 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSVideo: Fast Speed Video Diffusion Model in a Highly-Compressed Latent Space
Feb 02, 2026We introduce FSVideo, a fast speed transformer-based image-to-video (I2V) diffusion framework. We build our framework on the following key components: 1.) a new video autoencoder with highly-compressed latent space ($64\times64\times4$ spatial-temporal downsampling ratio), achieving competitive reconstruction quality; 2.) a diffusion transformer (DIT) architecture with a new layer memory design to enhance inter-layer information flow and context reuse within DIT, and 3.) a multi-resolution generation strategy via a few-step DIT upsampler to increase video fidelity. Our final model, which contains a 14B DIT base model and a 14B DIT upsampler, achieves competitive performance against other popular open-source models, while being an order of magnitude faster. We discuss our model design as well as training strategies in this report.
VIVA: VLM-Guided Instruction-Based Video Editing with Reward Optimization
Dec 18, 2025



Instruction-based video editing aims to modify an input video according to a natural-language instruction while preserving content fidelity and temporal coherence. However, existing diffusion-based approaches are often trained on paired data of simple editing operations, which fundamentally limits their ability to generalize to diverse and complex, real-world instructions. To address this generalization gap, we propose VIVA, a scalable framework for instruction-based video editing that leverages VLM-guided encoding and reward optimization. First, we introduce a VLM-based instructor that encodes the textual instruction, the first frame of the source video, and an optional reference image into visually-grounded instruction representations, providing fine-grained spatial and semantic context for the diffusion transformer backbone. Second, we propose a post-training stage, Edit-GRPO, which adapts Group Relative Policy Optimization to the domain of video editing, directly optimizing the model for instruction-faithful, content-preserving, and aesthetically pleasing edits using relative rewards. Furthermore, we propose a data construction pipeline designed to synthetically generate diverse, high-fidelity paired video-instruction data of basic editing operations. Extensive experiments show that VIVA achieves superior instruction following, generalization, and editing quality over state-of-the-art methods. Website: https://viva-paper.github.io
MAGREF: Masked Guidance for Any-Reference Video Generation
May 29, 2025Video generation has made substantial strides with the emergence of deep generative models, especially diffusion-based approaches. However, video generation based on multiple reference subjects still faces significant challenges in maintaining multi-subject consistency and ensuring high generation quality. In this paper, we propose MAGREF, a unified framework for any-reference video generation that introduces masked guidance to enable coherent multi-subject video synthesis conditioned on diverse reference images and a textual prompt. Specifically, we propose (1) a region-aware dynamic masking mechanism that enables a single model to flexibly handle various subject inference, including humans, objects, and backgrounds, without architectural changes, and (2) a pixel-wise channel concatenation mechanism that operates on the channel dimension to better preserve appearance features. Our model delivers state-of-the-art video generation quality, generalizing from single-subject training to complex multi-subject scenarios with coherent synthesis and precise control over individual subjects, outperforming existing open-source and commercial baselines. To facilitate evaluation, we also introduce a comprehensive multi-subject video benchmark. Extensive experiments demonstrate the effectiveness of our approach, paving the way for scalable, controllable, and high-fidelity multi-subject video synthesis. Code and model can be found at: https://github.com/MAGREF-Video/MAGREF
ATI: Any Trajectory Instruction for Controllable Video Generation
May 28, 2025We propose a unified framework for motion control in video generation that seamlessly integrates camera movement, object-level translation, and fine-grained local motion using trajectory-based inputs. In contrast to prior methods that address these motion types through separate modules or task-specific designs, our approach offers a cohesive solution by projecting user-defined trajectories into the latent space of pre-trained image-to-video generation models via a lightweight motion injector. Users can specify keypoints and their motion paths to control localized deformations, entire object motion, virtual camera dynamics, or combinations of these. The injected trajectory signals guide the generative process to produce temporally consistent and semantically aligned motion sequences. Our framework demonstrates superior performance across multiple video motion control tasks, including stylized motion effects (e.g., motion brushes), dynamic viewpoint changes, and precise local motion manipulation. Experiments show that our method provides significantly better controllability and visual quality compared to prior approaches and commercial solutions, while remaining broadly compatible with various state-of-the-art video generation backbones. Project page: https://anytraj.github.io/.
CINEMA: Coherent Multi-Subject Video Generation via MLLM-Based Guidance
Mar 13, 2025Video generation has witnessed remarkable progress with the advent of deep generative models, particularly diffusion models. While existing methods excel in generating high-quality videos from text prompts or single images, personalized multi-subject video generation remains a largely unexplored challenge. This task involves synthesizing videos that incorporate multiple distinct subjects, each defined by separate reference images, while ensuring temporal and spatial consistency. Current approaches primarily rely on mapping subject images to keywords in text prompts, which introduces ambiguity and limits their ability to model subject relationships effectively. In this paper, we propose CINEMA, a novel framework for coherent multi-subject video generation by leveraging Multimodal Large Language Model (MLLM). Our approach eliminates the need for explicit correspondences between subject images and text entities, mitigating ambiguity and reducing annotation effort. By leveraging MLLM to interpret subject relationships, our method facilitates scalability, enabling the use of large and diverse datasets for training. Furthermore, our framework can be conditioned on varying numbers of subjects, offering greater flexibility in personalized content creation. Through extensive evaluations, we demonstrate that our approach significantly improves subject consistency, and overall video coherence, paving the way for advanced applications in storytelling, interactive media, and personalized video generation.
Deployment Prior Injection for Run-time Calibratable Object Detection
Feb 27, 2024



