 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness of LLM-enabled vehicle trajectory prediction under data security threats
Nov 14, 2025The integration of large language models (LLMs) into automated driving systems has opened new possibilities for reasoning and decision-making by transforming complex driving contexts into language-understandable representations. Recent studies demonstrate that fine-tuned LLMs can accurately predict vehicle trajectories and lane-change intentions by gathering and transforming data from surrounding vehicles. However, the robustness of such LLM-based prediction models for safety-critical driving systems remains unexplored, despite the increasing concerns about the trustworthiness of LLMs. This study addresses this gap by conducting a systematic vulnerability analysis of LLM-enabled vehicle trajectory prediction. We propose a one-feature differential evolution attack that perturbs a single kinematic feature of surrounding vehicles within the LLM's input prompts under a black-box setting. Experiments on the highD dataset reveal that even minor, physically plausible perturbations can significantly disrupt model outputs, underscoring the susceptibility of LLM-based predictors to adversarial manipulation. Further analyses reveal a trade-off between accuracy and robustness, examine the failure mechanism, and explore potential mitigation solutions. The findings provide the very first insights into adversarial vulnerabilities of LLM-driven automated vehicle models in the context of vehicular interactions and highlight the need for robustness-oriented design in future LLM-based intelligent transportation systems.
Adversarial Vulnerabilities in Large Language Models for Time Series Forecasting
Dec 11, 2024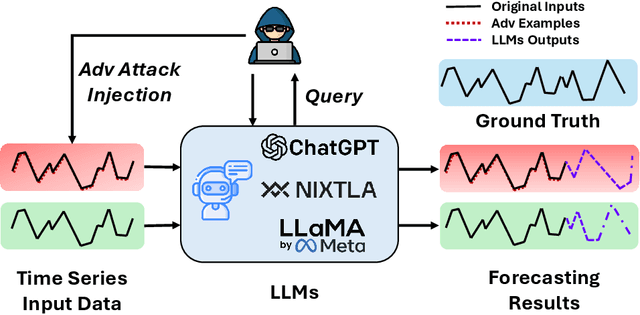
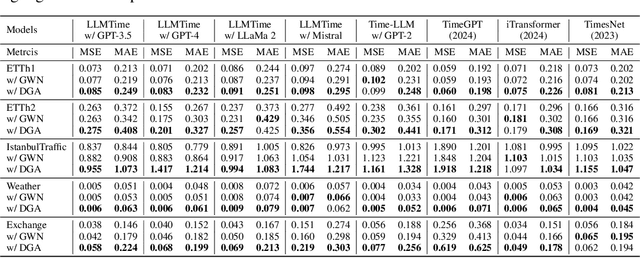
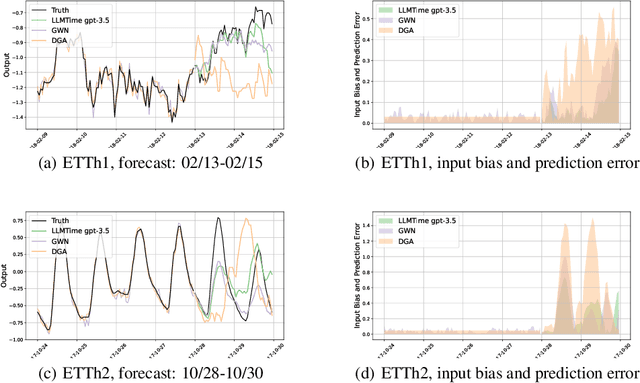
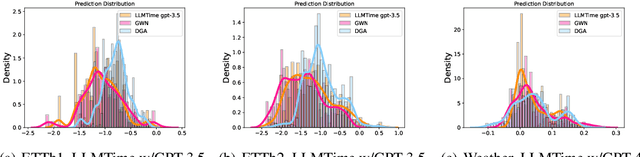
Large Language Models (LLMs) have recently demonstrated significant potential in the field of time series forecasting, offering impressive capabilities in handling complex temporal data. However, their robustness and reliability in real-world applications remain under-explored, particularly concerning their susceptibility to adversarial attacks. In this paper, we introduce a targeted adversarial attack framework for LLM-based time series forecasting. By employing both gradient-free and black-box optimization methods, we generate minimal yet highly effective perturbations that significantly degrade the forecasting accuracy across multiple datasets and LLM architectures. Our experiments, which include models like TimeGPT and LLM-Time with GPT-3.5, GPT-4, LLaMa, and Mistral, show that adversarial attacks lead to much more severe performance degradation than random noise, and demonstrate the broad effectiveness of our attacks across different LLMs. The results underscore the critical vulnerabilities of LLMs in time series forecasting, highlighting the need for robust defense mechanisms to ensure their reliable deployment in practical applications.
