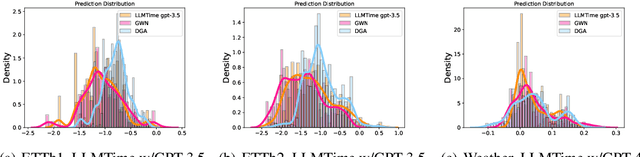
Large Language Models (LLMs) have recently demonstrated significant potential in the field of time series forecasting, offering impressive capabilities in handling complex temporal data. However, their robustness and reliability in real-world applications remain under-explored, particularly concerning their susceptibility to adversarial attacks. In this paper, we introduce a targeted adversarial attack framework for LLM-based time series forecasting. By employing both gradient-free and black-box optimization methods, we generate minimal yet highly effective perturbations that significantly degrade the forecasting accuracy across multiple datasets and LLM architectures. Our experiments, which include models like TimeGPT and LLM-Time with GPT-3.5, GPT-4, LLaMa, and Mistral, show that adversarial attacks lead to much more severe performance degradation than random noise, and demonstrate the broad effectiveness of our attacks across different LLMs. The results underscore the critical vulnerabilities of LLMs in time series forecasting, highlighting the need for robust defense mechanisms to ensure their reliable deployment in practical applications.
Communication-Aware Reinforcement Learning for Cooperative Adaptive Cruise Control
Jul 12, 2024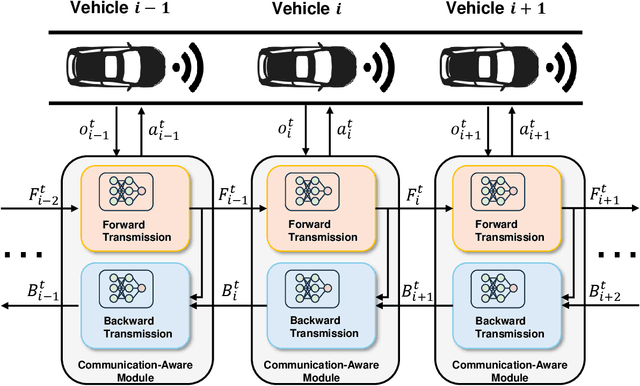
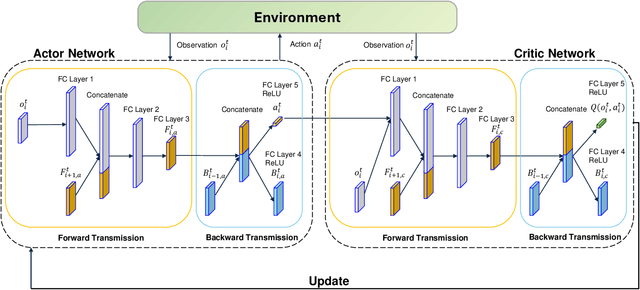
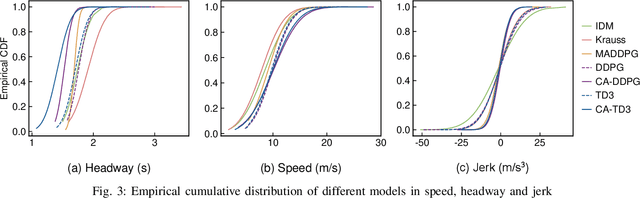
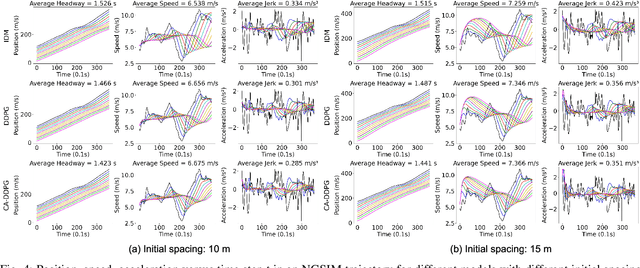
Cooperative Adaptive Cruise Control (CACC) plays a pivotal role in enhancing traffic efficiency and safety in Connected and Autonomous Vehicles (CAVs). Reinforcement Learning (RL) has proven effective in optimizing complex decision-making processes in CACC, leading to improved system performance and adaptability. Among RL approaches, Multi-Agent Reinforcement Learning (MARL) has shown remarkable potential by enabling coordinated actions among multiple CAVs through Centralized Training with Decentralized Execution (CTDE). However, MARL often faces scalability issues, particularly when CACC vehicles suddenly join or leave the platoon, resulting in performance degradation. To address these challenges, we propose Communication-Aware Reinforcement Learning (CA-RL). CA-RL includes a communication-aware module that extracts and compresses vehicle communication information through forward and backward information transmission modules. This enables efficient cyclic information propagation within the CACC traffic flow, ensuring policy consistency and mitigating the scalability problems of MARL in CACC. Experimental results demonstrate that CA-RL significantly outperforms baseline methods in various traffic scenarios, achieving superior scalability, robustness, and overall system performance while maintaining reliable performance despite changes in the number of participating vehicles.
LiveQA: A Question Answering Dataset over Sports Live
Oct 01, 2020
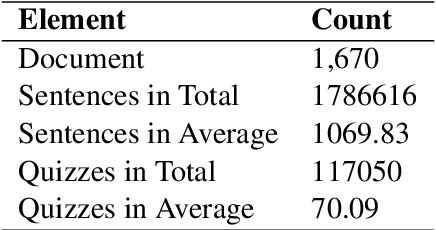

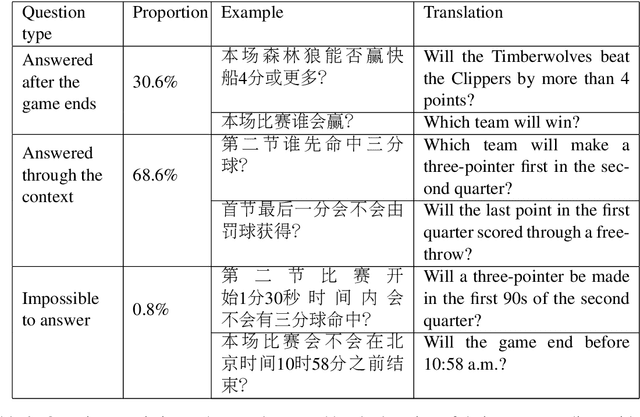
In this paper, we introduce LiveQA, a new question answering dataset constructed from play-by-play live broadcast. It contains 117k multiple-choice questions written by human commentators for over 1,670 NBA games, which are collected from the Chinese Hupu (https://nba.hupu.com/games) website. Derived from the characteristics of sports games, LiveQA can potentially test the reasoning ability across timeline-based live broadcasts, which is challenging compared to the existing datasets. In LiveQA, the questions require understanding the timeline, tracking events or doing mathematical computations. Our preliminary experiments show that the dataset introduces a challenging problem for question answering models, and a strong baseline model only achieves the accuracy of 53.1\% and cannot beat the dominant option rule. We release the code and data of this paper for future research.