Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoost Picking: A Universal Method on Converting Supervised Classification to Semi-supervised Classification
Paper and Code
Nov 12, 2016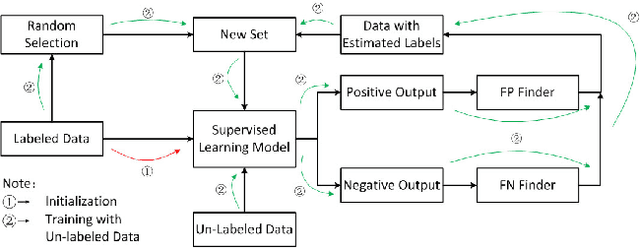
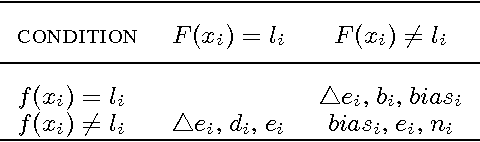
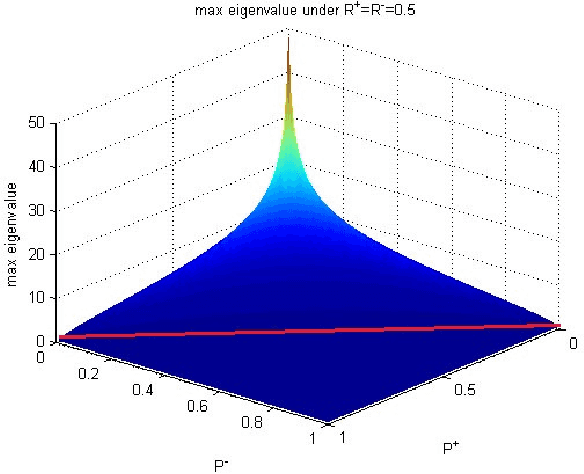

This paper proposes a universal method, Boost Picking, to train supervised classification models mainly by un-labeled data. Boost Picking only adopts two weak classifiers to estimate and correct the error. It is theoretically proved that Boost Picking could train a supervised model mainly by un-labeled data as effectively as the same model trained by 100% labeled data, only if recalls of the two weak classifiers are all greater than zero and the sum of precisions is greater than one. Based on Boost Picking, we present "Test along with Training (TawT)" to improve the generalization of supervised models. Both Boost Picking and TawT are successfully tested in varied little data sets.
* This paper has been withdraw by the author due to format error
View paper on