Correlating Time Series with Interpretable Convolutional Kernels
Sep 02, 2024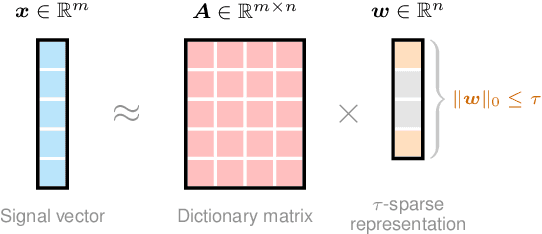



This study addresses the problem of convolutional kernel learning in univariate, multivariate, and multidimensional time series data, which is crucial for interpreting temporal patterns in time series and supporting downstream machine learning tasks. First, we propose formulating convolutional kernel learning for univariate time series as a sparse regression problem with a non-negative constraint, leveraging the properties of circular convolution and circulant matrices. Second, to generalize this approach to multivariate and multidimensional time series data, we use tensor computations, reformulating the convolutional kernel learning problem in the form of tensors. This is further converted into a standard sparse regression problem through vectorization and tensor unfolding operations. In the proposed methodology, the optimization problem is addressed using the existing non-negative subspace pursuit method, enabling the convolutional kernel to capture temporal correlations and patterns. To evaluate the proposed model, we apply it to several real-world time series datasets. On the multidimensional rideshare and taxi trip data from New York City and Chicago, the convolutional kernels reveal interpretable local correlations and cyclical patterns, such as weekly seasonality. In the context of multidimensional fluid flow data, both local and nonlocal correlations captured by the convolutional kernels can reinforce tensor factorization, leading to performance improvements in fluid flow reconstruction tasks. Thus, this study lays an insightful foundation for automatically learning convolutional kernels from time series data, with an emphasis on interpretability through sparsity and non-negativity constraints.
Energy-Efficient Clustered Cell-Free Networking with Access Point Selection
Mar 01, 2024Ultra-densely deploying access points (APs) to support the increasing data traffic would significantly escalate the cell-edge problem resulting from traditional cellular networks. By removing the cell boundaries and coordinating all APs for joint transmission, the cell-edge problem can be alleviated, which in turn leads to unaffordable system complexity and channel measurement overhead. A new scalable clustered cell-free network architecture has been proposed recently, under which the large-scale network is flexibly partitioned into a set of independent subnetworks operating parallelly. In this paper, we study the energy-efficient clustered cell-free networking problem with AP selection. Specifically, we propose a user-centric ratio-fixed AP-selection based clustering (UCR-ApSel) algorithm to form subnetworks dynamically. Following this, we analyze the average energy efficiency achieved with the proposed UCR-ApSel scheme theoretically and derive an effective closed-form upper-bound. Based on the analytical upper-bound expression, the optimal AP-selection ratio that maximizes the average energy efficiency is further derived as a simple explicit function of the total number of APs and the number of subnetworks. Simulation results demonstrate the effectiveness of the derived optimal AP-selection ratio and show that the proposed UCR-ApSel algorithm with the optimal AP-selection ratio achieves around 40% higher energy efficiency than the baselines. The analysis provides important insights to the design and optimization of future ultra-dense wireless communication systems.