With a strong alignment between the training and test distributions, object relation as a context prior facilitates object detection. Yet, it turns into a harmful but inevitable training set bias upon test distributions that shift differently across space and time. Nevertheless, the existing detectors cannot incorporate deployment context prior during the test phase without parameter update. Such kind of capability requires the model to explicitly learn disentangled representations with respect to context prior. To achieve this, we introduce an additional graph input to the detector, where the graph represents the deployment context prior, and its edge values represent object relations. Then, the detector behavior is trained to bound to the graph with a modified training objective. As a result, during the test phase, any suitable deployment context prior can be injected into the detector via graph edits, hence calibrating, or "re-biasing" the detector towards the given prior at run-time without parameter update. Even if the deployment prior is unknown, the detector can self-calibrate using deployment prior approximated using its own predictions. Comprehensive experimental results on the COCO dataset, as well as cross-dataset testing on the Objects365 dataset, demonstrate the effectiveness of the run-time calibratable detector.
UGG: Unified Generative Grasping
Nov 28, 2023Dexterous grasping aims to produce diverse grasping postures with a high grasping success rate. Regression-based methods that directly predict grasping parameters given the object may achieve a high success rate but often lack diversity. Generation-based methods that generate grasping postures conditioned on the object can often produce diverse grasping, but they are insufficient for high grasping success due to lack of discriminative information. To mitigate, we introduce a unified diffusion-based dexterous grasp generation model, dubbed the name UGG, which operates within the object point cloud and hand parameter spaces. Our all-transformer architecture unifies the information from the object, the hand, and the contacts, introducing a novel representation of contact points for improved contact modeling. The flexibility and quality of our model enable the integration of a lightweight discriminator, benefiting from simulated discriminative data, which pushes for a high success rate while preserving high diversity. Beyond grasp generation, our model can also generate objects based on hand information, offering valuable insights into object design and studying how the generative model perceives objects. Our model achieves state-of-the-art dexterous grasping on the large-scale DexGraspNet dataset while facilitating human-centric object design, marking a significant advancement in dexterous grasping research. Our project page is https://jiaxin-lu.github.io/ugg/ .
Deep Graph Reprogramming
Apr 28, 2023



In this paper, we explore a novel model reusing task tailored for graph neural networks (GNNs), termed as "deep graph reprogramming". We strive to reprogram a pre-trained GNN, without amending raw node features nor model parameters, to handle a bunch of cross-level downstream tasks in various domains. To this end, we propose an innovative Data Reprogramming paradigm alongside a Model Reprogramming paradigm. The former one aims to address the challenge of diversified graph feature dimensions for various tasks on the input side, while the latter alleviates the dilemma of fixed per-task-per-model behavior on the model side. For data reprogramming, we specifically devise an elaborated Meta-FeatPadding method to deal with heterogeneous input dimensions, and also develop a transductive Edge-Slimming as well as an inductive Meta-GraPadding approach for diverse homogenous samples. Meanwhile, for model reprogramming, we propose a novel task-adaptive Reprogrammable-Aggregator, to endow the frozen model with larger expressive capacities in handling cross-domain tasks. Experiments on fourteen datasets across node/graph classification/regression, 3D object recognition, and distributed action recognition, demonstrate that the proposed methods yield gratifying results, on par with those by re-training from scratch.
Learning Graph Neural Networks for Image Style Transfer
Jul 24, 2022
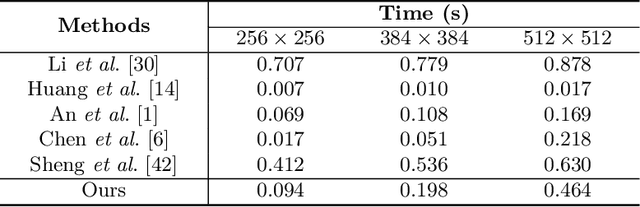
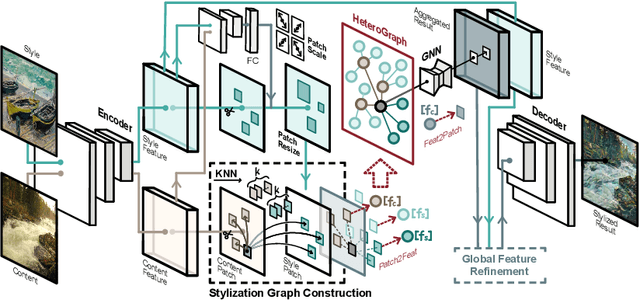

State-of-the-art parametric and non-parametric style transfer approaches are prone to either distorted local style patterns due to global statistics alignment, or unpleasing artifacts resulting from patch mismatching. In this paper, we study a novel semi-parametric neural style transfer framework that alleviates the deficiency of both parametric and non-parametric stylization. The core idea of our approach is to establish accurate and fine-grained content-style correspondences using graph neural networks (GNNs). To this end, we develop an elaborated GNN model with content and style local patches as the graph vertices. The style transfer procedure is then modeled as the attention-based heterogeneous message passing between the style and content nodes in a learnable manner, leading to adaptive many-to-one style-content correlations at the local patch level. In addition, an elaborated deformable graph convolutional operation is introduced for cross-scale style-content matching. Experimental results demonstrate that the proposed semi-parametric image stylization approach yields encouraging results on the challenging style patterns, preserving both global appearance and exquisite details. Furthermore, by controlling the number of edges at the inference stage, the proposed method also triggers novel functionalities like diversified patch-based stylization with a single model.
Meta-Aggregator: Learning to Aggregate for 1-bit Graph Neural Networks
Sep 27, 2021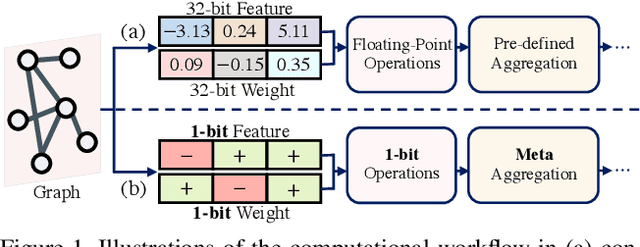

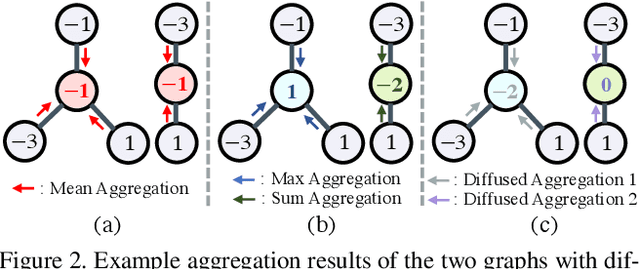
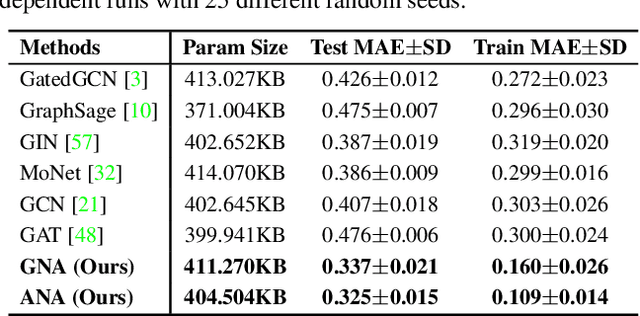
In this paper, we study a novel meta aggregation scheme towards binarizing graph neural networks (GNNs). We begin by developing a vanilla 1-bit GNN framework that binarizes both the GNN parameters and the graph features. Despite the lightweight architecture, we observed that this vanilla framework suffered from insufficient discriminative power in distinguishing graph topologies, leading to a dramatic drop in performance. This discovery motivates us to devise meta aggregators to improve the expressive power of vanilla binarized GNNs, of which the aggregation schemes can be adaptively changed in a learnable manner based on the binarized features. Towards this end, we propose two dedicated forms of meta neighborhood aggregators, an exclusive meta aggregator termed as Greedy Gumbel Neighborhood Aggregator (GNA), and a diffused meta aggregator termed as Adaptable Hybrid Neighborhood Aggregator (ANA). GNA learns to exclusively pick one single optimal aggregator from a pool of candidates, while ANA learns a hybrid aggregation behavior to simultaneously retain the benefits of several individual aggregators. Furthermore, the proposed meta aggregators may readily serve as a generic plugin module into existing full-precision GNNs. Experiments across various domains demonstrate that the proposed method yields results superior to the state of the art.