Spatially Focused Attack against Spatiotemporal Graph Neural Networks
Sep 10, 2021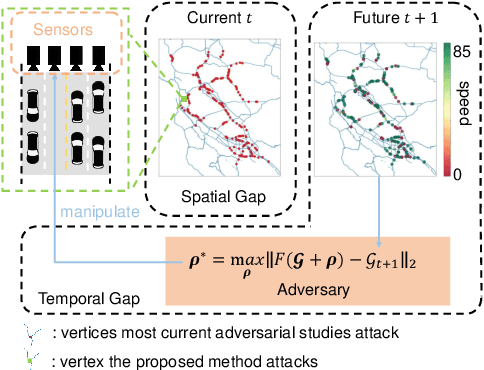
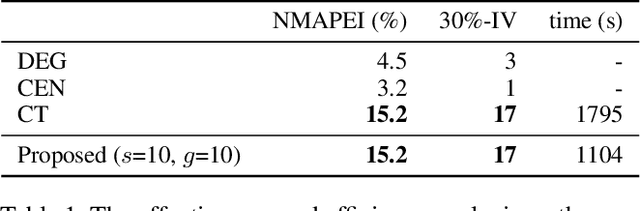
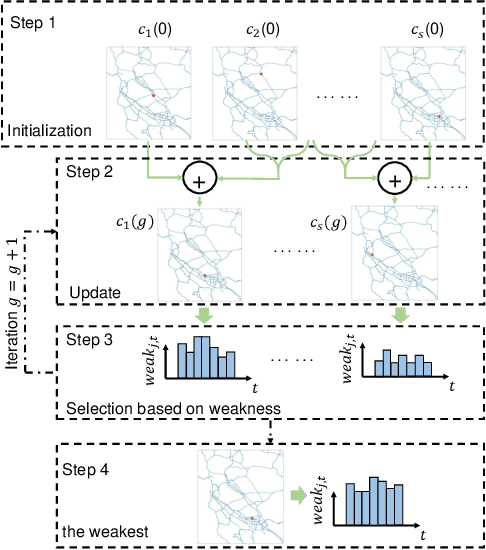
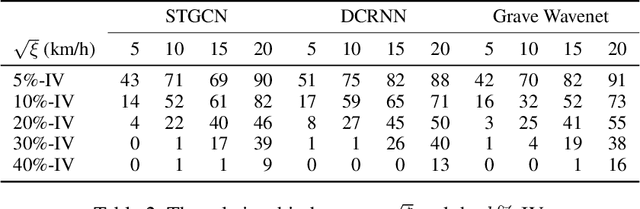
Spatiotemporal forecasting plays an essential role in various applications in intelligent transportation systems (ITS), such as route planning, navigation, and traffic control and management. Deep Spatiotemporal graph neural networks (GNNs), which capture both spatial and temporal patterns, have achieved great success in traffic forecasting applications. Understanding how GNNs-based forecasting work and the vulnerability and robustness of these models becomes critical to real-world applications. For example, if spatiotemporal GNNs are vulnerable in real-world traffic prediction applications, a hacker can easily manipulate the results and cause serious traffic congestion and even a city-scale breakdown. However, despite that recent studies have demonstrated that deep neural networks (DNNs) are vulnerable to carefully designed perturbations in multiple domains like objection classification and graph representation, current adversarial works cannot be directly applied to spatiotemporal forecasting due to the causal nature and spatiotemporal mechanisms in forecasting models. To fill this gap, in this paper we design Spatially Focused Attack (SFA) to break spatiotemporal GNNs by attacking a single vertex. To achieve this, we first propose the inverse estimation to address the causality issue; then, we apply genetic algorithms with a universal attack method as the evaluation function to locate the weakest vertex; finally, perturbations are generated by solving an inverse estimation-based optimization problem. We conduct experiments on real-world traffic data and our results show that perturbations in one vertex designed by SA can be diffused into a large part of the graph.
Polarized Self-Attention: Towards High-quality Pixel-wise Regression
Jul 08, 2021

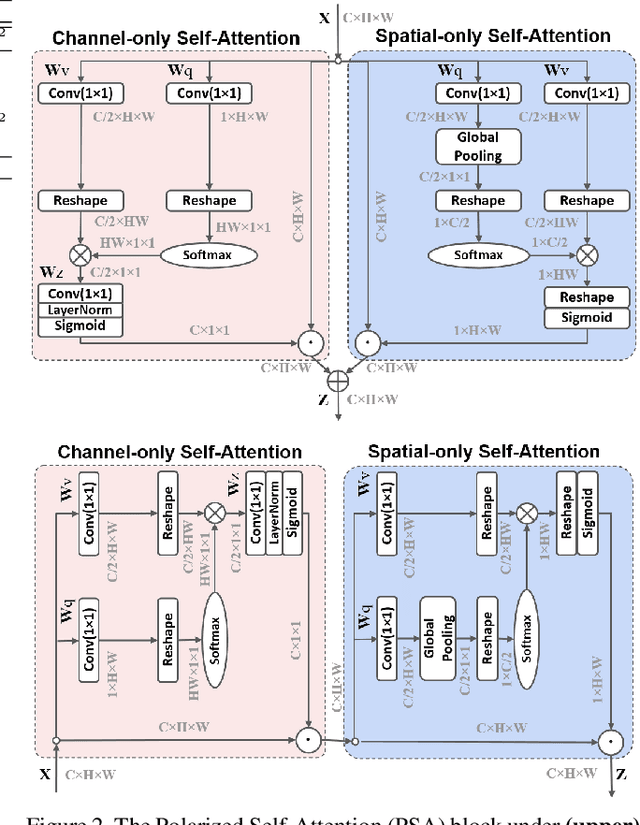

Pixel-wise regression is probably the most common problem in fine-grained computer vision tasks, such as estimating keypoint heatmaps and segmentation masks. These regression problems are very challenging particularly because they require, at low computation overheads, modeling long-range dependencies on high-resolution inputs/outputs to estimate the highly nonlinear pixel-wise semantics. While attention mechanisms in Deep Convolutional Neural Networks(DCNNs) has become popular for boosting long-range dependencies, element-specific attention, such as Nonlocal blocks, is highly complex and noise-sensitive to learn, and most of simplified attention hybrids try to reach the best compromise among multiple types of tasks. In this paper, we present the Polarized Self-Attention(PSA) block that incorporates two critical designs towards high-quality pixel-wise regression: (1) Polarized filtering: keeping high internal resolution in both channel and spatial attention computation while completely collapsing input tensors along their counterpart dimensions. (2) Enhancement: composing non-linearity that directly fits the output distribution of typical fine-grained regression, such as the 2D Gaussian distribution (keypoint heatmaps), or the 2D Binormial distribution (binary segmentation masks). PSA appears to have exhausted the representation capacity within its channel-only and spatial-only branches, such that there is only marginal metric differences between its sequential and parallel layouts. Experimental results show that PSA boosts standard baselines by $2-4$ points, and boosts state-of-the-arts by $1-2$ points on 2D pose estimation and semantic segmentation benchmarks.
Towards Accurate and High-Speed Spiking Neuromorphic Systems with Data Quantization-Aware Deep Networks
May 08, 2018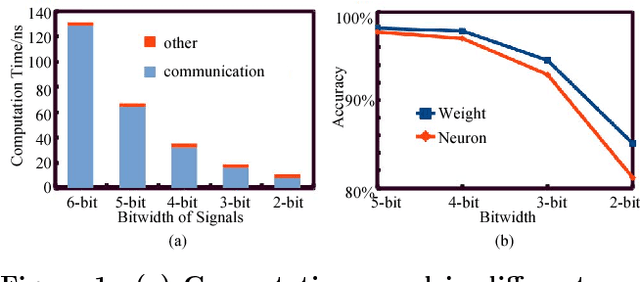

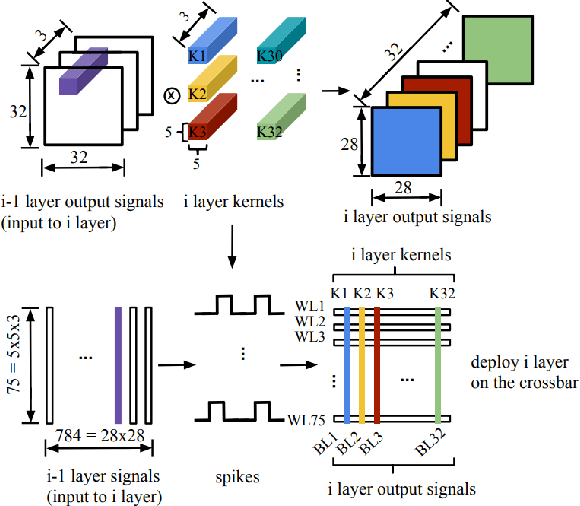

Deep Neural Networks (DNNs) have gained immense success in cognitive applications and greatly pushed today's artificial intelligence forward. The biggest challenge in executing DNNs is their extremely data-extensive computations. The computing efficiency in speed and energy is constrained when traditional computing platforms are employed in such computational hungry executions. Spiking neuromorphic computing (SNC) has been widely investigated in deep networks implementation own to their high efficiency in computation and communication. However, weights and signals of DNNs are required to be quantized when deploying the DNNs on the SNC, which results in unacceptable accuracy loss. %However, the system accuracy is limited by quantizing data directly in deep networks deployment. Previous works mainly focus on weights discretize while inter-layer signals are mainly neglected. In this work, we propose to represent DNNs with fixed integer inter-layer signals and fixed-point weights while holding good accuracy. We implement the proposed DNNs on the memristor-based SNC system as a deployment example. With 4-bit data representation, our results show that the accuracy loss can be controlled within 0.02% (2.3%) on MNIST (CIFAR-10). Compared with the 8-bit dynamic fixed-point DNNs, our system can achieve more than 9.8x speedup, 89.1% energy saving, and 30% area saving.
Boost Picking: A Universal Method on Converting Supervised Classification to Semi-supervised Classification
Nov 12, 2016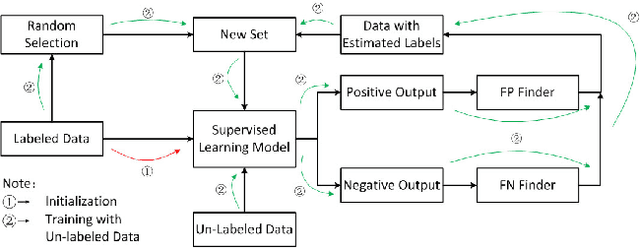
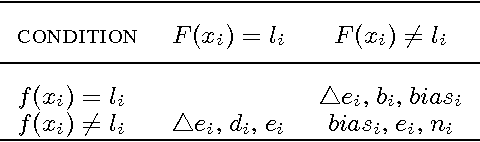
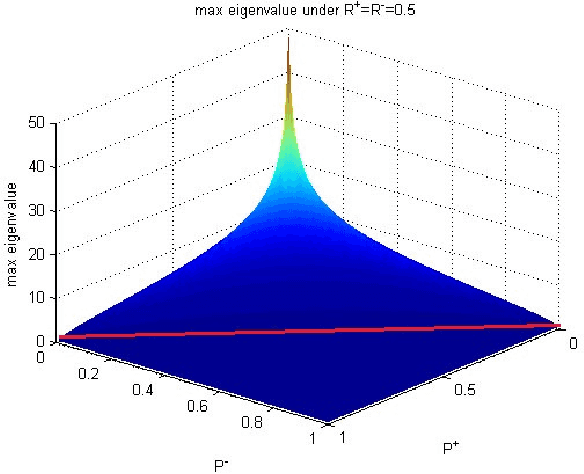

This paper proposes a universal method, Boost Picking, to train supervised classification models mainly by un-labeled data. Boost Picking only adopts two weak classifiers to estimate and correct the error. It is theoretically proved that Boost Picking could train a supervised model mainly by un-labeled data as effectively as the same model trained by 100% labeled data, only if recalls of the two weak classifiers are all greater than zero and the sum of precisions is greater than one. Based on Boost Picking, we present "Test along with Training (TawT)" to improve the generalization of supervised models. Both Boost Picking and TawT are successfully tested in varied little data sets.
Object Recognition Based on Amounts of Unlabeled Data
Mar 25, 2016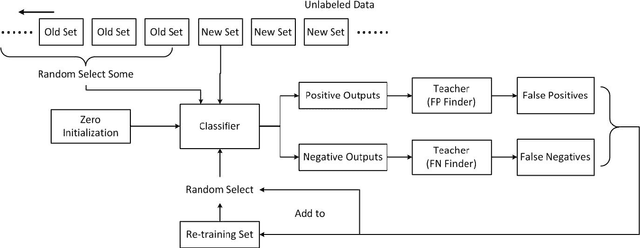

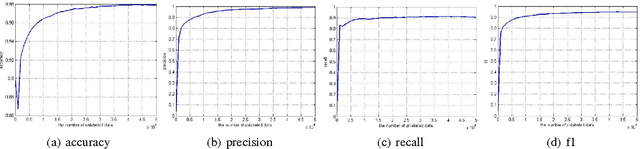
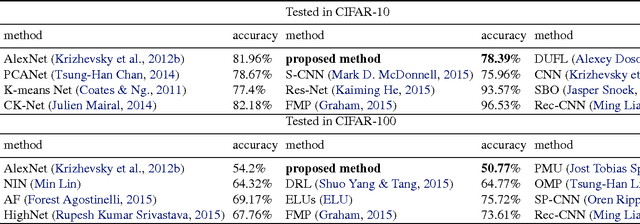
This paper proposes a novel semi-supervised method on object recognition. First, based on Boost Picking, a universal algorithm, Boost Picking Teaching (BPT), is proposed to train an effective binary-classifier just using a few labeled data and amounts of unlabeled data. Then, an ensemble strategy is detailed to synthesize multiple BPT-trained binary-classifiers to be a high-performance multi-classifier. The rationality of the strategy is also analyzed in theory. Finally, the proposed method is tested on two databases, CIFAR-10 and CIFAR-100. Using 2% labeled data and 98% unlabeled data, the accuracies of the proposed method on the two data sets are 78.39% and 50.77% respectively.
Feature-Area Optimization: A Novel SAR Image Registration Method
Feb 18, 2016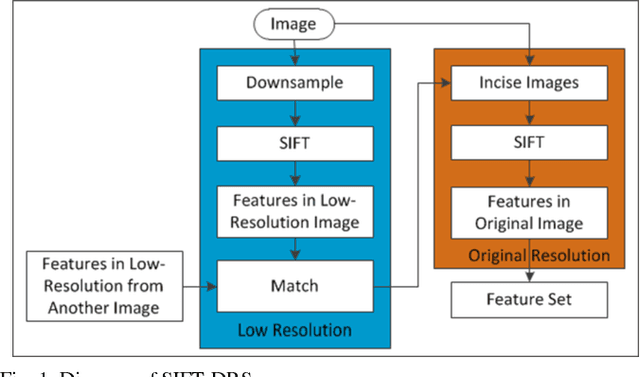
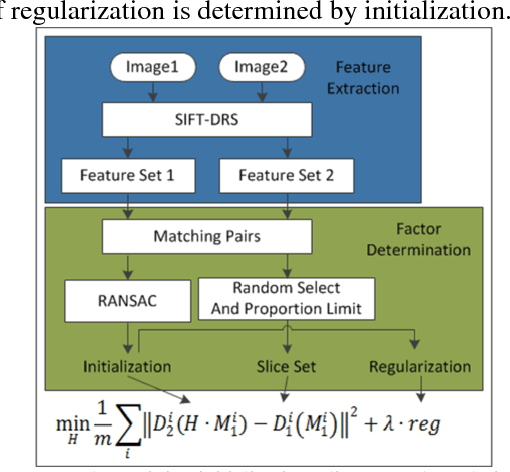
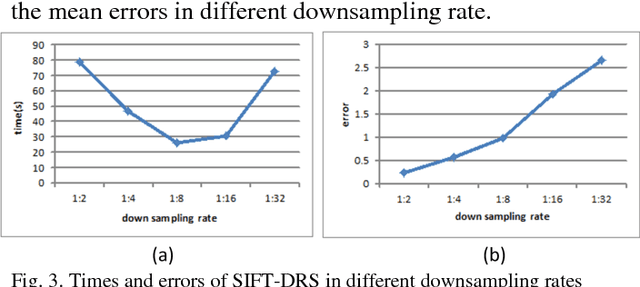
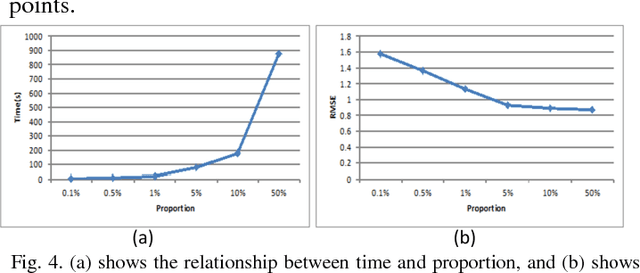
This letter proposes a synthetic aperture radar (SAR) image registration method named Feature-Area Optimization (FAO). First, the traditional area-based optimization model is reconstructed and decomposed into three key but uncertain factors: initialization, slice set and regularization. Next, structural features are extracted by scale invariant feature transform (SIFT) in dual-resolution space (SIFT-DRS), a novel SIFT-Like method dedicated to FAO. Then, the three key factors are determined based on these features. Finally, solving the factor-determined optimization model can get the registration result. A series of experiments demonstrate that the proposed method can register multi-temporal SAR images accurately and efficiently.
* 5 pages, 5 figures